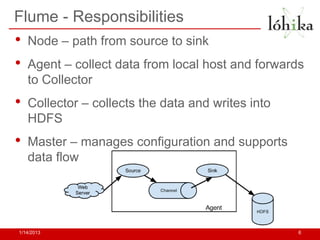
This document discusses Hadoop solutions and tools. It provides an overview of why Hadoop is used for tasks like smart meter analysis and fraud detection. It also describes tools for ingesting and exporting data from Hadoop like Flume and Sqoop. Common data formats, serialization frameworks, compression techniques and tools for testing data are outlined. The document also discusses tools for analysis like Pig and Hive and the HBase database. Finally, it reviews major Hadoop providers like Apache, Cloudera, Amazon EMR and Hortonworks and the future of technologies like Percolator, Dremel and Pregel.









































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











