Downloaded 100 times








![many dialects of XML are in use <ccxml version="1.0" xmlns="http://www.w3.org/2002/09/ccxml"> <eventprocessor> <transition event="connection.alerting" name="evt"> <log expr="'The number called is' + evt.connection.remote + '.'"/> <if cond="evt.connection.remote == 'tel:+18315551234'"> <log expr="'Go away! we do not want to answer the phone.'"/> <reject/> <else/> <log expr="'We like you! We are going to answer the call.'"/> <accept/> </if> </transition> <transition event="connection.connected"> <log expr="'Call was answered,Time to disconnect it.'"/> <disconnect/> </transition> <transition event="connection.disconnected"> <log expr="'Call has been disconnected. Ending CCXML Session.'"/> <exit/> </transition> </eventprocessor> </ccxml> <mroot> <mrow> <mn>1</mn> <mo>-</mo> <mfrac> <mi>x</mi> <mn>2</mn> </mfrac> </mrow> <mn>3</mn> </mroot> <users> <person login="fgandon" uid="19536"> <home>/net/user/fg</home> <pref>/sys/19536.inf</pref> <access_level>8</access_level> </person> <person login="fgandon" uid="19536"> <home>/net/user/fg</home> <pref>/sys/19536.inf</pref> <access_level>8</access_level> </person> </users> <p:pipeline name="fig2" xmlns:p="http://example.org/PipelineNamespace"> <p:input port="doc" sequence="no"/> <p:output port="out" step="xform" source="result"/> <p:choose name="vcheck" step="fig2" source="doc"> <p:when test="/*[@version < 2.0]"> <p:output name="valid" step="val1" source="result"/> <p:step type="p:validate" name="val1"> <p:input port="document" step="fig2" source="doc"/> <p:input port="schema" href="v1schema.xsd"/> </p:step> </p:when> <p:otherwise> <p:output name="valid" step="val2" source="result"/> <p:step type="p:validate" name="val2"> <p:input port="document" step="fig2" source="doc"/> <p:input port="schema" href="v2schema.xsd"/> </p:step> </p:otherwise> </p:choose> <p:step type="p:xslt" name="xform"> <p:input port="document" step="vcheck" source="valid"/> <p:input port="stylesheet" href="stylesheet.xsl"/> </p:step> </p:pipeline> <HTML> <HEAD> <TITLE>title</TITLE> <LINK REL=STYLESHEET TYPE="text/css" HREF="http://style.com/cool" TITLE="Cool"> </HEAD> <BODY> <H1>Headline is blue</H1> <P STYLE="color: green">While the paragraph is green. </BODY> </HTML>](https://image.slidesharecdn.com/grddl-in-a-nutshell-v1-11978216398116-5/85/Grddl-In-A-Nutshell-V1-8-320.jpg)














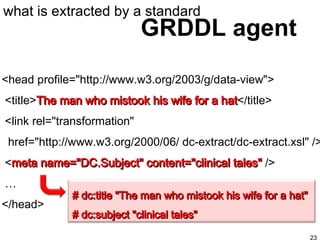












The document discusses GRDDL ( Gleaning Resource Descriptions from Dialects of Languages), which is an easy way to extract metadata from web pages in various formats like HTML and XML. It allows one to declare a web page or document as a source of data, link it to extractors that can glean semantic data from it, and then have GRDDL agents extract RDF descriptions from the document. This is done by adding GRDDL profiling and transformation links to declare the source and transformation that will be applied.














![Tugas Pw [6]](https://cdn.slidesharecdn.com/ss_thumbnails/tugaspw6-100318083950-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![Tugas Pw [6] (2)](https://cdn.slidesharecdn.com/ss_thumbnails/tugaspw62-100407041015-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

































![[DSBW Spring 2010] Unit 10: XML and Web And beyond](https://cdn.slidesharecdn.com/ss_thumbnails/dsbw-spring-2010-unit-10-xml-and-web-and-beyond3626-thumbnail.jpg?width=640&height=640&fit=bounds)






















































