






![MapReduce
• Collected Tweet Data
• Twitter Inner Data Model
1
n
n
m
n m
following
count …
1 1
follower
count
Spatial Data Processing on Hadoop 10
{
“mid” : “1234567”,
"filter_level":"medium",
"contributors":null,
"text":"역시 다 멋있다 #EVERYBODY",
"geo":{
"type":"Point",
"coordinates":[37.3604652, 127.9554015]
},
"retweeted":false,
"created_at":"Fri Oct 11 10:32:52 +0000 2013",
"lang":"ko",
"id":388613160678088700,
"retweet_count":0,
"favorite_count":0,
"id_str":"388613160678088704",
"user":{
"lang":"ko",
"id":1394439386,
"verified":false,
"contributors_enabled":false,
"name":"은지",
"created_at":"Wed May 01 11:32:39 +0000 2013",
"geo_enabled":true,
"time_zone":"Seoul",
“follower_count":93,
“following_count”:30,
“favorate_count”: 105,
"id_str":"1394439386",
}
}
user tw tweet
fol fav
• Real Collected Twitter Data
userlog tw tweet](https://image.slidesharecdn.com/foss4g2014hadoop-geohash-v02-140829035316-phpapp02/85/FOSS4G-KOREA-2014-Hadoop-MapReduce-Spatial-Big-Data-10-320.jpg)
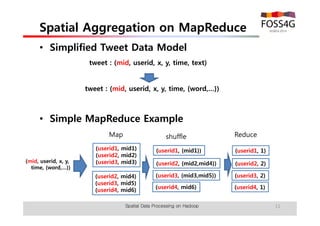























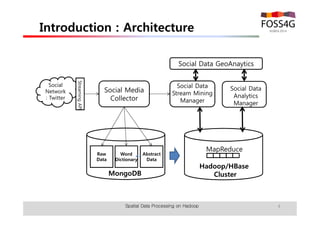
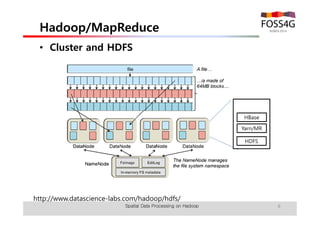
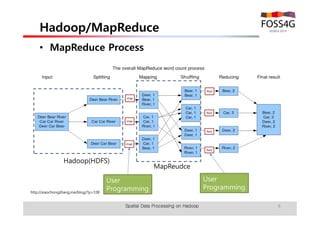
The document outlines methods for processing spatial big data using Hadoop and MapReduce, focusing on social media data, particularly Twitter streams. It describes the architecture of a Hadoop cluster, the use of geohashing for spatial keys, and spatial aggregation techniques for analyzing large datasets. The document also highlights the construction and management of big data systems, with practical insights and tools from ESRI for optimizing geospatial data processing.






























![[공간정보시스템 개론] L04 항공사진의 이해](https://cdn.slidesharecdn.com/ss_thumbnails/l04-170314115042-thumbnail.jpg?width=640&height=640&fit=bounds)













![[FOSS4G Korea 2016] GeoHash를 이용한 지형도 변화탐지와 시계열 관리](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2016koreageohash-160905074529-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[공간정보시스템 개론] L03 지구의형상과좌표체계](https://cdn.slidesharecdn.com/ss_thumbnails/l03-170314115023-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L02 공간정보와 지리정보](https://cdn.slidesharecdn.com/ss_thumbnails/l02-170314114945-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L01 공간정보시스템개요](https://cdn.slidesharecdn.com/ss_thumbnails/l01-170314114926-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L12 공간정보분석](https://cdn.slidesharecdn.com/ss_thumbnails/l12-170314114828-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L11 공간정보의 구축](https://cdn.slidesharecdn.com/ss_thumbnails/l11-170314114751-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L10 수치표고모델](https://cdn.slidesharecdn.com/ss_thumbnails/l10-170314114727-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L09 공간 데이터 모델](https://cdn.slidesharecdn.com/ss_thumbnails/l09-170314114718-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L08 gnss의 개념과 활용](https://cdn.slidesharecdn.com/ss_thumbnails/l08gnss-170314114625-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L07 원격탐사의 개념과 활용](https://cdn.slidesharecdn.com/ss_thumbnails/l07-170314114620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L06 GIS의 이해](https://cdn.slidesharecdn.com/ss_thumbnails/l06gis-170314114559-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L05 우리나라의 수치지도](https://cdn.slidesharecdn.com/ss_thumbnails/l05-170314114527-thumbnail.jpg?width=640&height=640&fit=bounds)















![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









