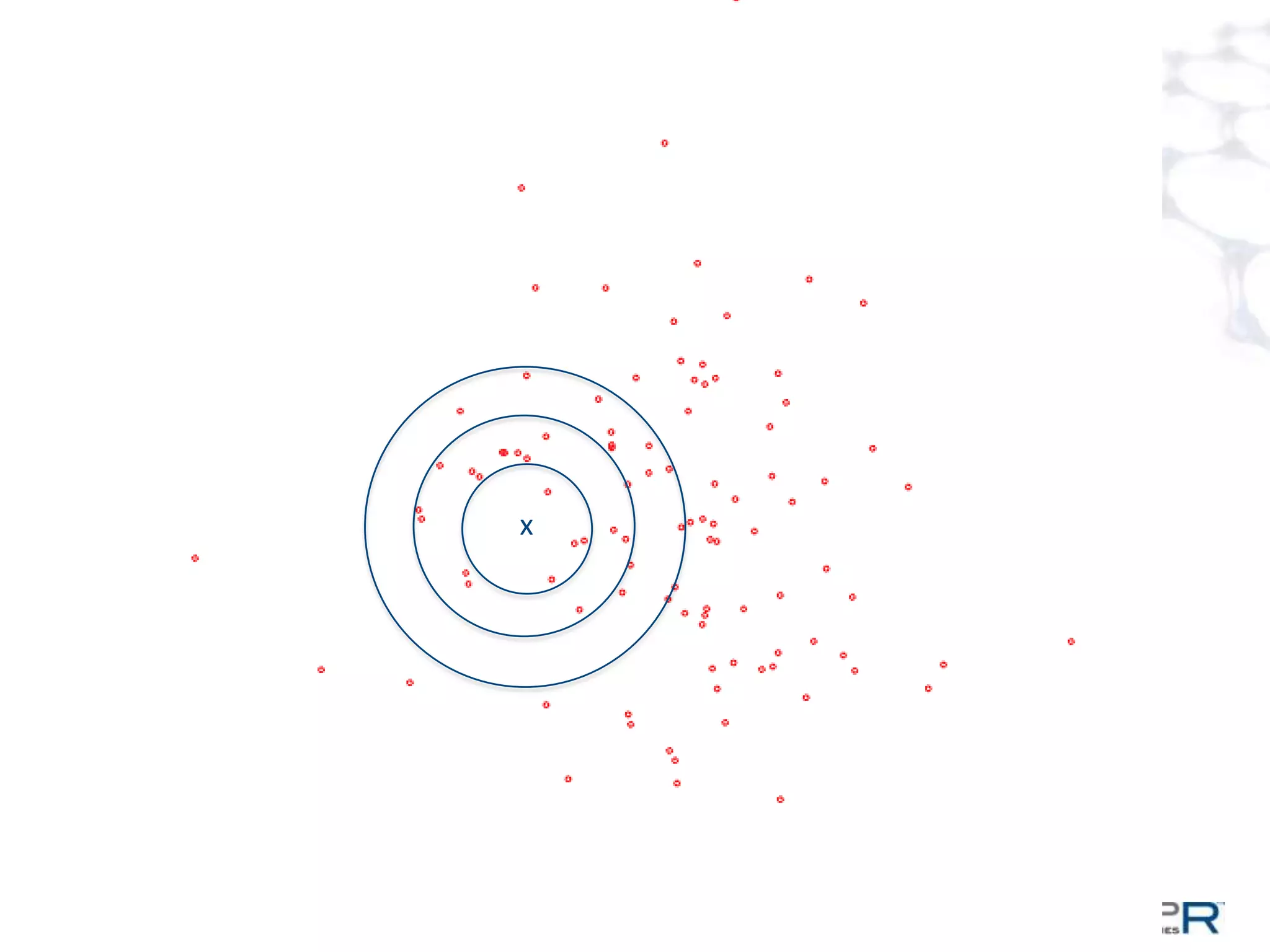
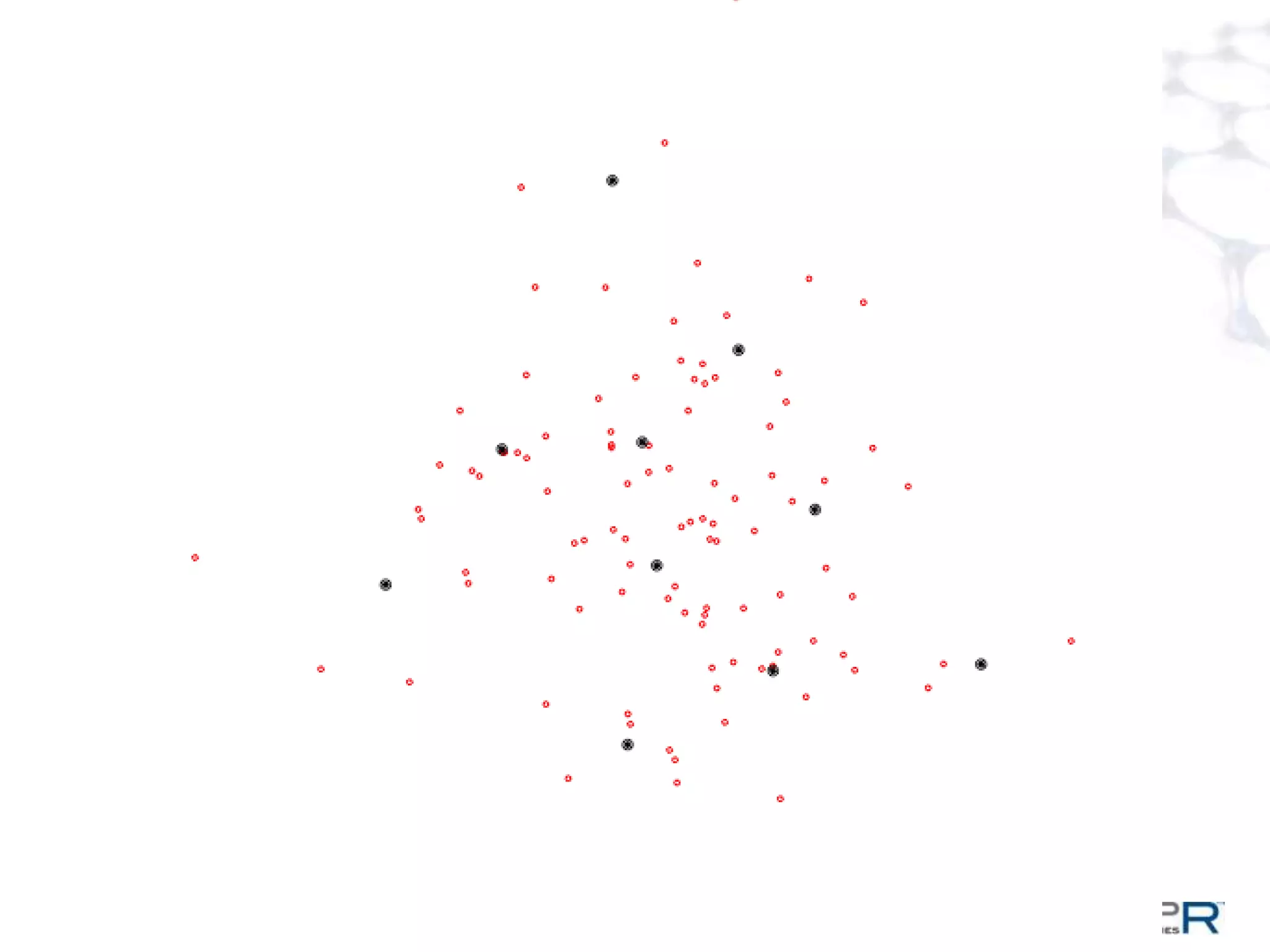
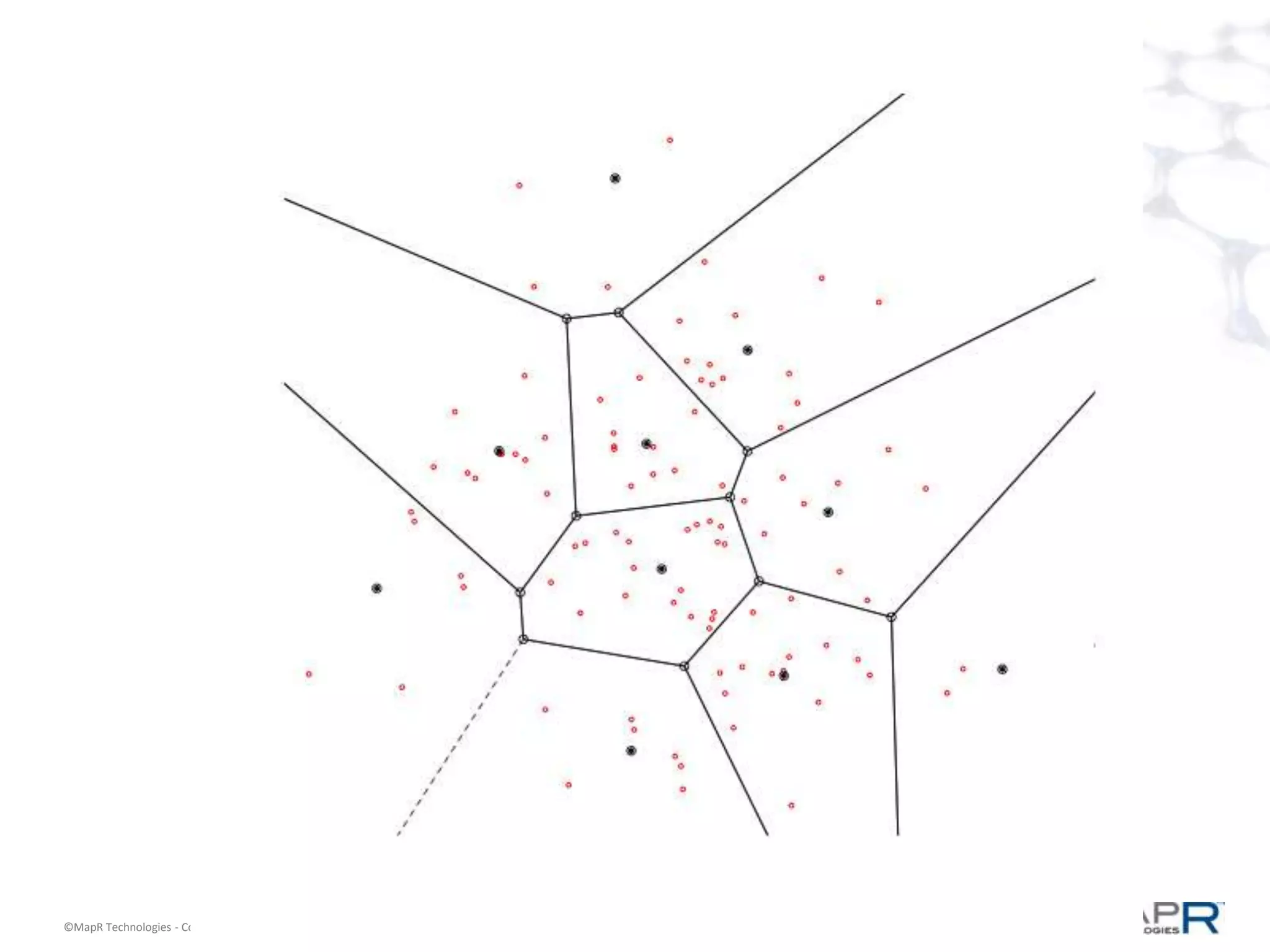
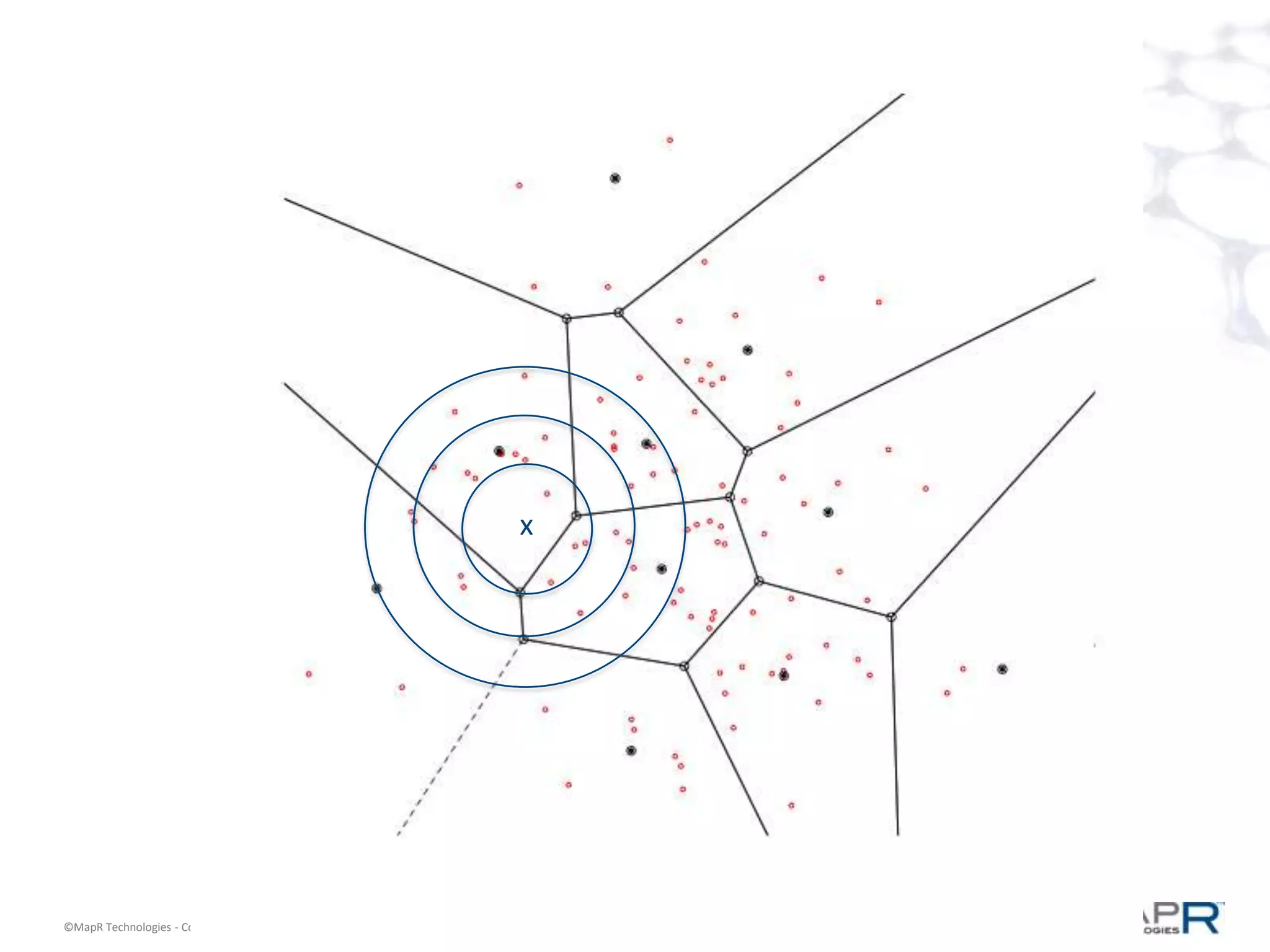
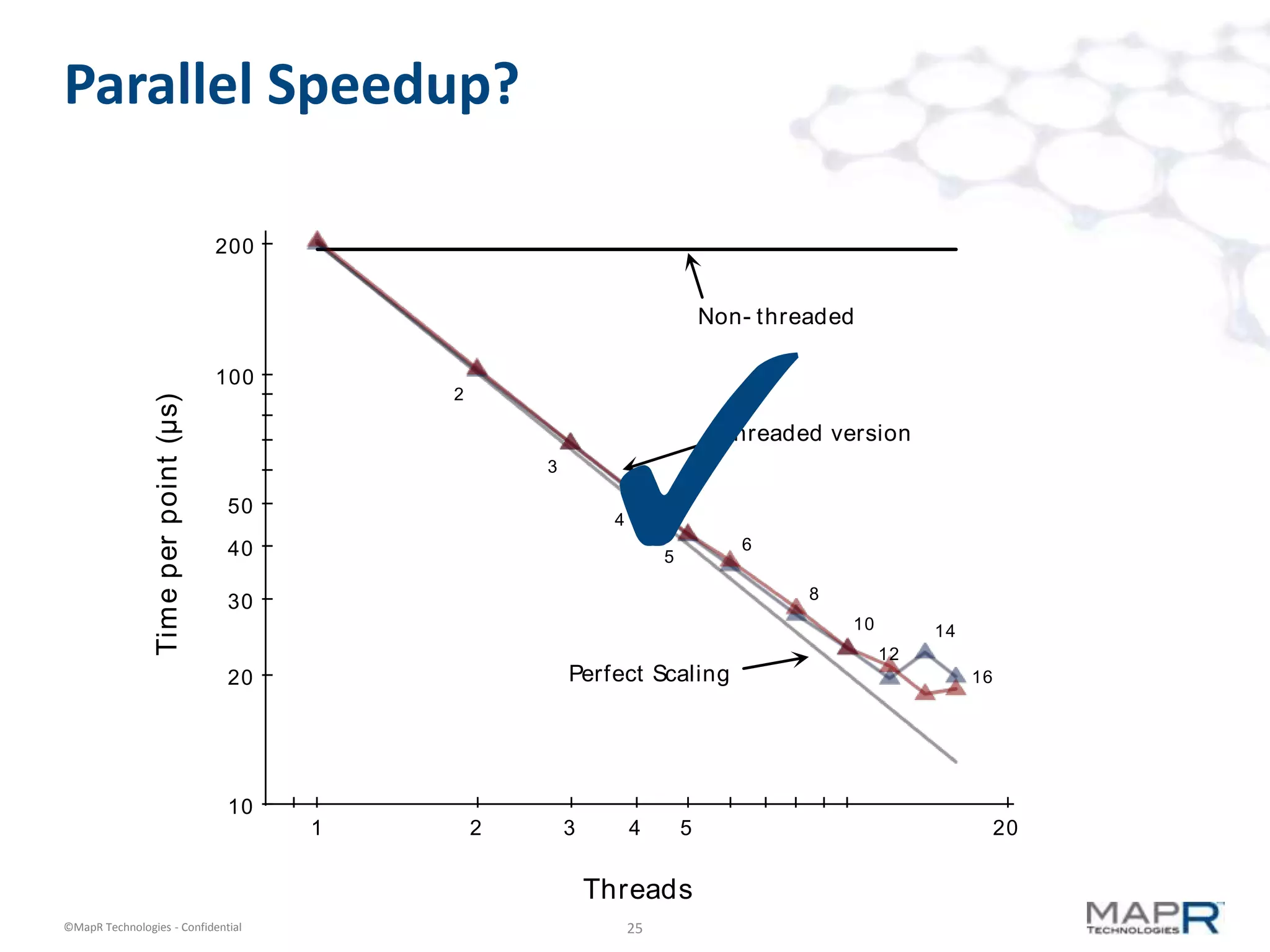
The document discusses a large-scale single-pass k-means clustering technique designed to handle very large datasets, enabling fast clustering of data for nearest neighbor search without relying on traditional map-reduce methods. It outlines the challenges and goals of the project, which include achieving high speed and quality in clustering while minimizing data processing time. Developed through a collaborative effort during a two-week hackathon, the method involves innovative approaches to cluster numerous data points efficiently and outputs a set of weighted centroids for better clustering accuracy.





































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






