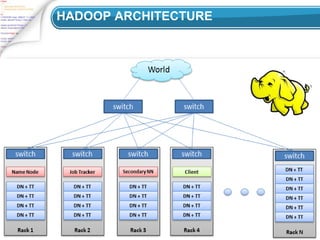
Hadoop is an open-source framework for distributed storage and processing of large datasets across clusters of computers. It has three key components:
1. The Hadoop Distributed File System (HDFS) provides distributed storage and access to large datasets across clusters.
2. MapReduce is a programming model used to process and generate large datasets in a distributed computing environment.
3. YARN is a framework for job scheduling and cluster resource management. It allows multiple data processing engines like MapReduce to handle distributed applications.
The document discusses these components in detail, explaining HDFS data replication across nodes, the MapReduce programming model for distributed computation, and how Hadoop provides a cost-effective, flexible and resilient