Download as PDF, PPTX



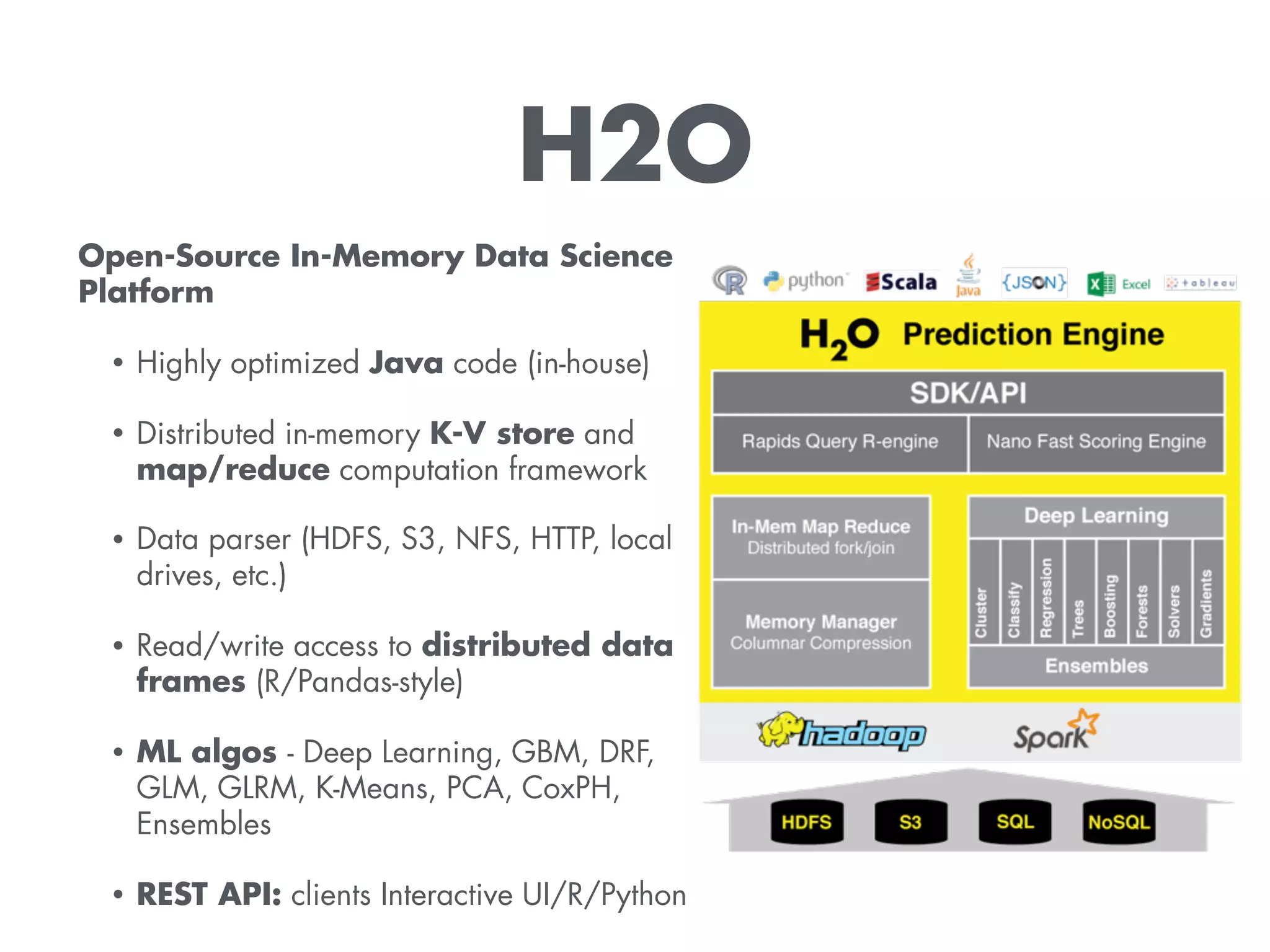





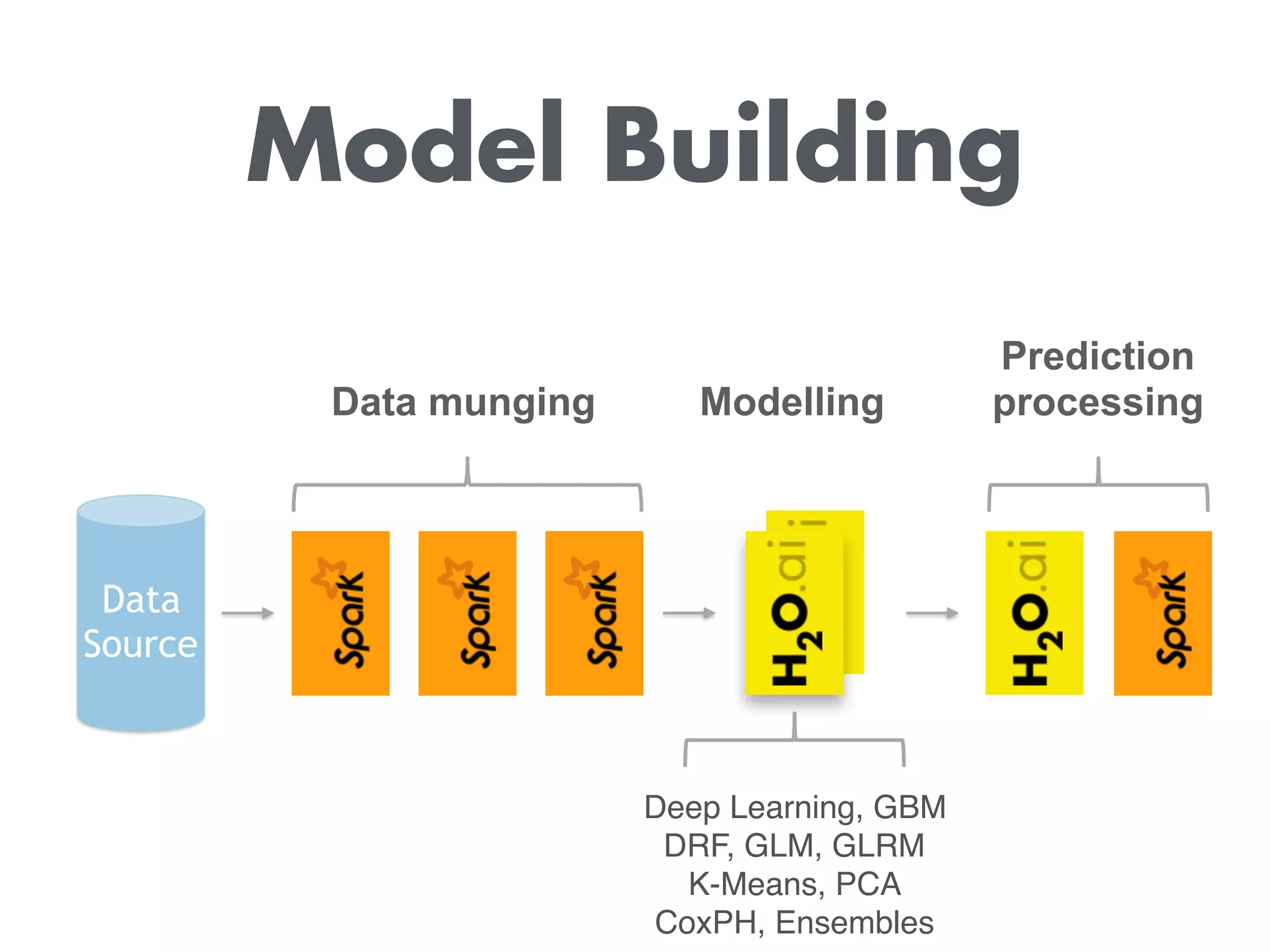
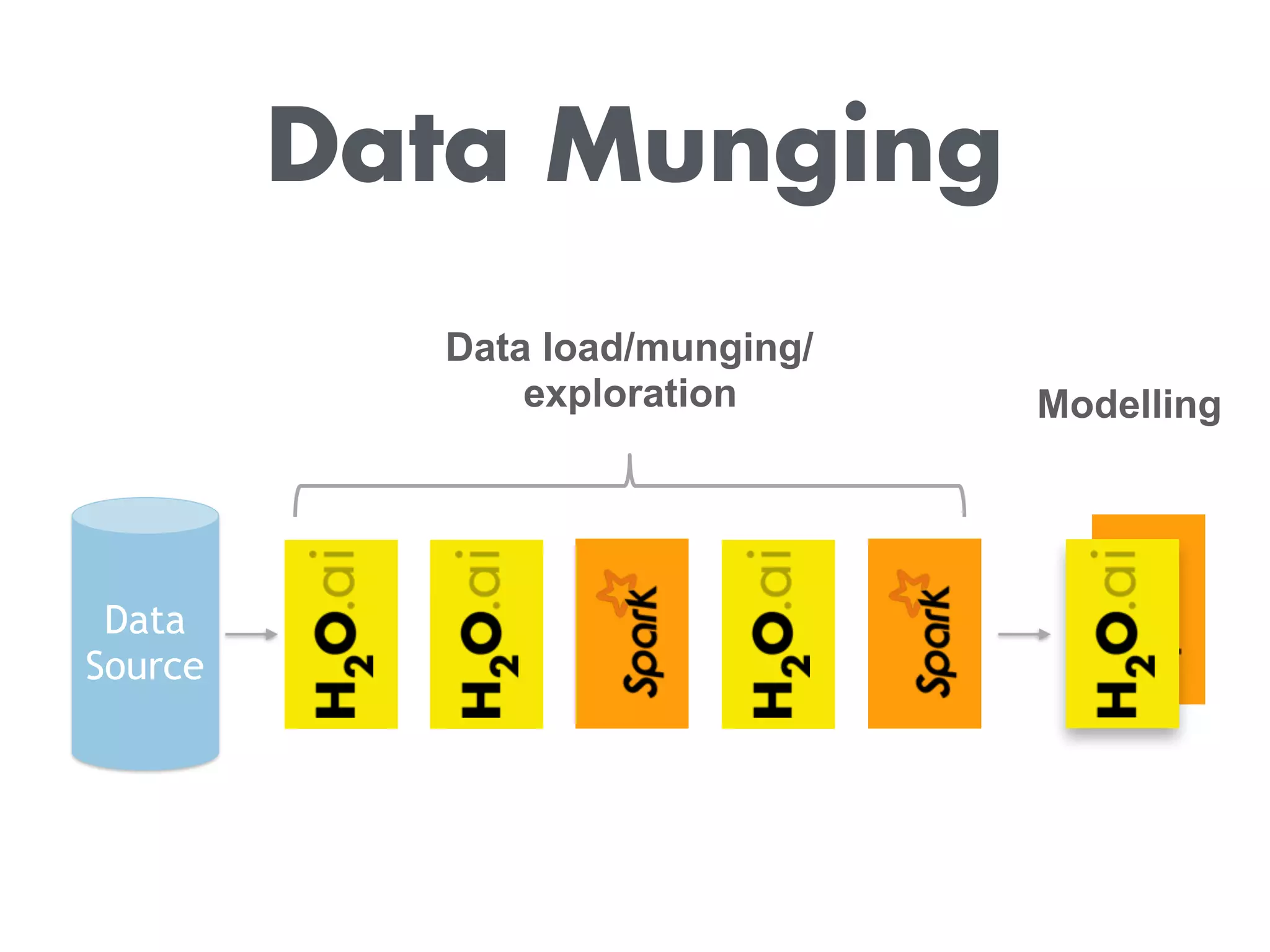












The document discusses H2O.ai, an open-source data science platform that integrates with Databricks and the Spark ecosystem, allowing users to perform distributed data processing and machine learning. It highlights features such as data transformation, model building, and prediction capabilities, along with the use of advanced machine learning algorithms in Spark workflows. Additionally, it provides resources for learning about H2O and Spark integration, including tutorials, a YouTube channel, and GitHub repositories.











































































































