

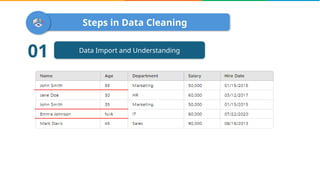

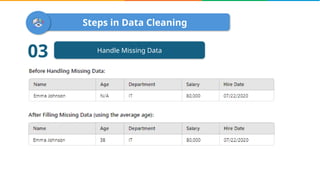
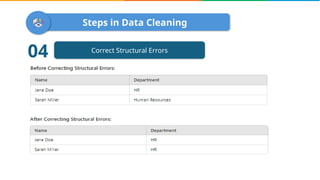
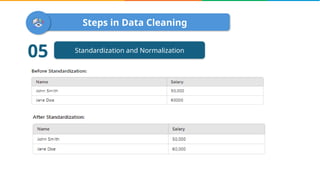
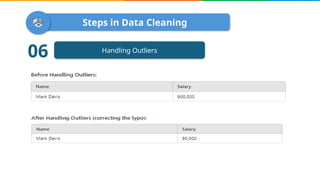
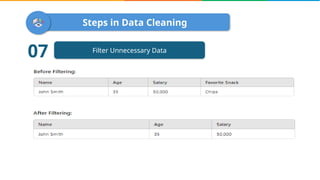
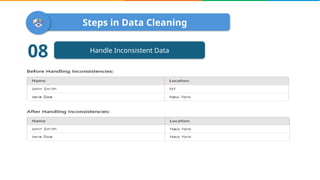
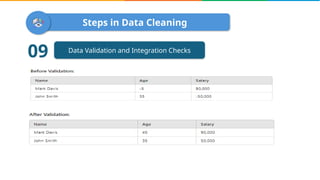
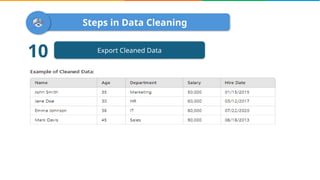

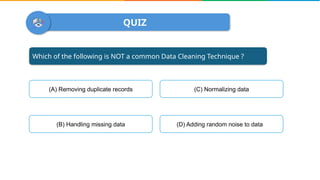

Data cleaning is the process of correcting errors and inconsistencies in a dataset to enhance its quality and reliability. It involves various steps including removing duplicates, handling missing data, correcting structural errors, and validating data. Effective data cleaning is essential for obtaining reliable insights from data.



































































