(その2) 非正規化
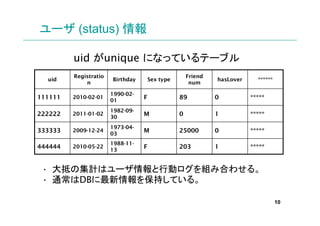
uid time Action Type Sex type age
1000222 ****** comment F 23
1022939 ****** comment M 35
• joinしたい行動ログにあらかじめ追加しておく。
• あらゆるステータス情報を追加するのは”無理”があるの
で、必要なものを吟味して追加。
13
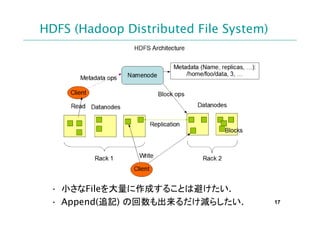
安易な方法(その1)
logrotate + rsync (daily)
Web servers
Hadoop Cluster
Server A
node A
Server B
node B
Server C node C
……
…
……
Server D …… hogelog.20110311.gz
Server E
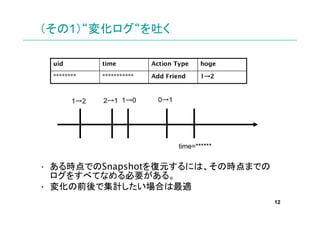
ログが収集されるまで時間がかかるので、直
近のログ集計が出来ない。
…
18
19.
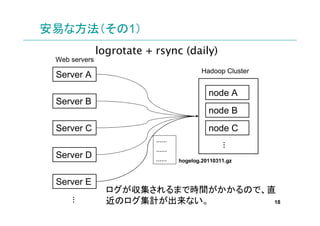
安易な方法(その2)
1アクセス(1 ログ)ごとに送信
Web servers
Hadoop Cluster
Server A
2011-03-11 *****
node A
Server B
node B
Server C node C
…
Server D
2011-03-11 *****
Server E
小さなfile が大量に出来てしまて、(恐らく)大
…
変なことになる。 19
20.
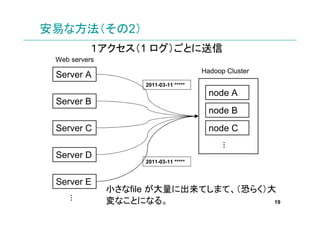
そこで…
中継サーバを設置。一旦fileをマージ。
Web servers
Server A Hadoop Cluster
中継 servers
node A
Server B
node B
Server C node C
…
…
Server D
それでも1アクセスごとにログを投げると、アク
Server E セス毎に「コネクション確立コスト」が…
20
…
21.
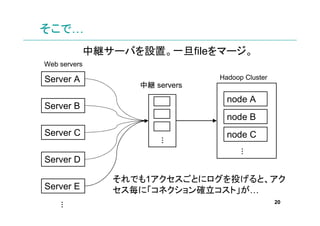
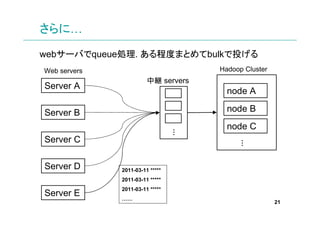
さらに…
webサーバでqueue処理. ある程度まとめてbulkで投げる
Web servers Hadoop Cluster
中継 servers
Server A
node A
Server B node B
node C
…
Server C
…
Server D 2011-03-11 *****
2011-03-11 *****
2011-03-11 *****
Server E
……
21

































![[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b12infoframe-databoosternec-150618053539-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)














![[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






























