Download to read offline
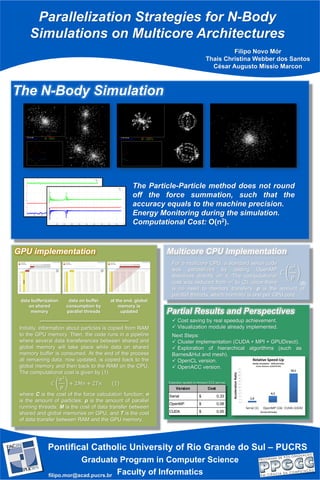
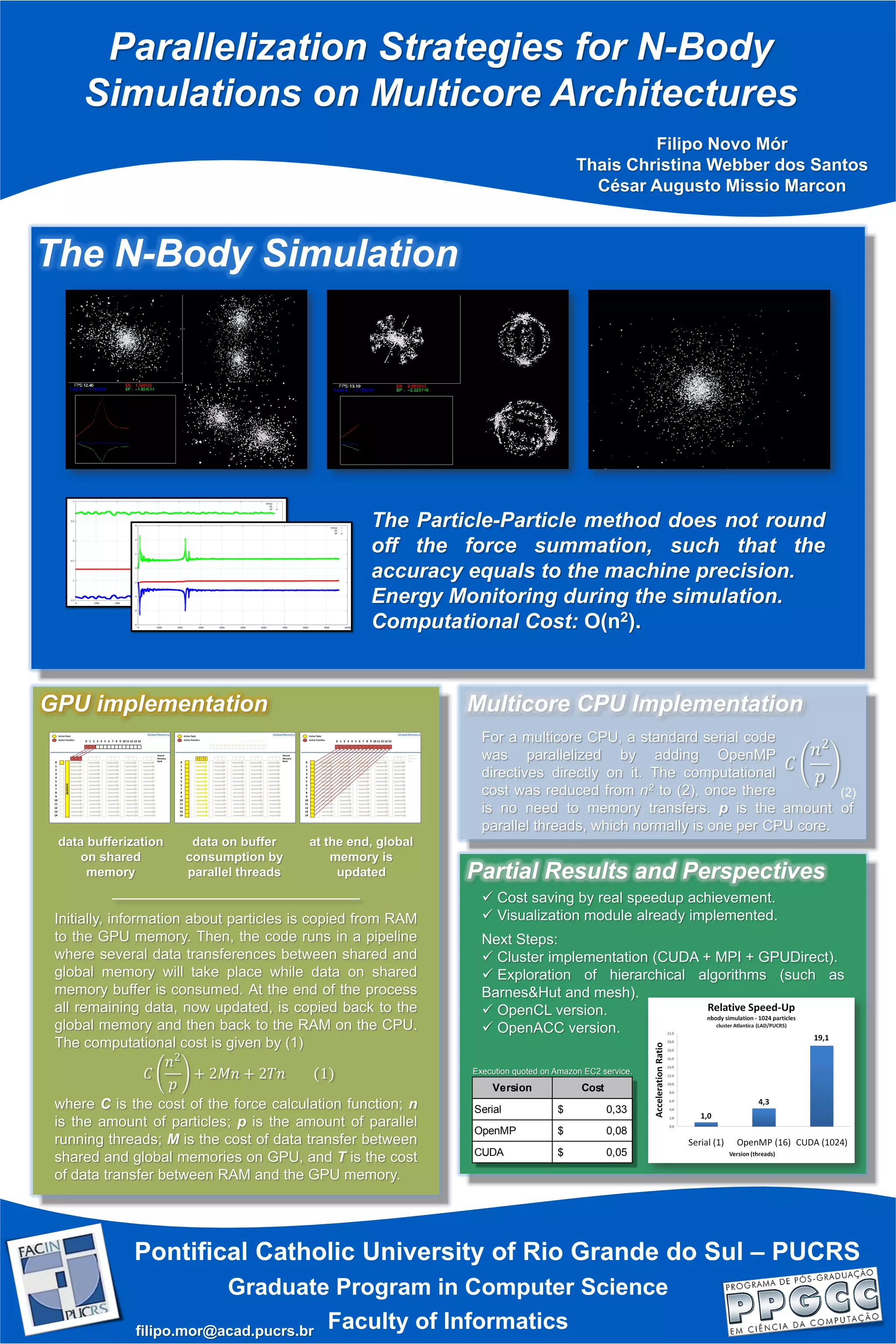

This document discusses parallelization strategies for N-body simulations on multicore architectures. It describes GPU and multicore CPU implementations of an N-body simulation algorithm. For the GPU implementation, data is transferred between global GPU memory and shared memory buffers while computation is performed in parallel. For the multicore CPU implementation, the serial code was parallelized with OpenMP directives to distribute work across CPU cores without data transfers. Computational costs and speedups of the different approaches are analyzed.























































































