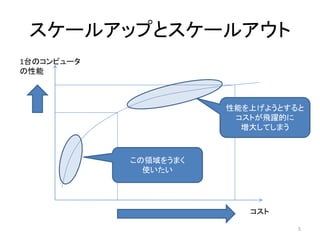
HDFSのイメージ
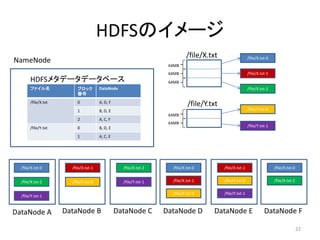
/file/X.txt
NameNode /file/X.txt-0
64MB
64MB /file/X.txt-1
HDFSメタデータデータベース 64MB
ファイル名 ブロック DataNode /file/X.txt-2
番号
/file/X.txt 0 A, D, F
/file/Y.txt
1 B, D, E /file/Y.txt-0
64MB
2 A, C, F
64MB
/file/Y.txt 0 B, D, E /file/Y.txt-1
1 A, C, E
/file/X.txt-0 /file/X.txt-1 /file/X.txt-2 /file/X.txt-0 /file/X.txt-1 /file/X.txt-0
/file/X.txt-2 /file/Y.txt-0 /file/Y.txt-1 /file/X.txt-1 /file/Y.txt-0 /file/X.txt-2
/file/Y.txt-0 /file/Y.txt-1
/file/Y.txt-1
DataNode A DataNode B DataNode C DataNode D DataNode E DataNode F
22
23.
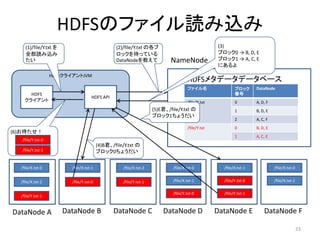
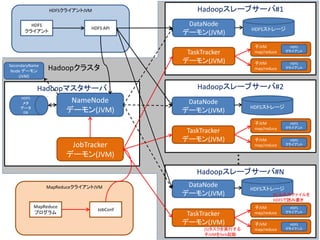
HDFSのファイル読み込み
(1)/file/Y.txt を (2)/file/Y.txt の各ブ (3)
全部読み込み ロックを持っている ブロック0 → B, D, E
たい DataNodeを教えて NameNode ブロック1 → A, C, E
にあるよ
HDFSクライアントJVM
HDFSメタデータデータベース
ファイル名 ブロック DataNode
HDFS 番号
HDFS API
クライアント /file/X.txt 0 A, D, F
(5)E君、/file/Y.txt の 1 B, D, E
ブロック1ちょうだい
2 A, C, F
/file/Y.txt 0 B, D, E
(6)お待たせ!
1 A, C, E
/file/Y.txt-0
(4)B君、/file/Y.txt の
/file/Y.txt-1 ブロック0ちょうだい
/file/X.txt-0 /file/X.txt-1 /file/X.txt-2 /file/X.txt-0 /file/X.txt-1 /file/X.txt-0
/file/X.txt-2 /file/Y.txt-0 /file/Y.txt-1 /file/X.txt-1 /file/Y.txt-0 /file/X.txt-2
/file/Y.txt-0 /file/Y.txt-1
/file/Y.txt-1
DataNode A DataNode B DataNode C DataNode D DataNode E DataNode F
23
24.
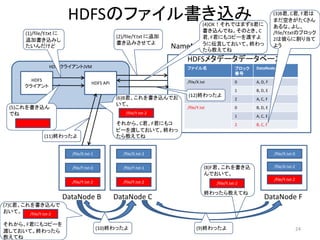
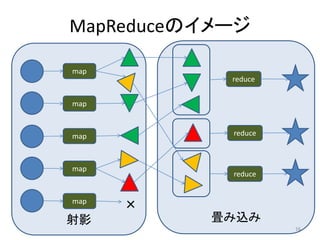
HDFSのファイル書き込み (4)OK!それではまずB君に
(3)B君, C君, F君は
まだ空きがたくさん
あるな。よし、
(1)/file/Y.txt に 書き込んでね。そのとき、C /file/Y.txtのブロック
(2)/file/Y.txt に追加 君, F君にもコピーを渡すよ 2は彼らに割り当て
追加書き込みし
書き込みさせてよ
たいんだけど NameNode
うに伝言しておいて。終わっ
たら教えてね
よう
HDFSメタデータデータベース
HDFSクライアントJVM ファイル名 ブロック DataNode
番号
HDFS /file/X.txt 0 A, D, F
HDFS API
クライアント
1 B, D, E
(6)B君、これを書き込んでお (12)終わったよ
2 A, C, F
いて。
(5)これを書き込ん /file/Y.txt 0 B, D, E
でね /file/Y.txt-2
1 A, C, E
それから、C君、F君にもコ 2 B, C, F
ピーを渡しておいて。終わっ
(11)終わったよ たら教えてね
/file/X.txt-1 /file/X.txt-2 /file/X.txt-0
/file/Y.txt-0 /file/Y.txt-1 (8)F君、これを書き込 /file/X.txt-2
んでおいて。
/file/Y.txt-2
/file/Y.txt-2 /file/Y.txt-2 /file/Y.txt-2
終わったら教えてね
DataNode B DataNode C DataNode F
(7)C君、これを書き込んで
おいて。 /file/Y.txt-2
それから、F君にもコピーを
(10)終わったよ (9)終わったよ 24
渡しておいて。終わったら
教えてね
25.
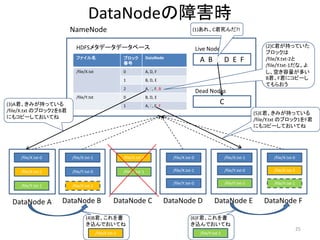
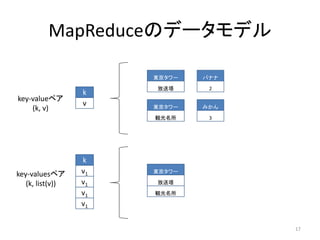
DataNodeの障害時
NameNode (1)あれ、C君死んだ?!
HDFSメタデータデータベース (2)C君が持っていた
Live Nodes
ブロックは
ファイル名 ブロック
番号
DataNode
A B C D E F /file/X.txt-2と
/file/Y.txt-1だな。よ
/file/X.txt 0 A, D, F し、空き容量が多い
1 B, D, E B君、F君にコピーし
てもらおう
2 A, C, F, B
Dead Nodes
/file/Y.txt 0 B, D, E
(3)A君、きみが持っている 1 A, C, E, F
C
/file/X.txt のブロック2をB君 (5)E君、きみが持っている
にもコピーしておいてね /file/Y.txt のブロック1をF君
にもコピーしておいてね
/file/X.txt-0 /file/X.txt-1 /file/X.txt-2 /file/X.txt-0 /file/X.txt-1 /file/X.txt-0
/file/X.txt-2 /file/Y.txt-0 /file/Y.txt-1 /file/X.txt-1 /file/Y.txt-0 /file/X.txt-2
/file/Y.txt-0 /file/Y.txt-1 /file/Y.txt-1
/file/Y.txt-1 /file/X.txt-2
DataNode A DataNode B DataNode C DataNode D DataNode E DataNode F
(4)B君、これを書 (6)F君、これを書
き込んでおいてね き込んでおいてね
25
/file/X.txt-2 /file/Y.txt-1
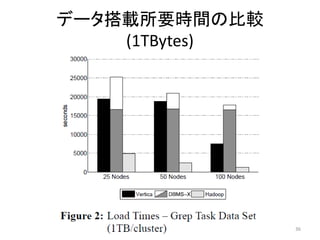
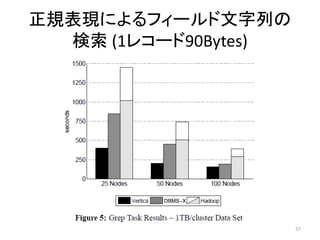
分散RDBMSとの比較
Andrew Pavlo etal. A Comparison of
Approaches to Large-Scale Data Analysis, In
Proc. of SIGMOD 2009, pp. 165-178.
• Hadoopと2種類の商用分散RDBMS (Verticaと
某製品)を比較
• データの搭載はHadoopが高速
• 特定のカラムを対象とした検索処理は分散
RDBMSが高速
• どちらを選択すべきかは用途に応じて決める
べき
35














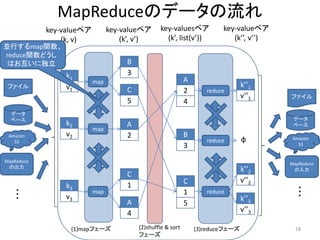
![MapReduceの多段適用
(アクセスログ集計処理の例)
k
110.0.146.55 - -
[12/Jan/2010:06:00:10 +0900]
v
"GET /linux/ HTTP/1.0" 302 1102
110.0.240.244 - - k 5 /article/COLUMN/2006022
v
[12/Jan/2010:06:19:29 +0900] 4/230573/
"GET
/article/COLUMN/20060224/23 3 /linux/image/cover_small_
0573/ HTTP/1.1" 200 82242
110.0.240.244 - -
MapReduce k MapReduce
1002.jpg
[12/Jan/2010:06:20:23 +0900]
v 3 /linux/image/logo10.jpg
"GET
/article/COLUMN/20060224/23 (grep-search) (grep-sort) 2
0573/ HTTP/1.1" 200 82242 k /linux/image/cover_small_
110.0.43.6 - -
[12/Jan/2010:06:26:20 +0900] v 1002.jpg
"GET /linux/ HTTP/1.1" 302 1102
110.0.43.6 - - ・・
[12/Jan/2010:06:26:20 +0900] (k, v) ・ (k, v)
"GET
/linux/image/cover_small_1002. = (null, アクセスログの1行) = (URL, アクセス頻度)
k
jpg HTTP/1.1" 304 0
(k’, v’) (k’, v’)
= (URL, 1) v = (アクセス頻度, URL)
(k’’, v’’) (k’’, v’’)
(k, v)
= (URL, アクセス頻度) = (null, 行の文字列)
= (URL, アク
セス頻度)
map関数: map関数:
URLを正規表現で抜き出す URLとアクセス頻度をひっくり返し、
reduce関数: keyをアクセス頻度にする
URL毎の頻度をカウントする reduce関数:
行の文字列を生成する 19](https://image.slidesharecdn.com/infotalk20100319-100415035441-phpapp02/85/Hadoop-19-320.jpg)