Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
崇藤
Uploaded by
崇介 藤井
PDF, PPTX
30,747 views
Elasticsearchを使うときの注意点 公開用スライド
Elasticsearchを初めて使うときの注意点をまとめてみました。
Technology
◦
Read more
20
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
Most read
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PPTX
Redisの特徴と活用方法について
by
Yuji Otani
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PPT
Raft
by
Preferred Networks
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
Redisの特徴と活用方法について
by
Yuji Otani
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
Raft
by
Preferred Networks
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
What's hot
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
速習!論理レプリケーション ~基礎から最新動向まで~(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
PPTX
地理分散DBについて
by
Kumazaki Hiroki
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PDF
分散トレーシング技術について(Open tracingやjaeger)
by
NTT Communications Technology Development
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
by
Takuto Wada
PPTX
トランザクションの設計と進化
by
Kumazaki Hiroki
PDF
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PPTX
9/14にリリースされたばかりの新LTS版Java 17、ここ3年間のJavaの変化を知ろう!(Open Source Conference 2021 O...
by
NTT DATA Technology & Innovation
PDF
ソーシャルゲーム案件におけるDB分割のPHP実装
by
infinite_loop
PDF
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Airflow 概要(Airflowの基礎を学ぶハンズオンワークショップ 発表資料)
by
NTT DATA Technology & Innovation
PDF
DockerとPodmanの比較
by
Akihiro Suda
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
速習!論理レプリケーション ~基礎から最新動向まで~(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
地理分散DBについて
by
Kumazaki Hiroki
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
分散トレーシング技術について(Open tracingやjaeger)
by
NTT Communications Technology Development
分散システムについて語らせてくれ
by
Kumazaki Hiroki
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
by
Takuto Wada
トランザクションの設計と進化
by
Kumazaki Hiroki
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
9/14にリリースされたばかりの新LTS版Java 17、ここ3年間のJavaの変化を知ろう!(Open Source Conference 2021 O...
by
NTT DATA Technology & Innovation
ソーシャルゲーム案件におけるDB分割のPHP実装
by
infinite_loop
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Apache Airflow 概要(Airflowの基礎を学ぶハンズオンワークショップ 発表資料)
by
NTT DATA Technology & Innovation
DockerとPodmanの比較
by
Akihiro Suda
Similar to Elasticsearchを使うときの注意点 公開用スライド
PDF
Integrating elasticsearch with asp dot net core
by
Shotaro Suzuki
PDF
ElasticSearch勉強会 第6回
by
Naoyuki Yamada
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
PDF
Renewed using elasticsearchonaspnet-core5
by
Shotaro Suzuki
PDF
Elastic circle ci-co-webinar-20210127
by
Shotaro Suzuki
PDF
Elastic 7.13-new-features-20210624
by
Shotaro Suzuki
PPTX
Elasticsearchインデクシングのパフォーマンスを測ってみた
by
Ryoji Kurosawa
PDF
Elasticsearch at CrowdWorks
by
佑介 九岡
PDF
Learn, build, and scale with elastic - realizing great programming experience...
by
Shotaro Suzuki
PDF
実践!Elasticsearch + Sudachi を用いた全文検索エンジン
by
S. T.
PDF
Building modernapplicationwithelasiccloud
by
Shotaro Suzuki
PDF
20200324 ms open-tech-elastic
by
Koji Kawamura
PDF
ElasticSearchでいろいろやってる話
by
Shinya Takara
PDF
Introducing Elastic 8.1 Release - More Integration, Faster Indexing Speed, Lo...
by
Shotaro Suzuki
PPTX
検索のダウンタイム0でバックアップからindexをリストアする方法
by
kbigwheel
PDF
Elasticsearch勉強会
by
takahito takabayashi
PDF
Introducing the new features of the Elastic 8.6 release.pdf
by
Shotaro Suzuki
PDF
What's New in the Elastic 8.4 Release
by
Shotaro Suzuki
PDF
aws blackbelt amazon elasticsearch service
by
Amazon Web Services Japan
PDF
Utilizing elasticcloudforallusecases
by
Shotaro Suzuki
Integrating elasticsearch with asp dot net core
by
Shotaro Suzuki
ElasticSearch勉強会 第6回
by
Naoyuki Yamada
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
Renewed using elasticsearchonaspnet-core5
by
Shotaro Suzuki
Elastic circle ci-co-webinar-20210127
by
Shotaro Suzuki
Elastic 7.13-new-features-20210624
by
Shotaro Suzuki
Elasticsearchインデクシングのパフォーマンスを測ってみた
by
Ryoji Kurosawa
Elasticsearch at CrowdWorks
by
佑介 九岡
Learn, build, and scale with elastic - realizing great programming experience...
by
Shotaro Suzuki
実践!Elasticsearch + Sudachi を用いた全文検索エンジン
by
S. T.
Building modernapplicationwithelasiccloud
by
Shotaro Suzuki
20200324 ms open-tech-elastic
by
Koji Kawamura
ElasticSearchでいろいろやってる話
by
Shinya Takara
Introducing Elastic 8.1 Release - More Integration, Faster Indexing Speed, Lo...
by
Shotaro Suzuki
検索のダウンタイム0でバックアップからindexをリストアする方法
by
kbigwheel
Elasticsearch勉強会
by
takahito takabayashi
Introducing the new features of the Elastic 8.6 release.pdf
by
Shotaro Suzuki
What's New in the Elastic 8.4 Release
by
Shotaro Suzuki
aws blackbelt amazon elasticsearch service
by
Amazon Web Services Japan
Utilizing elasticcloudforallusecases
by
Shotaro Suzuki
More from 崇介 藤井
PDF
星野リゾートにおけるインフラ内製化の試行錯誤について~AWSの導入の歴史から組織拡大について
by
崇介 藤井
PDF
チームを作る中で経験した自律的に成長するチームの作り方
by
崇介 藤井
PDF
みんなが初心者だからいい。全員で動く、アジャイルチームの成長日誌
by
崇介 藤井
PDF
非ITの宿泊業なのに、なぜDXを推進できるのか?
by
崇介 藤井
PDF
僕があるいた内製化の3年間
by
崇介 藤井
PDF
コロナ禍における宿泊業の苦闘~ピンチをチャンスに変えた開発戦略
by
崇介 藤井
PDF
コロナ禍に躍進した星野リゾートのIT戦略 ~コストカットと事業拡大を両立するAWS活用術~
by
崇介 藤井
PDF
旅館運営企業で実現した現場出身者の力を活かしたアジャイル開発
by
崇介 藤井
PDF
ピンチはチャンス!大逆境のコロナ期での現場とエンジニアの戦い
by
崇介 藤井
PDF
コロナで大打撃を受けた宿泊業のエンジニアの逆境との闘い
by
崇介 藤井
PDF
旅館運営企業にエンジニアがもたらした価値とこれからの戦いについて
by
崇介 藤井
PDF
創業105年の旅館運営企業が実現した 毎週リリースするチームの作り方
by
崇介 藤井
PPTX
20191129 kyoto lt_up
by
崇介 藤井
PPTX
ホテル・旅館運営企業が 毎週リリースするDevOpsサイクルを作るまでの道のり
by
崇介 藤井
PDF
システムを毎週リリースするために頑張ったこと
by
崇介 藤井
星野リゾートにおけるインフラ内製化の試行錯誤について~AWSの導入の歴史から組織拡大について
by
崇介 藤井
チームを作る中で経験した自律的に成長するチームの作り方
by
崇介 藤井
みんなが初心者だからいい。全員で動く、アジャイルチームの成長日誌
by
崇介 藤井
非ITの宿泊業なのに、なぜDXを推進できるのか?
by
崇介 藤井
僕があるいた内製化の3年間
by
崇介 藤井
コロナ禍における宿泊業の苦闘~ピンチをチャンスに変えた開発戦略
by
崇介 藤井
コロナ禍に躍進した星野リゾートのIT戦略 ~コストカットと事業拡大を両立するAWS活用術~
by
崇介 藤井
旅館運営企業で実現した現場出身者の力を活かしたアジャイル開発
by
崇介 藤井
ピンチはチャンス!大逆境のコロナ期での現場とエンジニアの戦い
by
崇介 藤井
コロナで大打撃を受けた宿泊業のエンジニアの逆境との闘い
by
崇介 藤井
旅館運営企業にエンジニアがもたらした価値とこれからの戦いについて
by
崇介 藤井
創業105年の旅館運営企業が実現した 毎週リリースするチームの作り方
by
崇介 藤井
20191129 kyoto lt_up
by
崇介 藤井
ホテル・旅館運営企業が 毎週リリースするDevOpsサイクルを作るまでの道のり
by
崇介 藤井
システムを毎週リリースするために頑張ったこと
by
崇介 藤井
Elasticsearchを使うときの注意点 公開用スライド
1.
© Acroquest Technology
Co., Ltd. All rights reserved. Elasticsearchを使うときの注意点 Acroquest Technology株式会社 2016/01/28 藤井 崇介
2.
© Acroquest Technology
Co., Ltd. All rights reserved.2 はじめに 社内でElasticsearchを使う機会が増えています。 一方で、こんな問題に遭うこともあります。 1. しばらく使っていると、OOMEが発生して落ちてしまう。 2. Elasticsearchが落ちていたせいで、データの復旧が必 要になったが、復旧する方法がない。 3. 想像していたほど性能が出ない。 4. どういうスペックのマシンを用意すればいいかわからな い? Elasticsearchの性能を引き出し、安定稼働させるためには 適切なチューニングを行う必要があります。 このスライドでは、仕事で適用して体験したことや 調査したことを共有したいと思います。 はじめに
3.
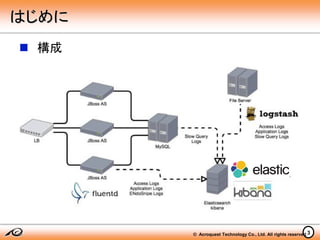
© Acroquest Technology
Co., Ltd. All rights reserved.3 構成 はじめに
4.
© Acroquest Technology
Co., Ltd. All rights reserved. Elasticsearchを使うときの注意点 4
5.
© Acroquest Technology
Co., Ltd. All rights reserved. Elasticsearchを使うときの注意点 1. 2.X系を使うと安定度が増す 2. ヒープメモリを正しく設定する 3. シャード数を適切に設定する 4. データの復旧方法を確保する 5. stringをnot analyzedにできないか検討する 6. bulkAPIを使うときには設定を変える 5
6.
© Acroquest Technology
Co., Ltd. All rights reserved.6 1. 2.X系を使うと安定度が増す 1.X系では、ヒープメモリを大量に消費する。 導入当初は、2か月に1回ElasticsearchがOOMEに より、停止する問題が発生していた。 • 全文検索を効率的に行うため、Luceneが生成したイン デックスから、検索用のインデックスを内部で生成してい る。 • 1.x系ではインデックス情報をJavaのヒープメモリに保持 する方法が使われていたが、2.x系ではファイルを利用 する方法(Doc Values)がデフォルトになった。 Doc Valuesの詳細については以下を参照。 https://www.elastic.co/guide/en/elasticsearch/guide/current/doc-values.html
7.
© Acroquest Technology
Co., Ltd. All rights reserved.7 2. ヒープメモリを正しく設定する Elasticsearchの性能を引き出すためには、メモリ 設定のチューニングは不可欠である。 ヒープメモリを設定するときの注意点 1. 物理メモリの半分以上は指定しない。 – 物理メモリをファイルキャッシュとしてLuceneが利用するため。 2. 30GB以上指定しない。 – Javaのメモリ使用量が32GBを越えるとポインタのサイズが 2倍になり、逆にメモリ消費量が増えるため (Compressed Oopsのため) 3. CMS GCを利用する。G1GCを利用しない。 – G1GCを使うとLuceneの一部で問題が出るらしい(?) 詳細は 未確認。
8.
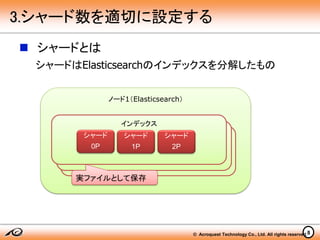
© Acroquest Technology
Co., Ltd. All rights reserved. シャードとは シャードはElasticsearchのインデックスを分解したもの ノード1(Elasticsearch) 8 3.シャード数を適切に設定する インデックス シャード 0P シャード 1P シャード 2P 実ファイルとして保存
9.
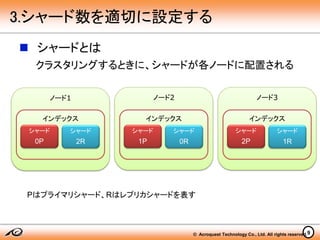
© Acroquest Technology
Co., Ltd. All rights reserved. シャードとは クラスタリングするときに、シャードが各ノードに配置される ノード1 9 3.シャード数を適切に設定する インデックス シャード 0P シャード 2R ノード2 ノード3 インデックス シャード 1P シャード 0R インデックス シャード 2P シャード 1R Pはプライマリシャード、Rはレプリカシャードを表す
10.
© Acroquest Technology
Co., Ltd. All rights reserved. 設定方法 インデックス作成時のみ設定可能 • インデックス作成時に設定する方法 • インデックステンプレートを使う。 10 3.シャード数を適切に設定する curl -XPUT localhost:9200/index-1 '{ "settings" : { "number_of_shards" : 1 } }' curl -XPUT localhost:9200/template-1 ' { "template": “index-*", "settings": { "number_of_shards": 1 }, order : 1 }
11.
© Acroquest Technology
Co., Ltd. All rights reserved. シャードが多いとどうなるか? ディスクアクセスが増えるので、IO待ちが発生する。 Kibanaなど、複数インデックスを検索する場合には、 影響が顕著に出る。 ※デフォルト値は5。 ただし、1つのインデックスに大量のデータを 登録している場合には、性能が劣化する場合もあるので、 注意すること。 11 3.シャード数を適切に設定する
12.
© Acroquest Technology
Co., Ltd. All rights reserved. シャード数はいくつにするのがよいか? 正解はない。 1シャード、1G程度を目安にし、ベンチマークし、決定する。 12 3.シャード数を適切に設定する
13.
© Acroquest Technology
Co., Ltd. All rights reserved.13 4.データの復旧方法を確保する データ復旧の必要性 データの欠損を考慮する必要があるため。 原因 1. ElasticsearchがOOMEで落ちていた。 (1.X系ではよく落ちました) 2. 1ノードで運用していると、ネットワーク瞬断など、仕組 みとして拾えない場合がある。 3. クラスタを組み、レプリカを設定することで、救出できる 可能性もあがるが、高負荷時にノード間でデータがずれ る場合がある。 ※3.は設定で回避可能であるが、性能との兼ね合いが ある。
14.
© Acroquest Technology
Co., Ltd. All rights reserved.14 4.データの復旧方法を確保する データ復旧方法とは? 1. ログを残しておき、リアルタイム投入とは別のタイミング で定期投入する。 →ただしログが重複して投入されないよう、ドキュメント のIDをログ内容から算出する必要がある。 2. スナップショットを定期的に取る。
15.
© Acroquest Technology
Co., Ltd. All rights reserved.15 5. stringをnot analyzedにできないか検討する Elasticsearchでは、ドキュメントのインデックス時に、 string型のフィールドに対してanalyzer処理が行わ れる。 ログ解析など、テキスト検索として利用しない場合 には、not analyzedに指定する方が、性能もよくな るし、適切な結果が得られる。
16.
© Acroquest Technology
Co., Ltd. All rights reserved.16 analyzer処理のデメリット 1. キーワード検索、suggestionを行わない場合には、 analyzer処理のコストが無駄に掛かる。 2. Kibanaの集計結果が期待通りにならないことがある。 5. stringをnot analyzedにできないか検討する
17.
© Acroquest Technology
Co., Ltd. All rights reserved.17 6. bulkAPIを使うときには設定を変える bulkAPIで一度に大量のデータを投入すると、 Elasticsearchが処理しきれない場合がある。 原因 1. 内部キューのスレッド数の上限に達する。 2. 内部で行われるインデックスの更新処理が重い。
18.
© Acroquest Technology
Co., Ltd. All rights reserved.18 6. bulkAPIを使うときには設定を変える 1. 内部キューのスレッド数の上限に達する Elasticsearchでは、内部に処理を行うキューとThreadPoolが あるが、高負荷のときにキューが溢れることがある。 キューのデフォルト値は50、あふれるとデータが破棄される。 ※ThreadPoolも設定可能だが、非推奨。 curl -XGET localhost:9200/_nodes/stats ... “bulk”:{ “threads”: 4, “queue”: 15, // 現在処理待ちのキューに溜まっているリクエスト数 "active": 4, "rejected": 320, // これまでにリジェクトされたリクエスト数 "largest": 5, "completed": 203312 }, ...
19.
© Acroquest Technology
Co., Ltd. All rights reserved.19 6. bulkAPIを使うときには設定を変える 1. 内部キューのスレッド数の上限に達する キューが溢れた場合には、 429エラー(Too Many Request)が返り、 送信したドキュメントは破棄されてしまう。 設定方法 curl -XPUT localhost:9200/_cluster/settings { "transient": { "threadpool.bulk.queue_size": 10000 } }
20.
© Acroquest Technology
Co., Ltd. All rights reserved.20 6. bulkAPIを使うときには設定を変える 2. 内部で行われるインデックスの更新処理が重い Elasticsearchへのドキュメント登録はバッファに蓄積されるの みであり、 定期的にインデックスへの反映処理が行われている。 更新処理はデフォルトで1秒に1回だが、 時間の掛かるbulkAPI実行時にはこの頻度で行う必要がない。 そのためbulkAPI実行時には、 更新間隔を-1(バッファの上限になるまで反映処理を行わない) に設定し、 実行完了後に元に戻すとよい。 curl -XPOST 'localhost:9200/index-d/_settings?index.refresh_interval=-1s'
21.
© Acroquest Technology
Co., Ltd. All rights reserved.21 現在、取り組んでいるもの 現在、取り組んでいるもの 1. 一定期間を過ぎたインデックスをクローズする、削除す る。 – クローズされたインデックスは検索対象外となるが、オープンすれ ば再び検索対象となる。 – 削除されたインデックスはディスクから削除される。 2. エイリアスを利用する。 3. _all, _sourceの廃止を検討する。 – allは全項目に対する串刺し検索で用いる。ログ収集においては あまり使わない。 – _sourceはJSON化する前のログ。ハイライトや部分更新で用いる。 ログ収集にはあまり使わない。
22.
© Acroquest Technology
Co., Ltd. All rights reserved. 適切なチューニングを行い、 Elasticsearchを活用しましょう。 22
Download









































![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)








































