Downloaded 26 times





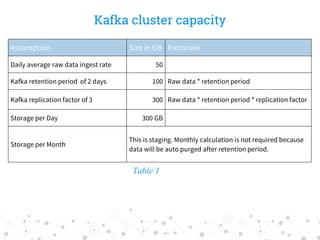
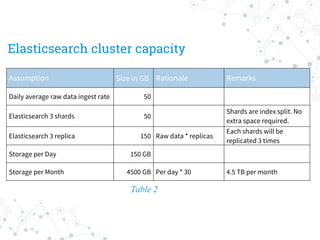
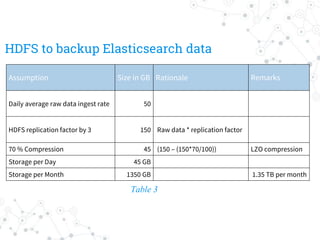
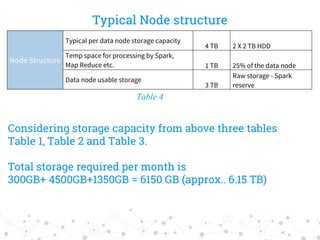

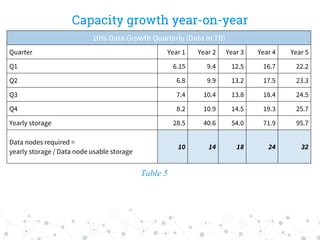

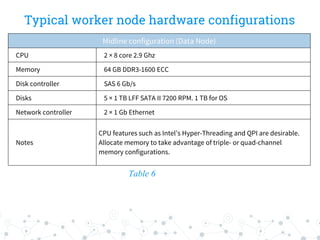



The document outlines the capacity planning for a big data solution, detailing the setup of an analytical and alerting system for data from 10,000 servers generating approximately 10 million events or 50 GB of data daily. It specifies the architecture involving components like Hadoop, Spark, Kafka, Elasticsearch, and HDFS, with storage requirements calculated to approximately 6.15 TB monthly, accounting for growth rates of 10% quarterly and 15% annually. Hardware specifications for data and namenodes are provided, emphasizing the need for specific CPU, memory, and storage configurations.



































































