Downloaded 10 times






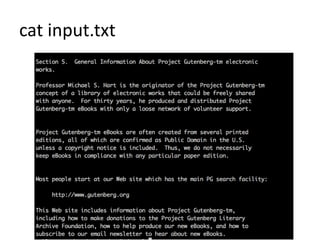




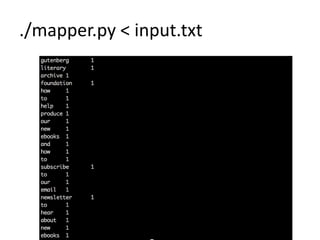

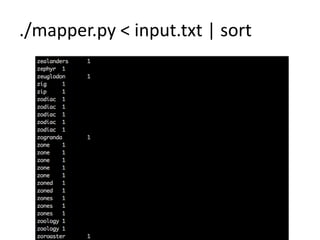

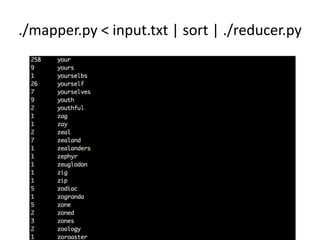



This document provides an overview of MapReduce in Python for analyzing text. It discusses setting up the environment, counting the words in Moby Dick as an example, the mapping, shuffling, and reducing steps of MapReduce, and limitations when processing very large texts. Requirements include a Unix-like system and Python. The example counts words by processing the input text with a mapper, sorting the output, and then reducing the counts with a reducer. Hadoop is also introduced as a MapReduce framework.



















































































