Download to read offline
![DECENTRALIZED SYSTEMS PROJECT. MAY 2012 1
High Availability of Services in Wide-Area Shared
Computing Networks
M´rio Almeida (mario.almeida@est.fib.upc.edu), EMDC Student
a
Ozgur Seyhanli (ozgur.seyhanli@est.fib.upc.edu), CANS Student
Sergio Mendoza (sergio.mendoza@est.fib.upc.edu), CANS Student
Zafar Gilani (syed.zafar.ul.hussan.gilani@est.fib.upc.edu), EMDC Student
Abstract—Highly available distributed systems have been level of operational performance will be met during a con-
widely used and have proven to be resistant to a wide range tractual measurement period.
of faults. Although these kind of services are easy to access,
they require an investment that developers might not always Availability is related to the ability of the user to access
be willing to make. We present an overview of Wide-Area the system. If a user is unable to access it then it is said
shared computing networks as well as methods to provide to be unavailable. The period in which the system is un-
high availability of services in such networks. We make some
references to highly available systems that are being used
available is called downtime. Unscheduled downtime can
and studied at the moment this paper was written. be due to multiple causes such as power outages, hardware
Index Terms—High Availability, Wide-Area Networks, failures, security breaches or application/OS failures.
Replication, Quorum Consistency, Descentralized Systems, As stated in the CAP theorem [1], a distributed com-
File virtualization, Load balancing, Migration of Services puter system has to decide which two of these three prop-
erties will be provided : Consistency, Availability and Par-
I. Introduction tition tolerance. This formulation tends to oversimplify
the tensions between properties since there is the need to
H IGHLY available distributed systems have been
widely used and have proven to be resistant to a wide
range of faults, like power outages, hardware failures, secu-
choose between consistency and availability when there are
partitions. Recent distributed systems [22] show that there
rity breaches, application failures, OS failures and even to is a lot of flexibility for handling partitions and recovering,
byzantine faults. For example, services like Amazon Elas- even for highly available and somewhat consistent systems.
tic Compute Cloud provide resizable computation capacity As an example of different distributed systems, one can
in the cloud with an annual uptime percentage of 99.95%. think of the NoSQL movement that focus on availability
Although these kind of services are easy to access, they first and consistency second, while the databases that pro-
require an investment that developers might not always vide ACID properties focus more on consistency.
be willing to make. Also some distributed systems have Availability is usually expressed as a percentage of up-
specific properties that make more sense when applied to time in a year. Services generally provide service level
shared non-dedicated computing networks. An example agreements (SLA) that refer to a contract on the mini-
can consist of a file sharing peer-to-peer network, in which mum monthly downtime or availability. For example, ser-
the developers might not want to be held responsible for vices like Amazon Elastic Compute Cloud provide resizable
the contents being shared. computation capacity in the cloud with an annual uptime
In this report we present an overview of Wide-Area percentage of 99.95% [25]. This SLA agreements gener-
shared computing networks as well as methods to provide ally have a backdrop since they generally cover the core
high availability of services in such networks. We make instances and not the services on which the instances de-
some references to highly available systems that are being pend. This was a big issue during EC2s Easter outage in
used and studied at the moment this paper was written. 2011 [26].
As downtimes in distributed systems generally occur due
II. Wide-Area Shared Computing Networks to faults, we will focus on a specific type of fault that is
A Wide-Area shared computing network is an hetero- depicted by the Byzantine Generals Problem [8].
geneous non-dedicated computer network. In these types
of networks, machines have varying and limited resources A. Byzantine faults
and can fail at anytime. Also, theyre often not properly A Byzantine fault is an arbitrary fault that occurs dur-
designed to deal with machine failures and so it makes the ing the execution of an algorithm by a distributed system.
challenge of having no planned downtimes or maintenance It can describe omission failures (crashes, lost communi-
intervals even harder. These types of networks can be sim- cation...) and commission failures (incorrect processing,
ulated using PlanetLab testbed. corrupt states or incorrect responses...). If a system is
not tolerant to byzantine faults it might respond in unpre-
III. High Availability of Services dictable ways.
High availability is a system design approach and asso- Some techniques have been widely used since the paper
ciated service implementation that ensures a prearranged [8] that was published in 1999. Some open-source solu-](https://image.slidesharecdn.com/hainwan-final-120506172135-phpapp02/75/High-Availability-of-Services-in-Wide-Area-Shared-Computing-Networks-1-2048.jpg)
![2 DECENTRALIZED SYSTEMS PROJECT. MAY 2012
tions like UpRight provide byzantine fault tolerance using
a Paxos-like consensus algorithm.
B. High Availability in Wide-Area Networks
Usually high availability clusters provide a set of tech-
niques in order to make the infrastructure as reliable as
possible. Some techniques include disk mirroring, redun-
dant network connections, redundant storage area network
and redundant power inputs on different circuits. In the
case of Wide-Area networks, only a few of these techniques
can be used since it relies on heterogeneous machines that
arent designed specifically for providing high availability.
As the main property of this type of networks is the het-
erogeneity of nodes and its varying resources, it is crucial
to scale its capacities depending on the incoming requests
or actual resources available to the node. Due to the lim-
itations of resources, it is important to be able to scale
Fig. 1. Diagram of active replication architecture.
the service to more nodes. This is one of the key points
of availability of services, since if a node receives more re-
quests than it can handle, it will stop being able to provide
the service and therefore wont have high availability. This
means that a service needs to do load balancing and some-
times partition data or state in several machines in order
to scale. Scaling the number of machines also increases
the probability of some machines to fail. This can be ad-
dressed by creating redundancy by means of replication to
tolerate failures.
C. Load balancing
Load balancing consists of a methodology to distribute
workload across multiple machines in order to achieve op-
timal resource utilization, maximize throughput, minimize
response time and avoid overloading. A simple solution
can be achieved through a domain name system, by asso-
ciating multiple IP addresses with a single domain name.
In order to determine how to balance the workload, the Fig. 2. Diagram of passive replication architecture.
load balancer can also have other characteristics in account
such as reported server load, recent response times, keeping
track of alive nodes, number of connections, traffic and of replicas also has an impact on the performance and
geographic location. complexity of the system. For example, higher number of
The load balancing can be done at two levels: at the replicas imply more messages to keep consistency between
tracking of services at system level and at the node level. them.
At the node level this load balancing can be achieved by Replication is important not only to create the needed
either redirecting requests or redirecting clients. Also, the redundancy to handle failures but also to balance the work-
nodes could send tokens to each other in order to estimate load by distributing the client requests to the nodes de-
how much requests they can redirect to each other. pending on their capacities.
When we talk about replication two simple schemes
D. Replication of Services come to our mind, active and passive replication [11]. The
To explain how replicating a service can help it tolerate architectures of active and passive replication models are
failures, let’s consider the probability of failure of a sin- represented, respectively, in Figure 1 and Figure 2.
gle machine to be P and that machines fail independently. In active replication each request is processed by all the
Then if we replicate data N times to survive N-1 failures, nodes. This requires that the process hosted by the nodes
of replicas the probability of losing a specific data must be is deterministic, meaning that having the same initial state
P N . A desired reliability R can be picked by changing the and the same request sequence, all processes should pro-
number so that P N < R. duce the same response and achieve the same final state.
So we can provide smaller probabilities of having down- This also introduces the need of atomic broadcast proto-
times of services by increasing the number of replicas. But cols that guarantee that either all the replicas receive the
this is not as easy as it seems as the increasing number message in the same order or none receives it.](https://image.slidesharecdn.com/hainwan-final-120506172135-phpapp02/75/High-Availability-of-Services-in-Wide-Area-Shared-Computing-Networks-2-2048.jpg)
![ALMEIDA, SEYHANLI, MENDOZA AND GILANI: H. AVAILABILITY OF SERVICES IN W-A SHARED CNS 3
In passive replication there is a primary node that pro- This solution highly depends on the amount of data that
cesses client requests. After processing the request the the service manages.
node replicates its state to the other backup nodes and A common way to simplify the access to remote files in a
sends back the response to the client. If the primary node transparent way is to perform file virtualization. File vir-
fails, there is a leader election and one of the backups takes tualization eliminates the dependencies between the data
its place as primary. accessed at the file level and the location where the files
In regular passive replication, secondary replicas should are physically stored. It allows the optimization of storage
only perform reads, while the writes are performed by the use and server consolidation and to perform non-disruptive
primary replica and then replicated to the other replicas. file migrations.
There could be better workload balancing if every node Caching of data can be done in order to improve its per-
could receive requests but this also implies using another formance. Also there can be a single management interface
system to keep consistency between nodes. Also caching of for all the distributed virtualized storage systems. It allows
reads can greatly improve the overall performance of the replication services across multiple heterogeneous devices.
system but one may have to relax consistency properties The data replication can also be done in an hybrid way,
to achieve this. storing less important content in the heterogeneous nodes
For passive replication, papers like A Robust and and more important content in a more reliable distributed
Lightweight Stable Leader Election Service for Dynamic file system. An example of a somewhat hybrid system can
Systems [3] describe system implementations of fault- be Spotify, it makes use of client replicated files in order
tolerant leader election services that use stochastic failure to offload some work from its servers but when the clients
detectors [10] and link quality estimators to provide some have low throughput or the files arent available, the Spotify
degree of QoS control. These systems adapt to changing servers can provide the files in a more reliable way.
network conditions and has proven to be robust and not Amazon S3 also provides storage options such as the
too expensive. reduced redundancy storage system. This system reduces
Active replication deals better with real time systems the costs by storing non-critical, reproducible data at lower
that require faster responses, even when there are faults. levels of redundancy. It provides a cost-effective, highly
The main disadvantage of active replication is that most available solution for distributing or sharing content that
services are non-deterministic and the disadvantage of pas- is durably stored elsewhere, or for storing thumbnails,
sive replication is that in case of failure the response is transcoded media, or other processed data that can be eas-
delayed. ily reproduced.
Passive replication can be efficient enough if we consider
G. Migration of Services
that the type of services we want to provide perform sig-
nificantly more reads than writes. Serializing all updates Another problem in Wide-Area networks is that node
through a single leader can be a performance bottleneck. resources can vary a lot. This means that although a node
As replication also introduces costs in communication may have proven worth during a period of time, its avail-
and resources, some techniques are generally used to reduce able resources such as CPU, bandwidth or memory can
it. An example is the use of read and write quorum sets vary and affect the service sustainability. Also, if the level
as we will explain in sections ahead. of replication is not aware of the variation of resources of
the nodes, we might see the number of needed replicas to
E. Service Recovery provide a service growing to a point that it affects the per-
formance of the service. Due to this aspect, a new concept
Another important characteristic of this kind of net- has been researched lately that consists of resource-aware
works is that a node can be shutdown at any moment. migration of services [5] between nodes.
Actually some studies show that most failures in Planet-
It might seem that migration is a similar concept to repli-
Lab are due to rebooting the machines, this means that
cation as it consists of replicating the data from one node
node regeneration capabilities would be crucial in such en-
to another. However it is different since it also aims to
vironment. It is noticeable that in this case, re-accessing
transfer the current state of execution in the volatile stor-
the data on the secondary storage instead of creating a
age as well as its archival state in the secondary storage.
new node and performing replication could definitively im-
Moreover it also provides mechanisms for handling any on-
prove the overall performance of the system (for systems
going client-sessions.
that keep states). This can also depend on the average
Migration of services uses migration policies to decide
observed downtime of the machines that will be revisited
when a service should migrate. These policies can be
in the evaluation.
locality-aware and resource-aware For example; available
resources can be CPU, bandwidth, memory and more.
F. Storage replication
Migration of services also introduces some issues such
Wide Area Shared Computing networks arent the most as the need of a tracking system to allow clients to access
propitious type of networks for persistently storing files a location changing service. Also, during this migration
in a highly available way. Since nodes often reboot, the there is a period in which the service might be unable to
easiest way would be to replicate data like the services. attend requests and so it needs to delegate responsibilities](https://image.slidesharecdn.com/hainwan-final-120506172135-phpapp02/75/High-Availability-of-Services-in-Wide-Area-Shared-Computing-Networks-3-2048.jpg)
![4 DECENTRALIZED SYSTEMS PROJECT. MAY 2012
to another replica. This period is called blackout period is therefore important to be able to verify and merge the
and the aim of replication is to make this period negligible. existing versions. This can be achieved by requesting all
Latest research papers such as Building Autonomically existing versions of data from the read quorum, and then
Scalable Services on Wide-Area Shared Computing [4] aim waiting for the responses from all the replicas. If there
to provide models for estimating service capacity that is are multiple versions, it returns all the versions that are
likely to be provided by a replica in the near future . It also causally unrelated. Divergent versions are reconciled and
provides models for dynamic control of the degree of service written to the write quorum.
replication. This is done in order to provision the required Quorums consistency is actually used in a variety of dis-
aggregate service capacity based on the estimated service tributed systems and seem to perform well. An example is
capacities of the replicas. They also describe techniques the quorum consistency of replicas used by Amazons Dy-
to provide reliable registry services for clients to locate namo [12]. Dynamo also manages group membership using
service replicas. Their experimental evaluation shows the a gossip-based protocol to propagate membership changes
importance of this estimations and they claim to be able and maintain an eventually consistent view of membership.
to predict correctness of 95%. One of the other methods of achieving consistency includes
In conclusion, the system performance of this kind of techniques like fuzzy snapshots to perceive the global state
systems is highly dependent on the type of service pro- of the system composed by the replicas.
vided. For services that make intensive use of the sec-
ondary storage, migration is a very costly solution. One IV. Related work
approach could consist of pro-actively select and transfer Commercial approaches for replication have been evolv-
secondary storage to a potential target node for any future ing towards increasing tolerance to fail-stop faults. This
re-locations. is mainly because of falling hardware costs, the fact that
replication techniques become better understood and eas-
H. Quorum Consistency ier to adopt, and systems become larger, more complex,
If we consider services that make large use of secondary and more important.
storage and the properties of Wide-Area shared computing There appears to be increasingly routine use of doubly-
networks such as the frequent shutdown of nodes, then we redundant storage. Similarly, although two-phase commit
must be able to recover these nodes so that we dont have is often good enough, it can be always safe and rarely un-
to replicate the whole data again. If, on other hand, we live, increasing numbers of deployments pay the extra cost
assume that this data is small, then we can simply replicate to use Paxos three-phase commit to simplify their design
the server to a new node. or avoid corner cases requiring operator intervention.
If we consider recovering services, we must have a way Distributed systems increasingly include limited Byzan-
to keep track of the nodes alive and have an efficient way tine fault tolerance aimed at high-risk subsystems. For ex-
to update them instead of copying the whole set of data. ample the ZFS [17], GFS [18], and HDFS [19] file systems
If we consider a small and fix number of nodes, we can provide checksums for on-disk data. As another example,
always do a simple heartbeat/versioning system, but for after Amazon S3 was afected for several hours by a flipped
more dynamic number of replicas, a group membership bit, additional checksums on system state messages were
protocol would probably be more suitable for keeping track added.
of the nodes. Some other systems that we have studied and will in-
In order to perform efficient updates in a dynamic set of clude here are UpRight fault tolerance infrastructure and
replicas, a quorum system can be used to provide consis- Zookeeper coordination service. We have studied many
tency. The main advantage of quorums is that it uses its other systems that we did not list here. Special mention to
quorum sets properties to propagate changes and reduce amazons Dynamo storage system that provides advanced
the needed number of messages. It can reduce the needed techniques like the ones we have mentioned in previous
number of messages to perform a critical action from three chapters.
times the total number of nodes to three times the number
of nodes in its quorum (in the best case). A. UpRight
For example, in the case of passive replication, if the Upright is an open-source infrastructure and library for
primary node needs to perform a write operation, it gen- building fault tolerant distributed systems [20]. It pro-
erates the vector clock for the new data version and per- vides a simple library to ensure high availability and fault
forms the write locally. Then it sends the new version to tolerance through replication. It claims to provide high
the nodes in its quorum, if all the nodes respond then the availability, high reliability (system remains correct even if
write is considered successful. Thanks to quorum proper- byzantine failures are present) and high performance. In
ties, it doesnt need to contact all the backup nodes, only Figure 3 we show the architecture of UpRight.
the nodes present at its quorum set. The latency is deter- As depicted in the previous architecture diagram, the
mined by the slowest node of this write quorum. application client sends its requests through the client li-
As the primary node can also fail and it could hypothet- brary and these requests are ordered by the UpRight Core.
ically (and depending on the design) have the most recent The application servers handle these ordered requests and
version of the data that it didn’t have time to replicate, it send replies back to the clients. The redundancy provided](https://image.slidesharecdn.com/hainwan-final-120506172135-phpapp02/75/High-Availability-of-Services-in-Wide-Area-Shared-Computing-Networks-4-2048.jpg)
![ALMEIDA, SEYHANLI, MENDOZA AND GILANI: H. AVAILABILITY OF SERVICES IN W-A SHARED CNS 5
V. Practical work
A. PlanetLab Overview
PlanetLab [21] is a heterogeneous infrastructure of com-
puting resources shared across the Internet. Established
in 2002, it is a global network of computers available as a
testbed for computer networking and distributed systems
research. In December 2011, PlanetLab was composed of
1024 nodes at 530 sites worldwide.
Accounts are available to people associated with com-
panies and universities that host PlanetLab nodes. Each
Fig. 3. Diagram of Upright architecture. investigation project runs a ”slice”, which gives experi-
menters access to a virtual machine on each node attached
to that slice.
by the UpRight replication engine guarantees that even if a Several efforts to improve the heterogeneity of PlanetLab
given number of nodes are down, faulty, or even malicious, have been made. OneLab, an European Project funded by
the whole system can still work correctly. the European Commission, started in September 2006 with
UpRight also uses some of the properties that we de- two overarching objectives: Extend the current PlanetLab
scribed in previous chapters, such as the use of quorums. infrastructure and Create an autonomous PlanetLab Eu-
Its purpose is to optimistically send messages to the min- rope
imum number of nodes and resend to more nodes only if PlanetLab Europe is a European-wide research testbed
the observed progress is slow. It also provides byzantine that is linked to the global PlanetLab through a peer-to-
fault tolerance using a Paxos-like consensus algorithm. peer federation. During this Project different kinds of ac-
cess technologies (such as UMTS, WiMax and WiFi) were
B. Zookeeper integrated, allowing the installation of new kinds of multi-
Zookeeper [16] is an open-source coordination service homed PlanetLab nodes (e.g. nodes with an Ethernet plus
that has some similarities to Chubby [15]. It provides ser- a interface) [23].
vices like consensus, group management, leader election, Since 2008, hundreds researchers at top academic insti-
presence protocols, and consistent storage for small files. tutions and industrial research labs have tested their exper-
Zookeeper guards against omission failures. However, imental technologies on PlanetLab Europe, including: dis-
because a data center typically runs a single instance of a tributed storage, network mapping, peer-to-peer systems,
coordination service on which many cluster services de- distributed hash tables, and query processing. As of Jan-
pend, and because even a small control error can have uary 2012, PlanetLab Europe has 306 nodes at 152 sites.
dramatic effects, it seems reasonable to invest additional
B. PlanetLab Setup
resources to protect against a wider range of faults.
Considering u as the total number of failures it can tol- For using PlanetLab infrastructure an account is re-
erate and remain live and r the number of those failures quired. To use the resources offered by various nodes, a
that can be commission failures while maintaining safety, slice has to be created. A slice is a collection of resources
Zookeeper deployment comprises 2u + 1 servers. A com- distributed across multiple PlanetLab nodes. When a node
mon configuration is 5 servers for u = 2 r = 0. Servers is added to a slice, a virtual server for that slice is created
maintain a set of hierarchically named objects in memory. on that node. When a node is removed from a slice, that
Writes are serialized via a Paxos-like protocol, and reads virtual server is destroyed. Each sites PI is in charge of
are optimized to avoid consensus where possible. A client creating and managing slices at that site [24].
can set a watch on an object so that it is notified if the In order to measure a few metrics related to availabil-
object changes unless the connection from the client to a ity, we deployed a sample application on PlanetLabs UPC
server breaks, in which case the client is notified that the slice (upcple sd). To run experiments, we added a total of
connection broke. 8 nodes to our slice to create a virtual network over Plan-
For crash tolerance, each server synchronously logs up- etLab. The following table shows hostnames of nodes and
dates to stable storage. Servers periodically produce fuzzy their locations.
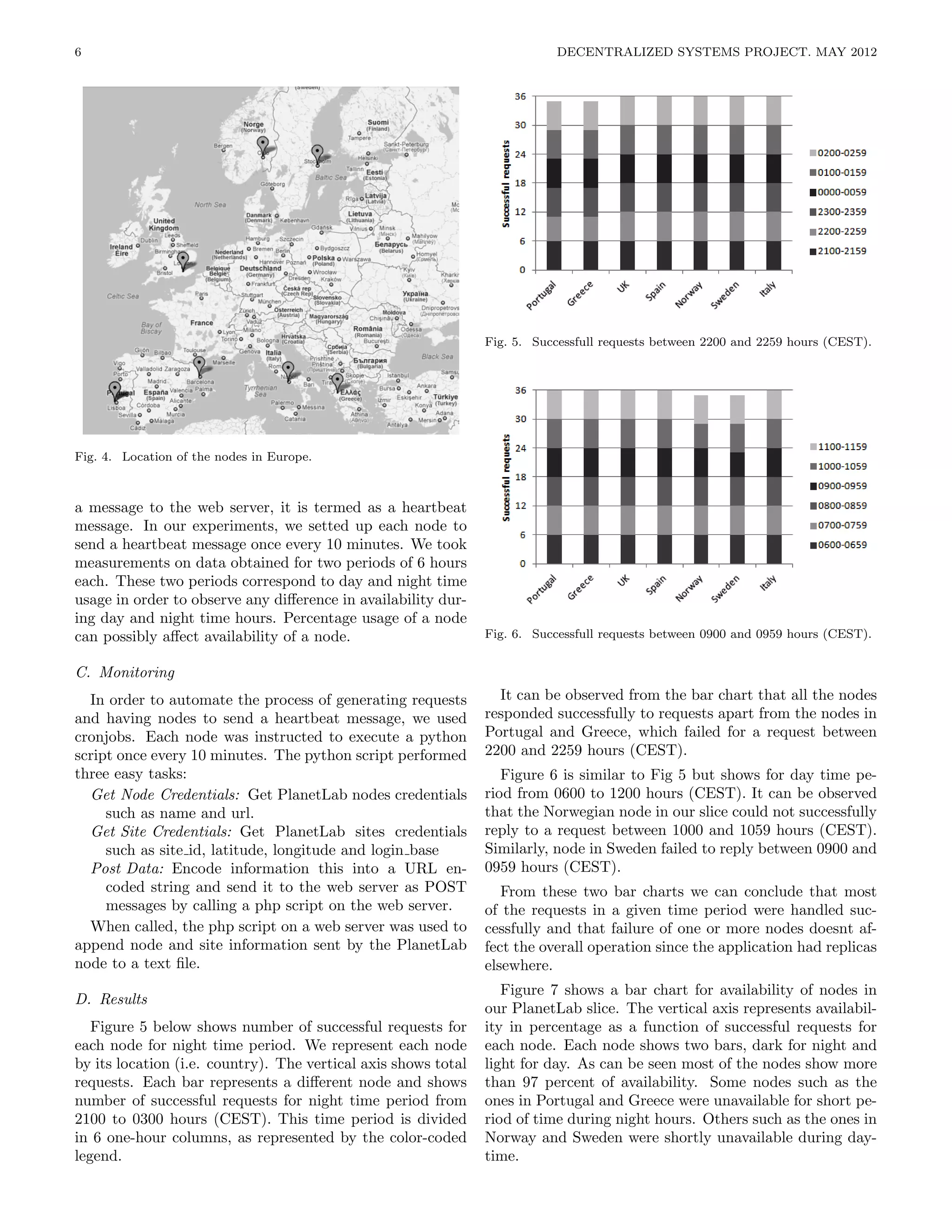
snapshots to checkpoint their state: a thread walks the The map represented in Figure 4 shows the locations of
server’s data structures and writes them to disk, but re- the nodes in Europe.
quests concurrent with snapshot production may alter We deployed a simple application to these nodes to eval-
these data structures as the snapshot is produced. If a uate number of requests generated against time. More im-
Zookeeper server starts producing a snapshot after request portantly we evaluate the availability of nodes against time
Sstart and finishes producing it after request send, the based on number of successful requests.
fuzzy snapshot representing the system’s state after re- Apart from this we also had to set up a web server at
quest send comprises the data structures written to disk IST in Lisbon, Portugal. A web server is necessary for stor-
plus the log of updates from Sstart to send. ing messages from PlanetLab nodes. When a node sends](https://image.slidesharecdn.com/hainwan-final-120506172135-phpapp02/75/High-Availability-of-Services-in-Wide-Area-Shared-Computing-Networks-5-2048.jpg)
![ALMEIDA, SEYHANLI, MENDOZA AND GILANI: H. AVAILABILITY OF SERVICES IN W-A SHARED CNS 7
on PlanetLab. Moreover as mentioned in section E, we
consistently experienced failure of tools such as CoDeploy
and MultiQuery. Ultimately we had to accomplish things
manually.
Also we realized that some of the tools havent been up-
dated for about ten years and some of their dependencies
are already deprecated.
We had to find a host in order to launch our server and
group the results from the PlanetLab nodes. As this host
did not have a fixed IP we had to constantly update our
private/public keys to communicate with the nodes. If
we opted for using PlanetLab tools it would have taken
even longer to evaluate our project since it can take from
Fig. 7. Availability of nodes in our PlanetLab slice. a few minutes to a few hours to commit changes to virtual
machine configurations.
For speeding up the process of development of a highly
E. Issues available distributed system, one can use either Amazons
Standard approach to deploy software and applications EC2 for deploying highly available and resource elastic ser-
on PlanetLab nodes is to use an application called CoDe- vices. As this is not always the most appropriate solu-
ploy. However using CoDeploy [27] was neither convenient tion, one can set up its own network and use, for example,
nor consistent. We observed that for most of the nodes, the the multiple open-source Hadoop technologies for reliable
deployment failed altogether. As a workaround we manu- and scalable distributed systems. But in the case of Wide
ally deployed scripts on PlanetLab nodes. Area Shared Computing networks, maybe solutions like the
Similarly, standard method of registering cronjobs on open-source UpRight are more suitable since it can be inte-
PlanetLab nodes is to use an application called MultiQuery grated either with Zookeeper or with Hadoops distributed
[27] which is a part of CoDeploy application. We found file system.
that even though MultiQuery registers cronjobs, it how- We have concluded that it is possible to provide highly
ever fails to start the crond daemon. As a workaround we available distributed systems in wide area shared comput-
manually registered our cronjobs on PlanetLab nodes. ing through the use of resource-aware replication [5] with
reasonable results. Quorum sets help reducing the costs
VI. Evaluation of Highly Available Systems of replication and the paxos algorithm can help tolerate
The problem with theoretical reliability through replica- byzantine faults.
tion is that it assumes that these failures are indeed inde- Finally, as an experiment we replicated a simple appli-
pendent. If nodes share the same software and there can be cation over a small network of PlanetLab PLE nodes us-
corrupt requests, there is always some correlation between ing active replication methodology. We found that even
failures of nodes (At least WAN networks will less proba- though a few nodes might fail at any given time, the ap-
bly share the same configuration of machines). P N is an plication can still work without major issues.
upper bound of reliability that can never be approached in
practice. This is discussed in papers such as the one from References
Google [4] that shows empirical numbers on group fail- [1] Nancy Lynch and Seth Gilbert, Brewer’s conjecture and the
ures that demonstrates rates of several orders of magnitude feasibility of consistent, available, partition-tolerant web services
ACM SIGACT News, Volume 33 Issue 2, 2002.
higher than the independence assumption would predict. [2] Mamoru Maekawa, Arthur E. Oldehoeft, Rodney R. Oldehoeft
Reliability and high availability should not only be Operating Systems: Advanced Concept. Benjamin/Cummings
proved through theoretical methodologies, it has to be Publishing Company, Inc, 1987.
[3] Nicolas Schiper, Sam Toueg, A Robust and Lightweight Sta-
tested through empirical methods such as continuous hours ble Leader Election Service for Dynamic Systems University of
of successful operations. There are two metrics that are of- Lugano, 2008.
ten difficult to measure on academic research projects but [4] V. Padhye, A. Tripathi, Building Autonomically Scalable Services
on Wide-Area Shared Computing Platforms Network Computing
give a very good measurement of the availability and relia- and Applications (NCA), 10th IEEE International Symposium,
bility of the system, mean time between failures and mean 2011.
time between recoveries. [5] V. Padhye, A. Tripathi, D. Kulkarni, Resource-Aware Migratory
Services in Wide-Area Shared Computing Environments Reliable
Distributed Systems. SRDS 28th IEEE International Symposium,
VII. Conclusion 2009.
We expected to perform further evaluation over Planet- [6] A. Tripathi, V. Padhye, Distributed Systems Research with
Ajanta Mobile Agent Framework 2002.
Lab. However it took more to get an account and to get [7] Benjamin Reed, Flavio P. Junqueira, A simple totally ordered
access to a slice and respective nodes. This was mainly due broadcast protocol LADIS ’08 Proceedings of the 2nd Workshop
to the fact that each of this resources is managed by differ- on Large-Scale Distributed Systems and Middleware, 2008.
[8] Miguel Castro, Barbara Liskov, Practical Byzantine Fault Toler-
ent entities. Once we had an account, we were surprised ance Laboratory for Computer Science, Massachusetts Institute
by the time it takes for virtual machines to get configured of Technology, 1999.](https://image.slidesharecdn.com/hainwan-final-120506172135-phpapp02/75/High-Availability-of-Services-in-Wide-Area-Shared-Computing-Networks-7-2048.jpg)
![8 DECENTRALIZED SYSTEMS PROJECT. MAY 2012
[9] W. Chen, S. Toueg, and M. K. Aguiler, On the quality of
service of failure detector IEEE Transactions on Computers,
51(5):561?580, May 2002.
[10] Jay Kreps - LinkedIn, Getting Real About Distributed System
Reliability NA.
[11] Jaksa, Active and Passive Replication in Distributed Systems
2009.
[12] Werner Vogels, Amazon’s Dynamo 2007.
[13] Joydeep Sen Sarma, Dynamo: A flawed architecture 2009.
[14] A. Rich, ZFS, sun’s cutting-edge le system Technical report,
Sun Microsystems, 2006.
[15] M. Burrows, The Chubby lock service for loosely-coupled dis-
tributed system OSDI, 2006.
[16] Apache, Zookeeper OSDI, 2006.
[17] C. E. Killian, J. W. Anderson, R. Jhala, and A. Vahdat. Life,
death, and the critical transition: Finding liveness bugs in sys-
tems code NSDI, 2007.
[18] A. Clement et al Life, death, and the critical transition: Finding
liveness bugs in systems code NSDI, 2007.
[19] Hadoop, Hadoop NSDI, 2007.
[20] A. Clement et al UpRight Cluster Services SOSP, 2009.
[21] Larry Peterson, Steve Muir, Timothy Roscoe and, Aaron
Klingaman PlanetLab Architecture: An Overview Princeton
University, 2006.
[22] Eric Brewer CAP Twelve Years Later: How the ”Rules” Have
Changed University of California, Berkeley, February 2012.
[23] Giovanni Di Stasi, Stefano Avallone, and Roberto Canonico,
Integration of OMF-Based Testbeds in a Global-Scale Networking
Facility N. Bartolini et al. (Eds.): QShine/AAA-IDEA, 2009.
SOSP, 2009.
[24] PlanetLab, PlanetLab
[25] Amazon, Amazon EC2 Service Level Agreement SOSP, 2008.
[26] Charles Babcock Amazon SLAs Didn’t Cover Major Outage
InformationWeek, 2009.
[27] KyoungSoo Park,Vivek Pai, Larry Peterson and Aki Nakao
Codeploy Princeton.
A
[28] Leslie Lamport, A Document Preparation System: L TEX User’s
Guide and Reference Manual, Addison-Wesley, Reading, MA,
2nd edition, 1994. Be sure to get the updated version for L TEX2ε !
A
[29] Michel Goossens, Frank Mittelbach, and Alexander Samarin,
A
The L TEX Companion, Addison-Wesley, Reading, MA, 1994.](https://image.slidesharecdn.com/hainwan-final-120506172135-phpapp02/75/High-Availability-of-Services-in-Wide-Area-Shared-Computing-Networks-8-2048.jpg)

The document provides an overview of high availability in wide-area shared computing networks, detailing the challenges and methodologies to ensure service reliability amid various potential faults. It discusses techniques such as load balancing, replication, and service recovery to enhance system performance and resilience. Additionally, it addresses concepts like Byzantine fault tolerance and quorum consistency, highlighting their relevance in maintaining service uptime and managing network heterogeneity.














































































