Downloaded 29 times











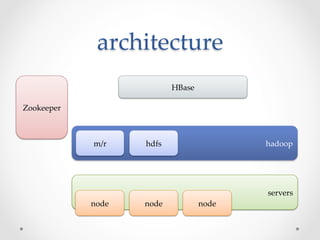

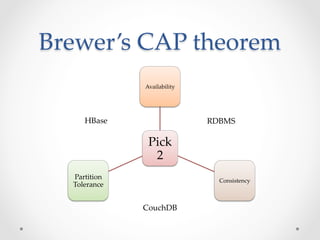
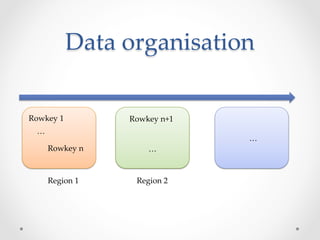
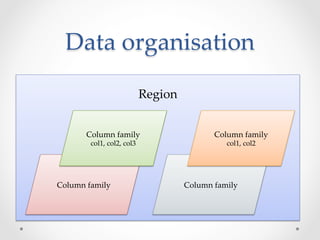
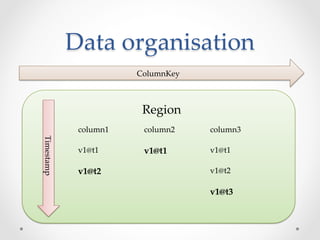









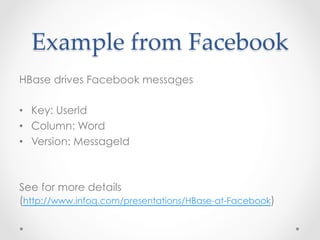





HBase is an open-source, distributed, scalable BigTable-like database built on top of Hadoop that allows for the fast storage and retrieval of large amounts of structured and unstructured data across clusters. It provides a fault-tolerant way of storing large amounts of sparse data and supports real-time read/write access to this data. HBase organizes data into tables divided into rows and columns and is well-suited for applications that benefit from random, real-time read/write access to large datasets.











































































