Downloaded 14 times






















![JOBCLIENT.SUBMITJOB - 1
▪ Check input and output, e.g. check if the output directory is already
existing
▪ job.getInputFormat().validateInput(job);
▪ job.getOutputFormat().checkOutputSpecs(fs, job);
▪ Get InputSplits, sort, and write output to HDFS
▪ InputSplit[] splits = job.getInputFormat().
getSplits(job, job.getNumMapTasks());
▪ writeSplitsFile(splits, out); // out is $SYSTEMDIR/$JOBID/job.split
edubodhi](https://image.slidesharecdn.com/introductiontohadoopadministration-160125234413/75/Introduction-to-Hadoop-Administration-31-2048.jpg)









![JOBINPROGRESS - 2
▪ splits = JobClient.readSplitFile(splitFile);
▪ numMapTasks = splits.length;
▪ maps[i] = new TaskInProgress(jobId, jobFile, splits[i], jobtracker, conf,
this, i);
▪ reduces[i] = new TaskInProgress(jobId, jobFile, splits[i], jobtracker, conf,
this, i);
▪ JobStatus --> JobStatus.RUNNING
edubodhi](https://image.slidesharecdn.com/introductiontohadoopadministration-160125234413/75/Introduction-to-Hadoop-Administration-41-2048.jpg)




![JOBINPROGRESS - 2
▪ splits = JobClient.readSplitFile(splitFile);
▪ numMapTasks = splits.length;
▪ maps[i] = new TaskInProgress(jobId, jobFile, splits[i], jobtracker, conf,
this, i);
▪ reduces[i] = new TaskInProgress(jobId, jobFile, splits[i], jobtracker, conf,
this, i);
▪ JobStatus --> JobStatus.RUNNING
edubodhi](https://image.slidesharecdn.com/introductiontohadoopadministration-160125234413/75/Introduction-to-Hadoop-Administration-46-2048.jpg)












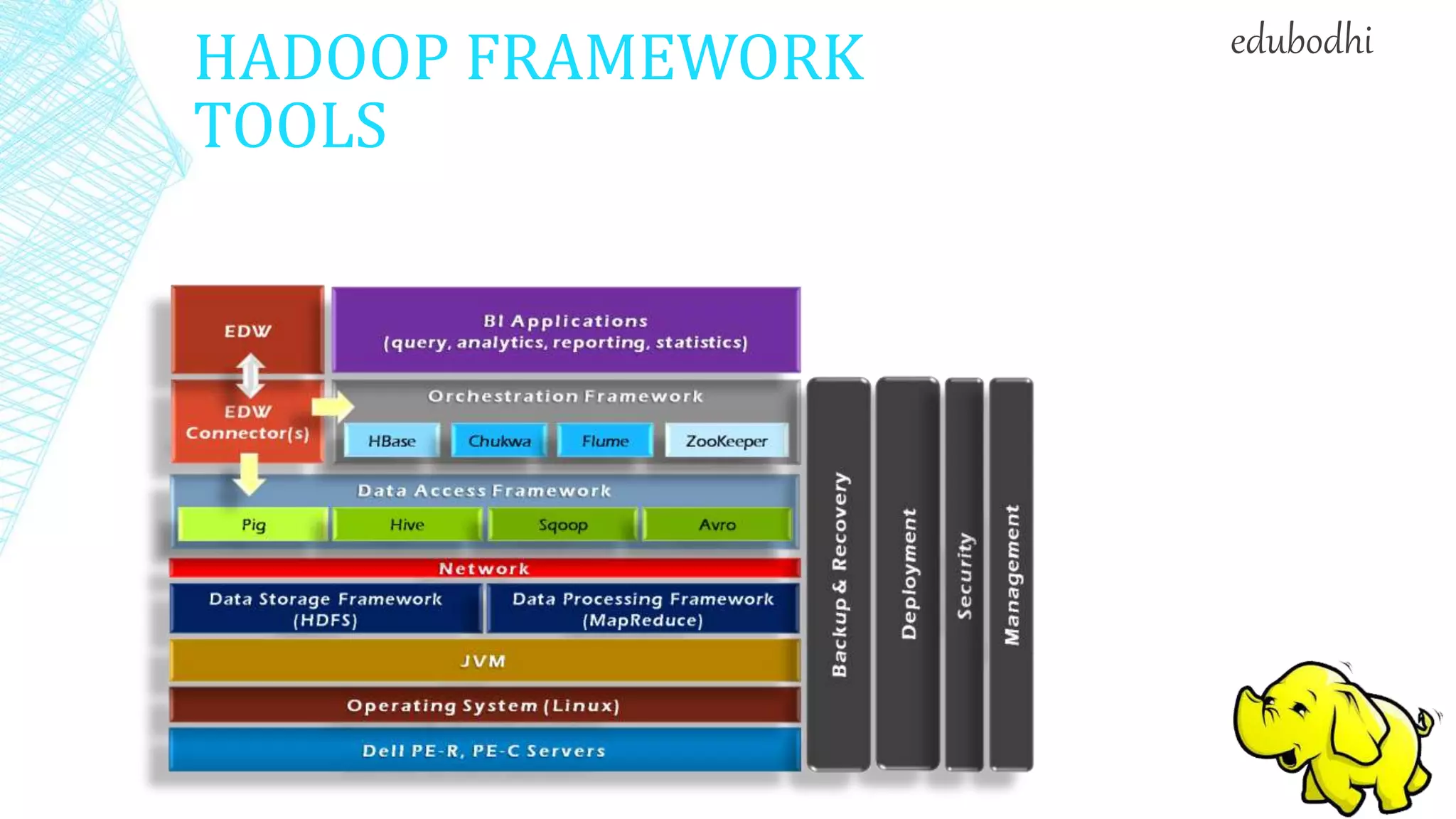
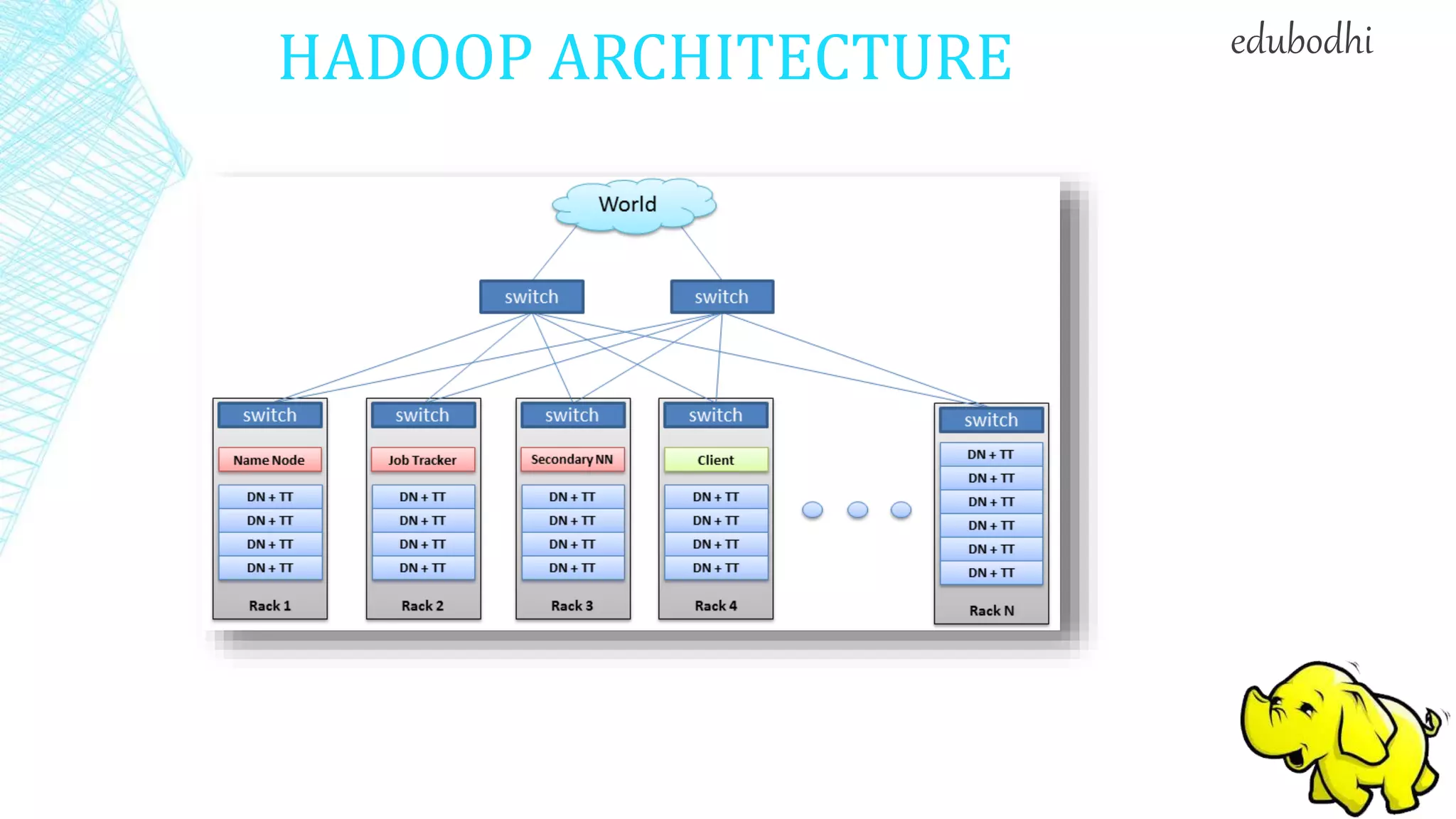
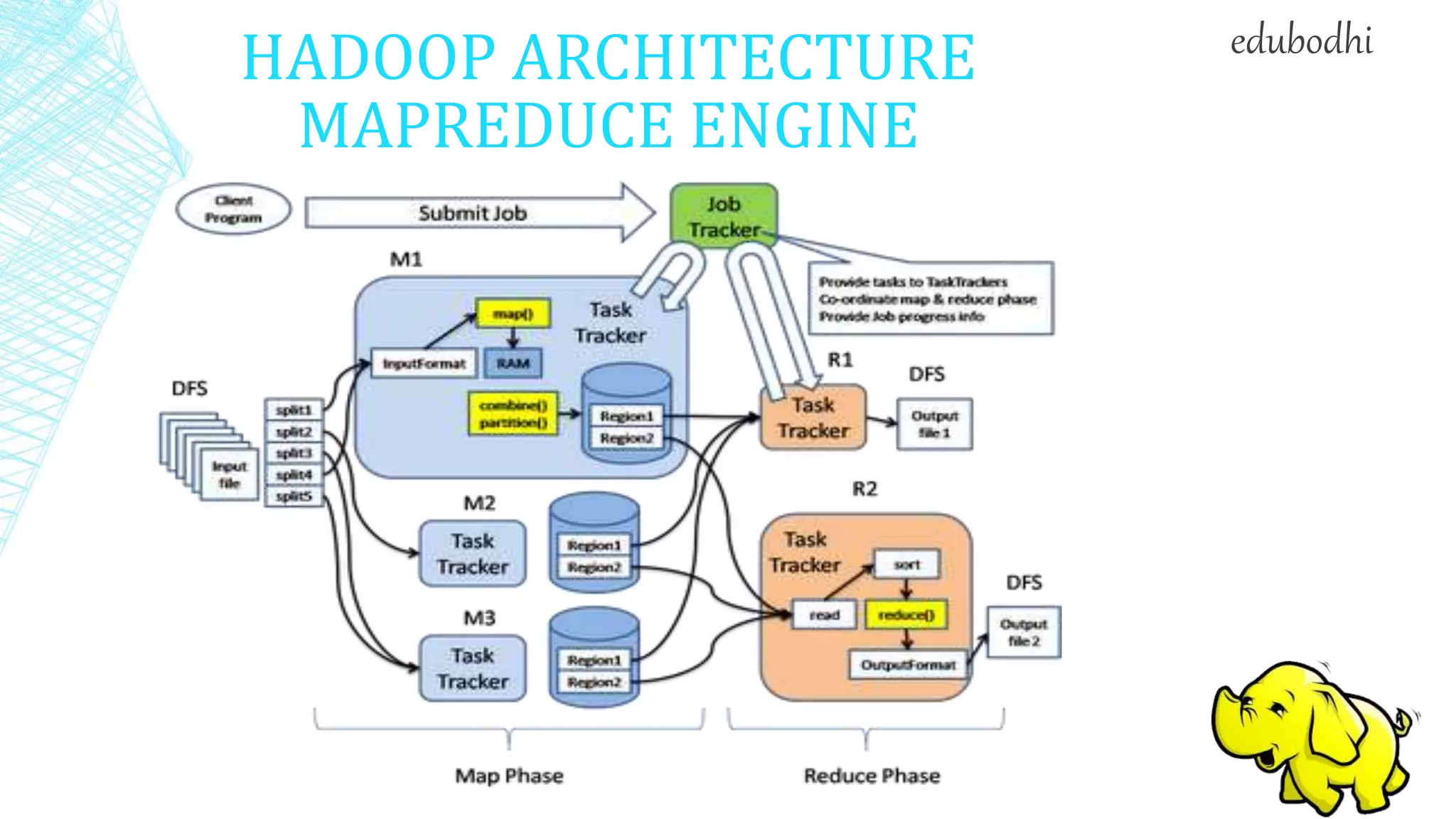
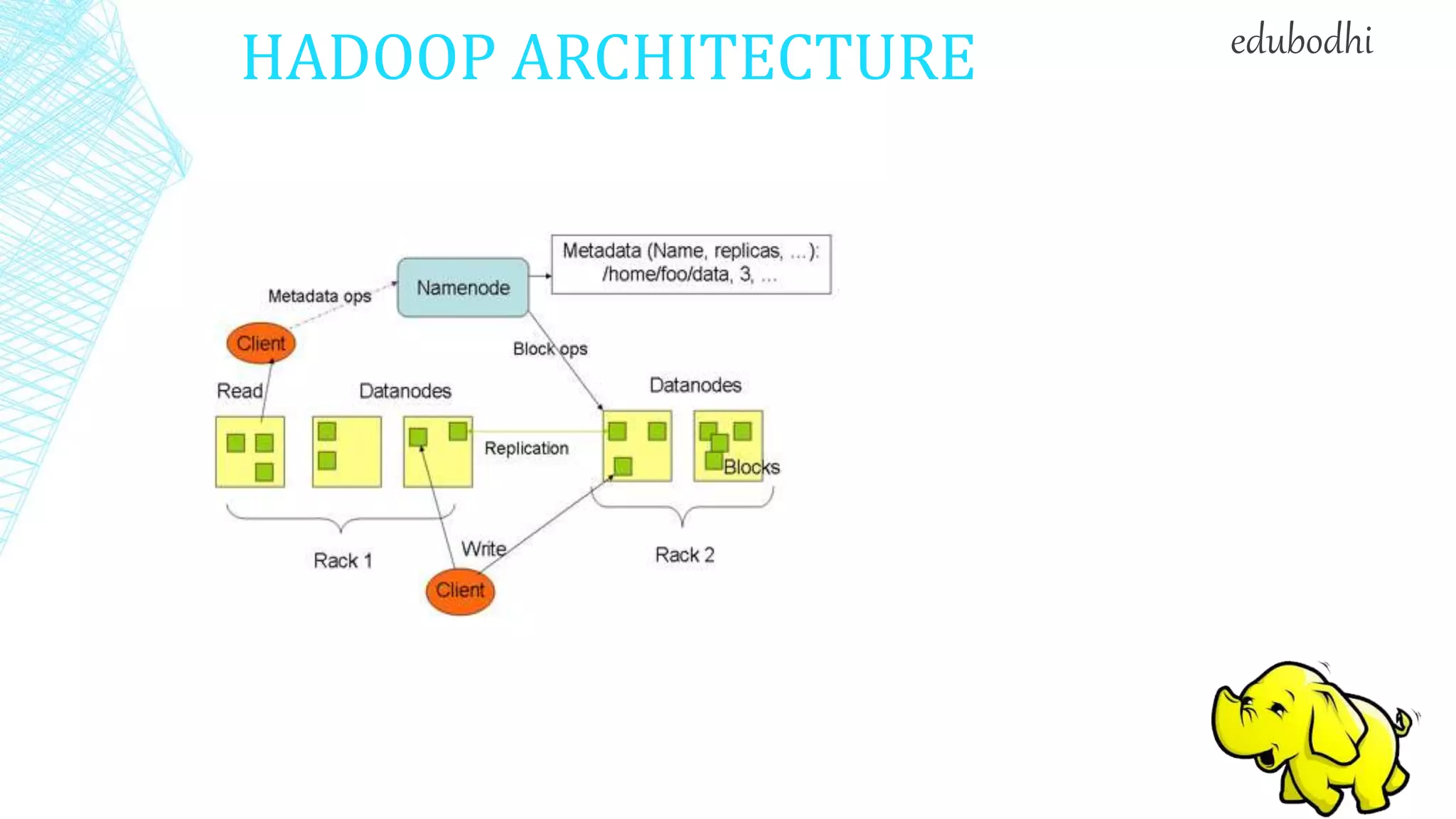
This document provides an overview of Hadoop, including: 1. Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of commodity hardware. 2. It describes the architecture of Hadoop, including the Hadoop Distributed File System (HDFS) and MapReduce engine. HDFS uses a master/slave architecture with a NameNode and DataNodes, while MapReduce uses a JobTracker and TaskTrackers. 3. It discusses some common uses of Hadoop in industry, such as for log processing, web search indexing, and ad-hoc queries at large companies like Yahoo, Facebook, and Amazon.
























































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

