Download to read offline











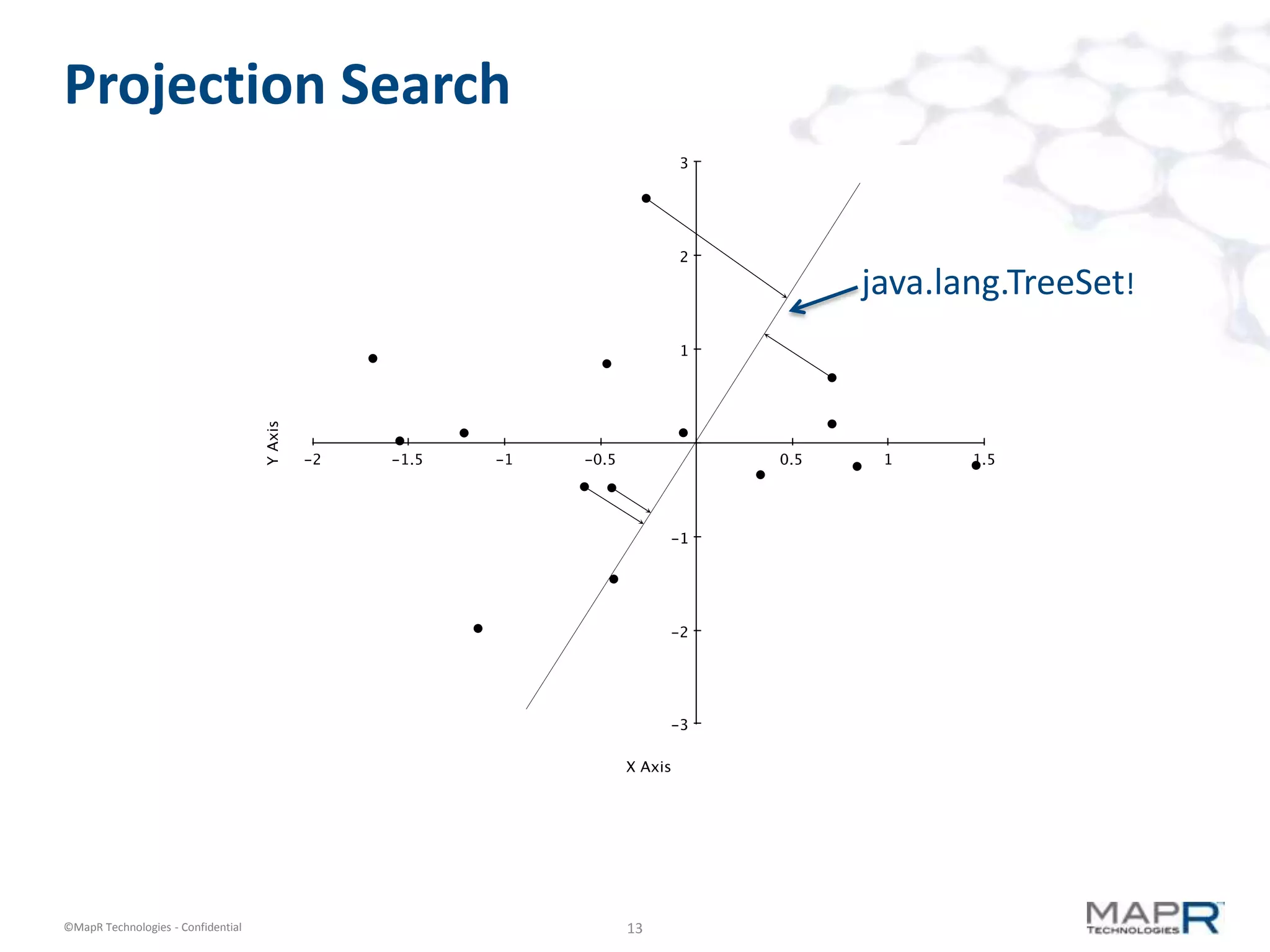
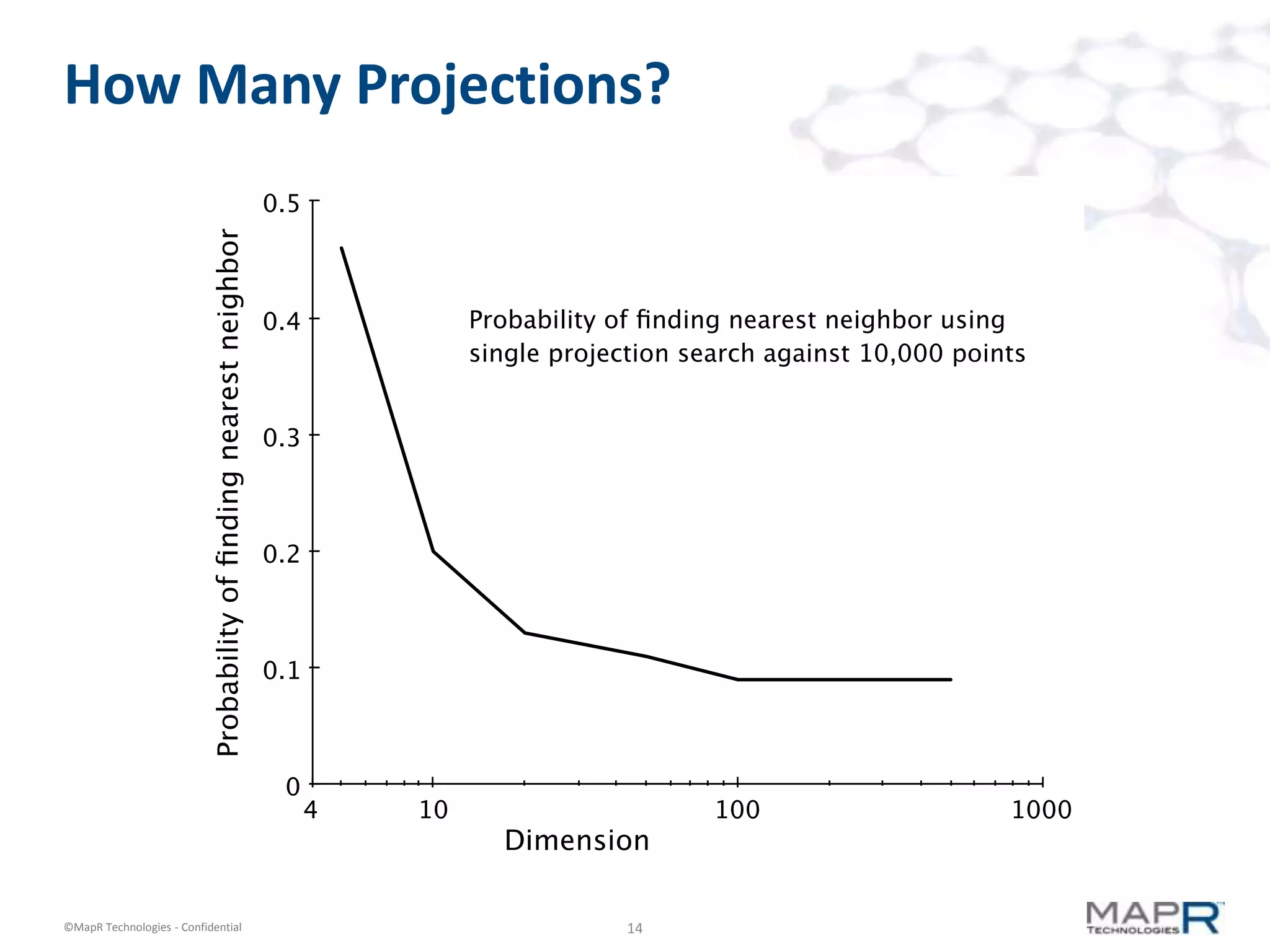

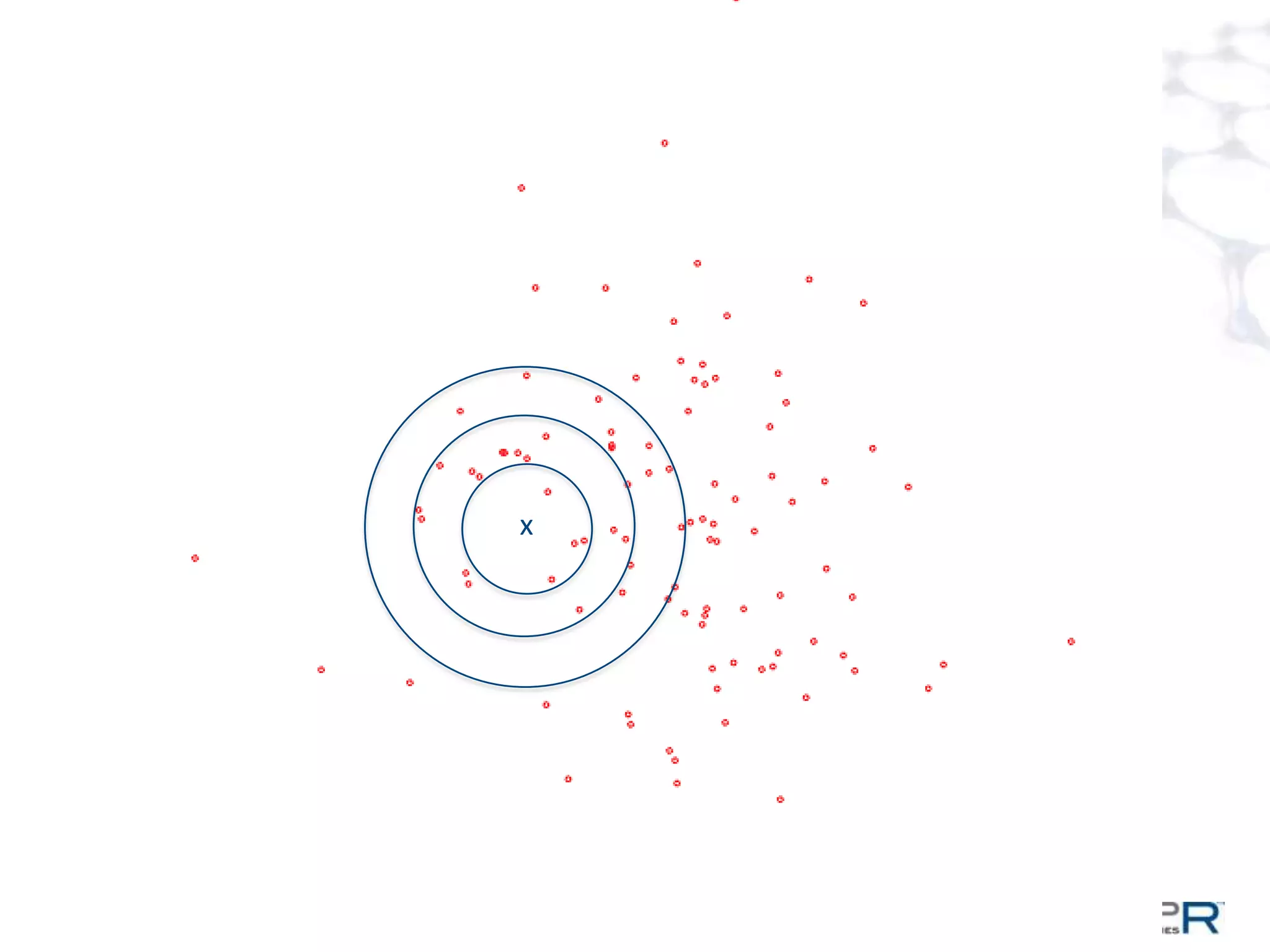
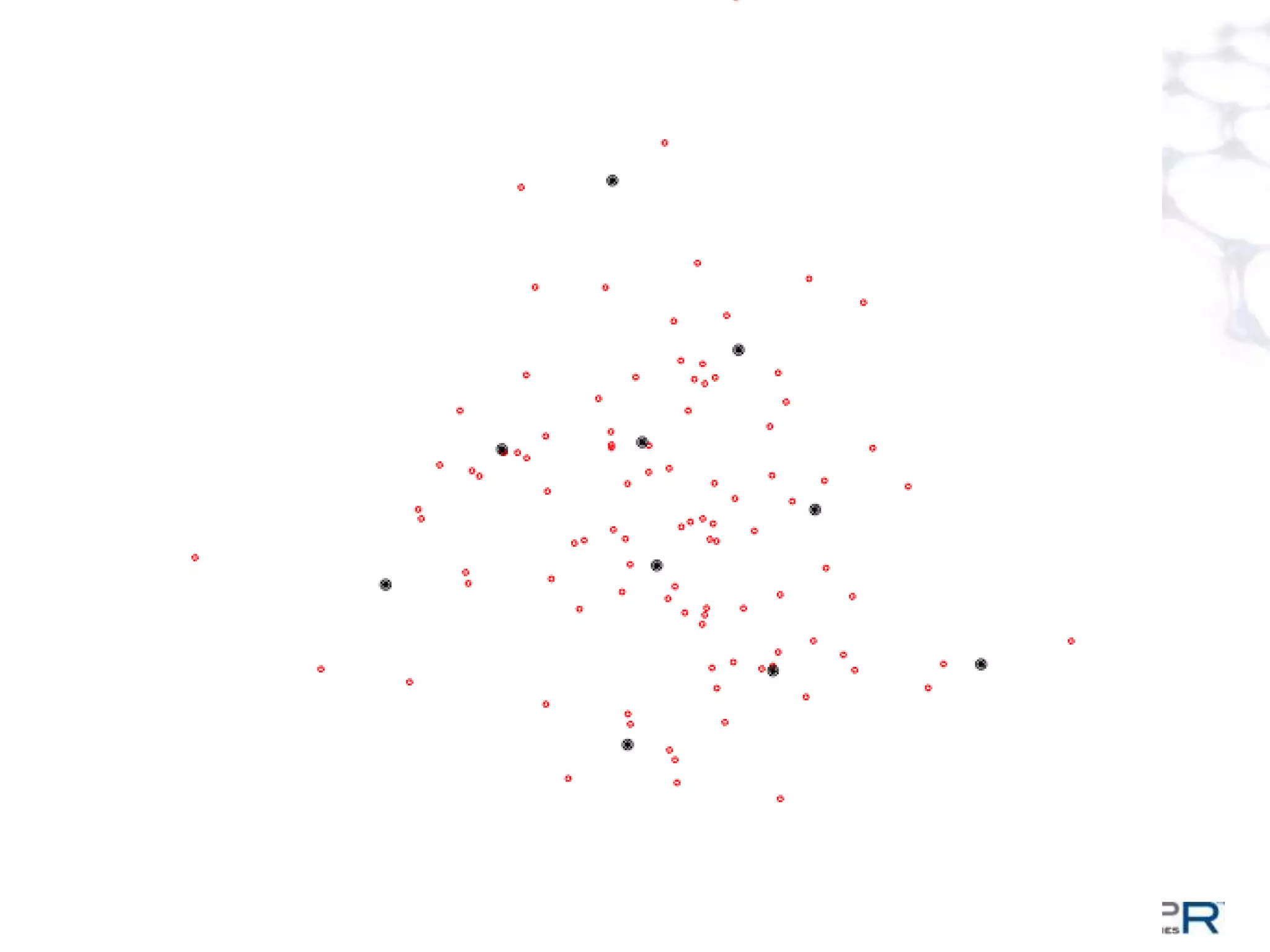
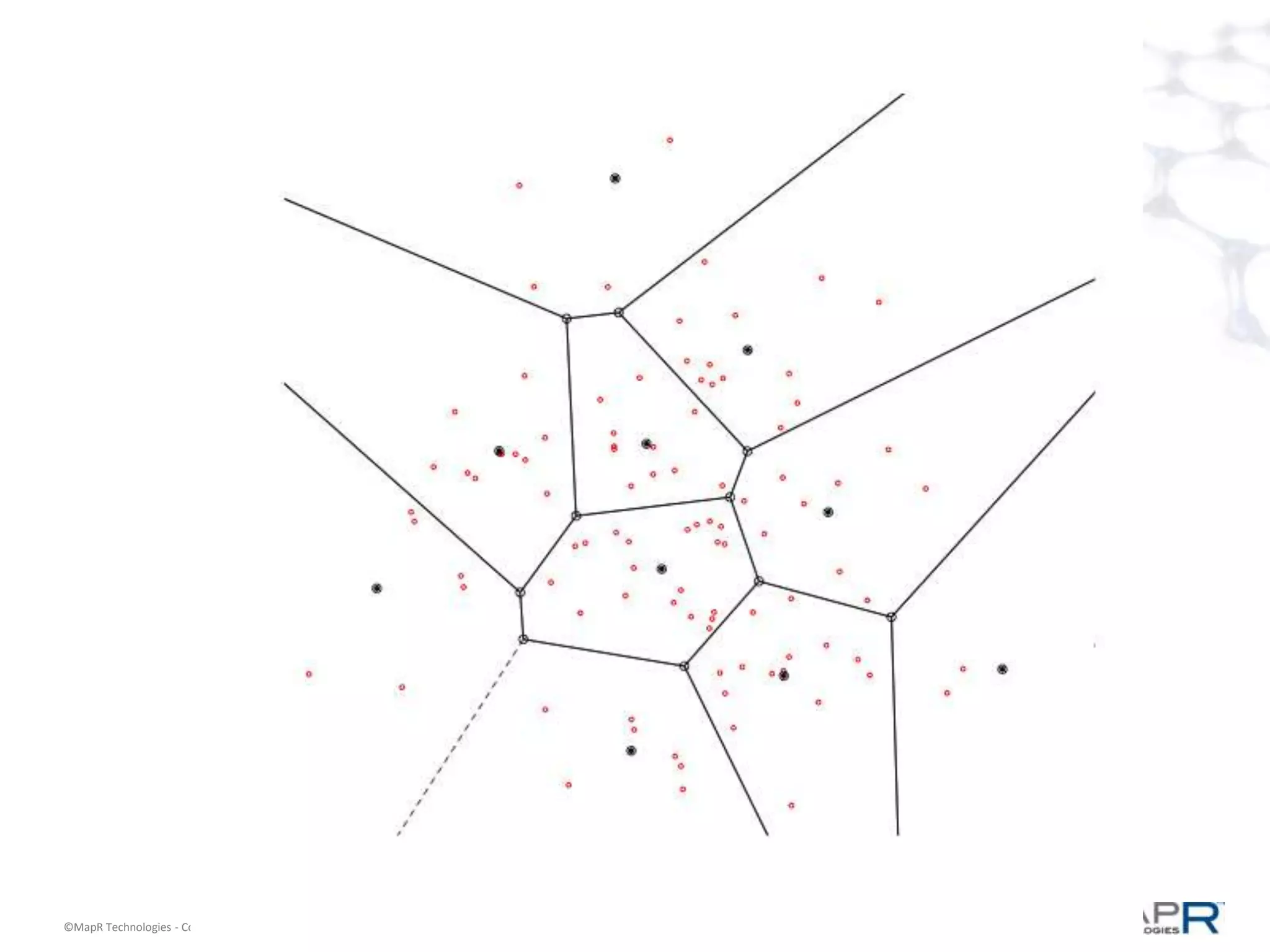
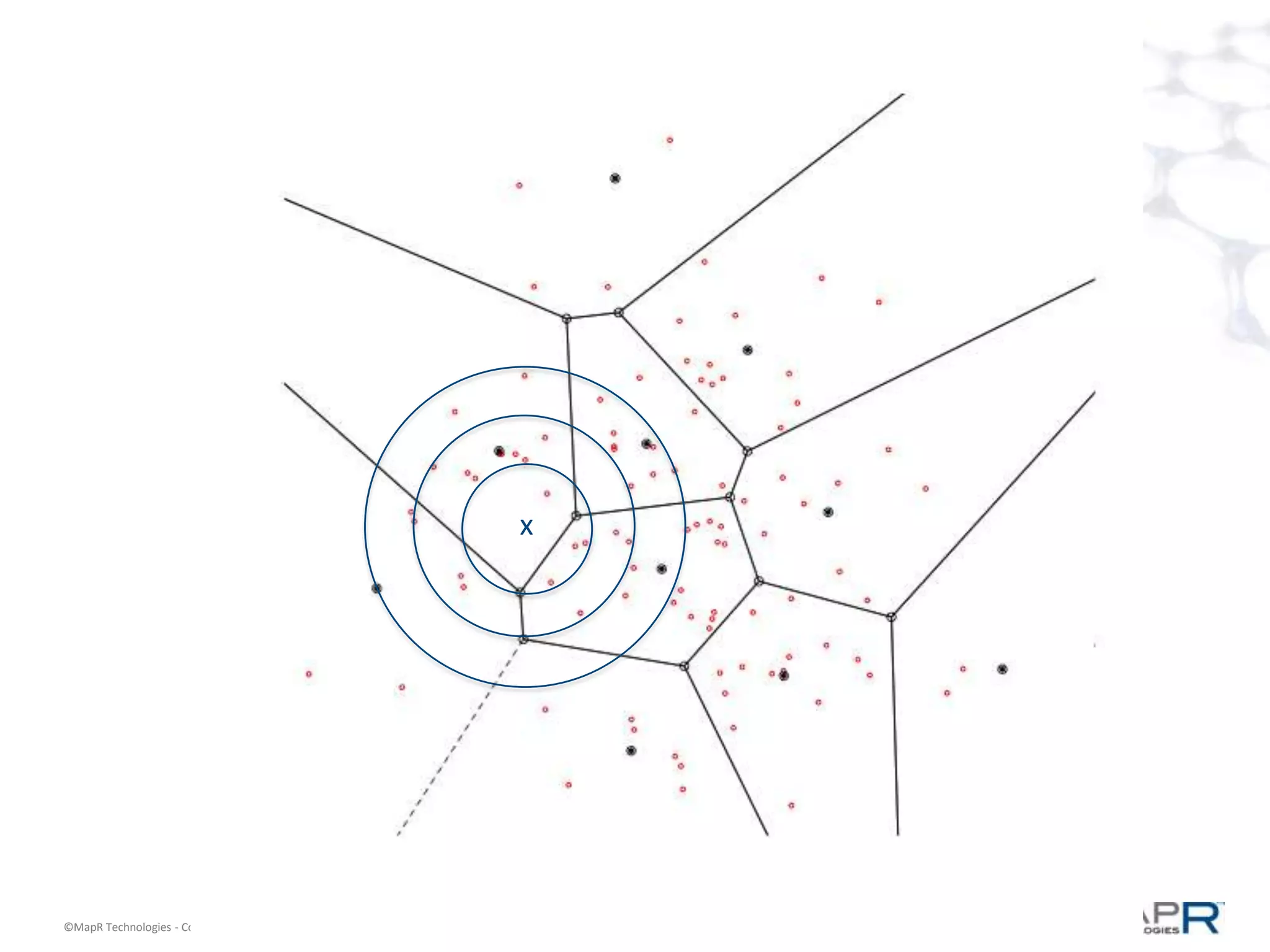




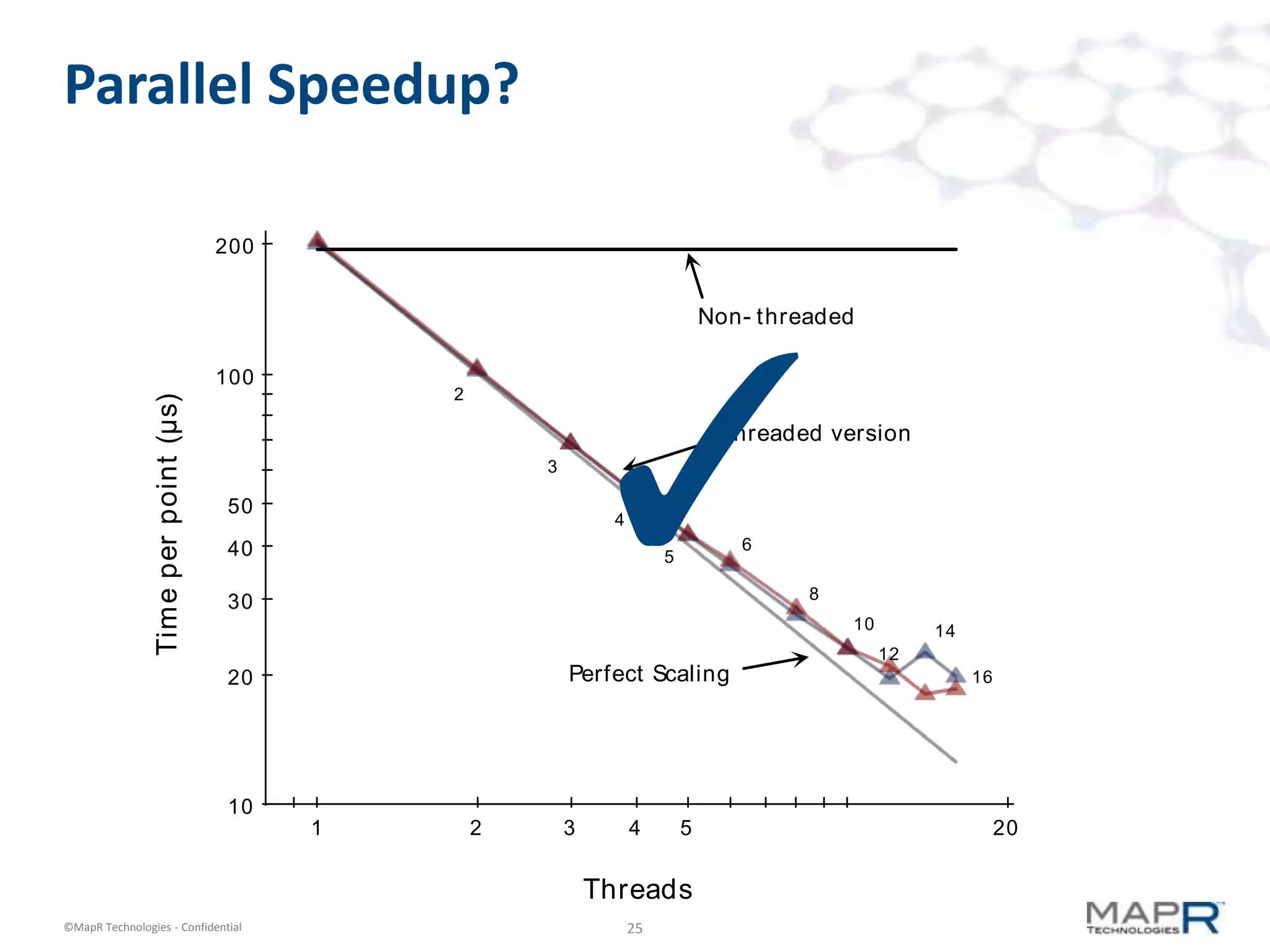






The document discusses a large-scale, single-pass k-means clustering method designed to efficiently cluster massive datasets while achieving high-quality results. It details the development process undertaken by a team from a customer bank during a two-week hackathon, resulting in significant speed improvements for clustering algorithms. Key features include the use of synthetic data, open-source licensing, and the implementation of shared memory matrices and streamlined search interfaces to enhance performance.












































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









