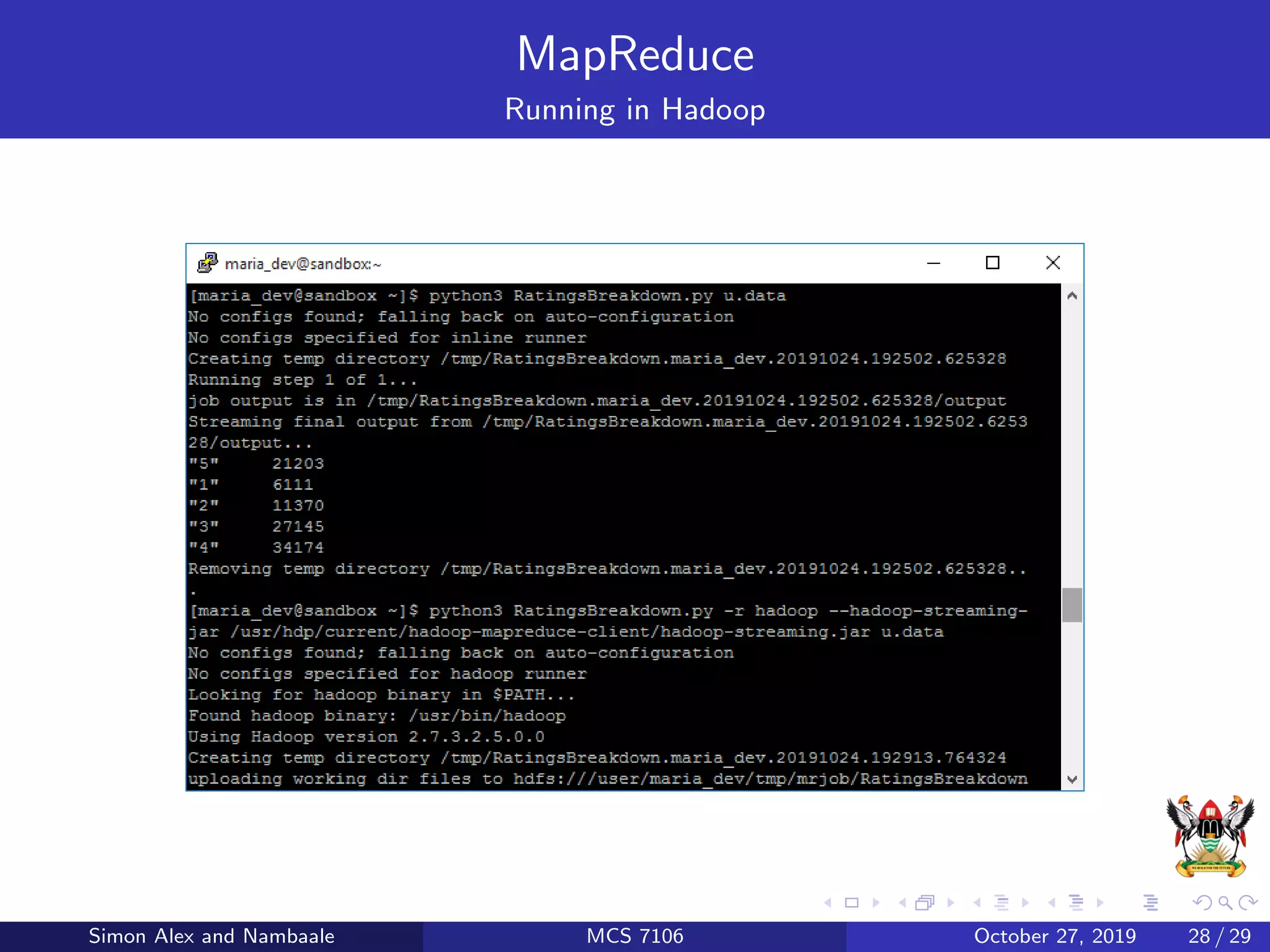
This document discusses Hadoop, an open source software platform for distributed storage and processing of large datasets across clusters of computers. It describes Hadoop's core components - HDFS for storage and MapReduce for processing. HDFS stores large files across clusters and provides fault tolerance, while MapReduce allows parallel processing of datasets using a map and reduce function. The document also provides an example of using MapReduce to find the highest CGPA for each year from a dataset of grades.























![MapReduce
Putting it all Together
from mrjob.job import MRJob
from mrjob.step import MRStep
class RatingsBreakdown (MRJob ):
def steps(self ):
return [
MRStep(mapper=self.mapper_get_ratings ,
reducer=self. reducer_count_ratings )
]
def mapper_get_ratings (self , _, line ):
(userID , movieID , rating , timestamp )= line.split(’t’)
yield rating , 1
def reducer_count_ratings (self , key , values ):
yield key , sum(values)
if __name__ == ’__main__ ’:
RatingsBreakdown .run()
Simon Alex and Nambaale MCS 7106 October 27, 2019 27 / 29](https://image.slidesharecdn.com/hadooppresentation-191031094812/75/Hadoop-presentation-27-2048.jpg)


































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)



![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









