Downloaded 61 times







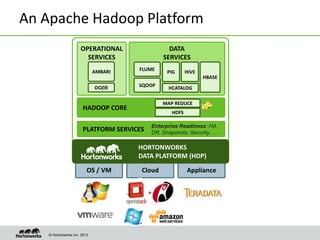
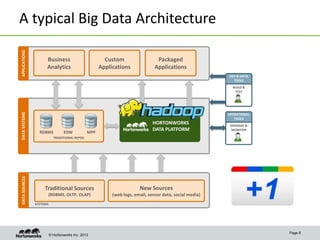


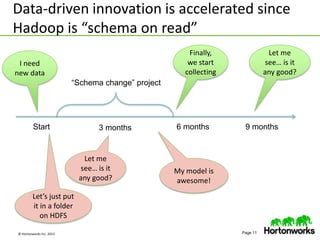
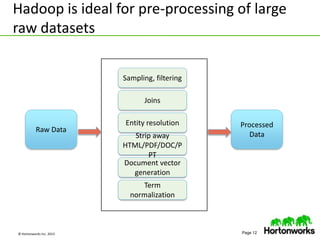



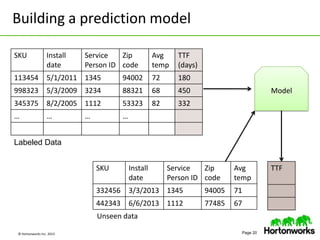










This document discusses data science with Hadoop. It begins by defining data science and a data scientist. It then explains how Hadoop can help reduce the time and cost of building large-scale data products by co-locating computation and data. Several use cases are presented that demonstrate how Hadoop can be used for tasks like product recommendation, failure prediction, and anomaly detection for security applications. The document concludes by advising readers to start with a proof-of-value use case and build a cross-functional team when getting started with data science on Hadoop.


































































