Download as PDF, PPTX



















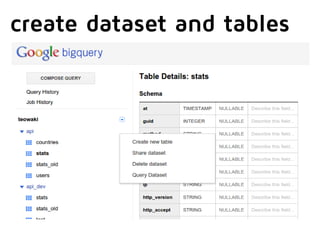



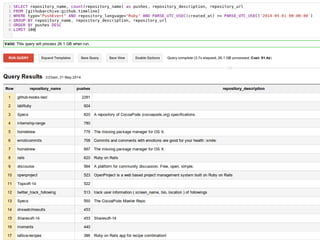
![Things you always wanted to
try but were too scared to
select count(*) from
publicdata:samples.wikipedia
where REGEXP_MATCH(title, "[0-9]*")
AND wp_namespace = 0;
223,163,387
Query complete (5.6s elapsed, 9.13 GB processed, Cost: 32¢)
javier ramirez @supercoco9 https://teowaki.com](https://image.slidesharecdn.com/spanconfgooglebigquery-141028055907-conversion-gate02/85/Big-Data-Analytics-with-Google-BigQuery-by-Javier-Ramirez-datawaki-at-Span-Conf-26-320.jpg)

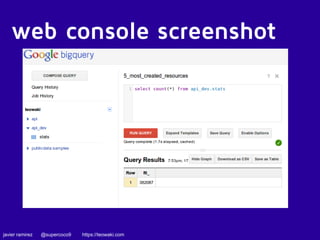
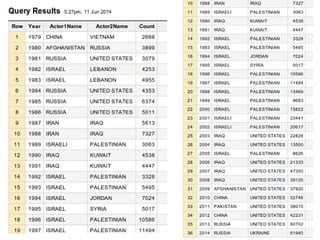
![SELECT Year, Actor1Name, Actor2Name, Count FROM (
SELECT Actor1Name, Actor2Name, Year,
COUNT(*) Count, RANK() OVER(PARTITION BY YEAR ORDER BY
Count DESC) rank
FROM
(SELECT Actor1Name, Actor2Name, Year FROM
[gdelt-bq:full.events] WHERE Actor1Name < Actor2Name
and Actor1CountryCode != '' and Actor2CountryCode != ''
and Actor1CountryCode!=Actor2CountryCode),
(SELECT Actor2Name Actor1Name, Actor1Name Actor2Name,
Year FROM [gdelt-bq:full.events] WHERE
Actor1Name > Actor2Name and Actor1CountryCode != '' and
Actor2CountryCode != '' and
Actor1CountryCode!=Actor2CountryCode),
WHERE Actor1Name IS NOT null
AND Actor2Name IS NOT null
GROUP EACH BY 1, 2, 3
HAVING Count > 100
)
WHERE rank=1
ORDER BY Year](https://image.slidesharecdn.com/spanconfgooglebigquery-141028055907-conversion-gate02/85/Big-Data-Analytics-with-Google-BigQuery-by-Javier-Ramirez-datawaki-at-Span-Conf-29-320.jpg)
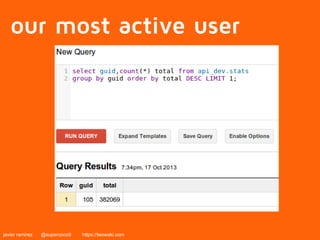
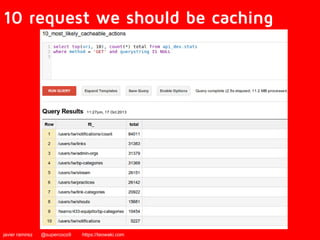









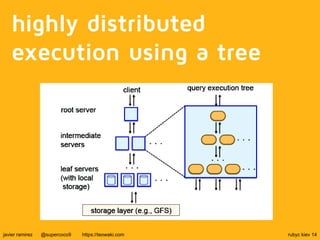
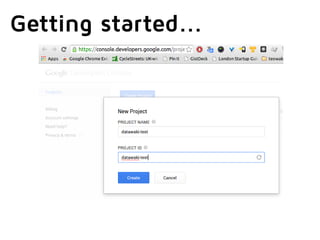
The document discusses Google's BigQuery as a solution for big data analytics, highlighting its speed and efficiency in processing large datasets through its Dremel technology. It mentions the benefits of using BigQuery for interactive queries and data analysis, while also noting its cost and non-open source nature. Applications include analyzing web documents, tracking app installs, and evaluating historical event data.


































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

















