Downloaded 95 times








![LAMBDA FUNCTION HANDLER
public static ResponseClass myHandler(RequestClass
request, Context context) throws PyException {
PyModule module = new PyModule();
//Prediction code is in pymodule.py
double[]predictions=module.predict(request.domain);
return new ResponseClass(predictions);
}
REST
endpoint
Jython
Feature
Munging
Lambda
Function
Handler
H2O Model
POJO
Prediction](https://image.slidesharecdn.com/buildinganappwithawslambda-160404052951/85/Building-a-Machine-Learning-App-with-AWS-Lambda-10-320.jpg)
![JYTHON FEATURE MUNGING
def predict(domain):
domain = domain.split('.')[0]
row = RowData()
functions = [len, entropy, p_vowels, num_valid_substrings]
eval_features = [f(domain) for f in functions]
names = NamesHolder_MaliciousDomainModel().VALUES
beta = MaliciousDomainModel().BETA().VALUES
feature_coef_product = [beta[len(beta) - 1]]
for i in range(len(names)):
row.put(names[i], float(eval_features[i]))
feature_coef_product.append(eval_features[i] * beta[i])
#prediction
model = EasyPredictModelWrapper(MaliciousDomainModel())
p = model.predictBinomial(row)
REST
endpoint
Jython
Feature
Munging
Lambda
Function
Handler
H2O Model
POJO
Prediction](https://image.slidesharecdn.com/buildinganappwithawslambda-160404052951/85/Building-a-Machine-Learning-App-with-AWS-Lambda-11-320.jpg)
![H2O MODEL POJO
• static final class BETA_0 implements java.io.Serializable {
static final void fill(double[] sa) {
sa[0] = 1.49207826021648;
sa[1] = 2.8502716978560194;
sa[2] = -8.839804567200542;
sa[3] = -0.7977065034624655;
sa[4] = -14.94132841574946;
}
}
REST
endpoint
Jython
Feature
Munging
Lambda
Function
Handler
H2O Model
POJO
Prediction](https://image.slidesharecdn.com/buildinganappwithawslambda-160404052951/85/Building-a-Machine-Learning-App-with-AWS-Lambda-12-320.jpg)




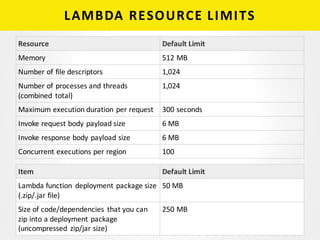







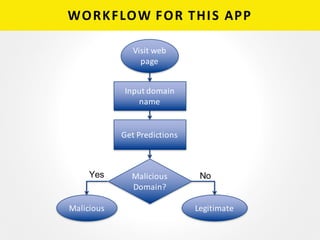
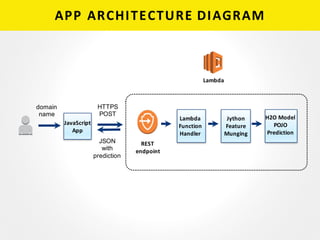
The document provides a detailed overview of building a machine learning application using AWS Lambda, highlighting its key features, such as automatic management of compute resources and server maintenance. It outlines the major steps involved, including training a model, exporting it, and deploying it as a Lambda function for domain name classification between legitimate and malicious domains. Additionally, it discusses performance metrics, common errors, pricing, and includes resources for further learning.












































































