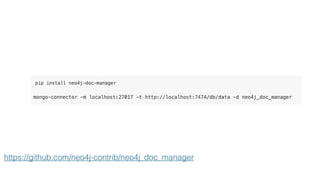
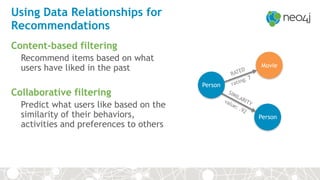
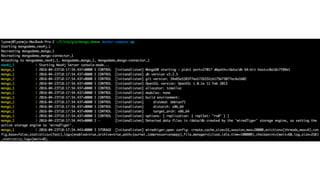
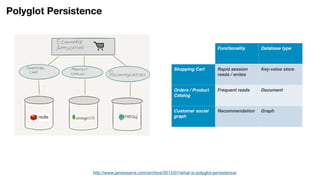
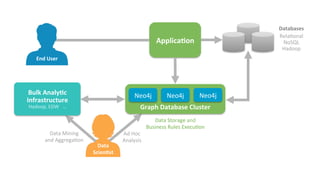
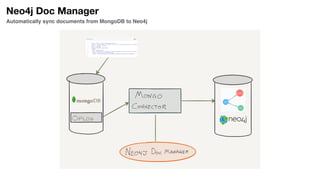
The document discusses the integration of Neo4j and MongoDB, highlighting their distinct features and use cases in polyglot persistence. Neo4j is presented as a graph database capable of handling complex relationships through its Cypher query language, while MongoDB offers a flexible document-based model. The content addresses real-time recommendations, master data management, and the syncing of data between the two databases using tools like the Neo4j Doc Manager.












![MongoDB
Features
• NoSQL database
• Document datamodel
• JSON-like documents (BSON)
• Flexible data model
• Horizontal scalability (sharding)
• Complex queries
{
"session": {
"title": "12 Years of Spring: An Open Source Journey",
"abstract": "Spring emerged as a core open source project in early 2003 and
evolved to a broad portfolio of open source projects up until 2015."
},
"topics": [
"keynote",
"spring"
],
"room": "Auditorium",
"timeslot": "Wed 29th, 09:30-10:30",
"speaker": {
"name": "Juergen Hoeller",
"bio": "Juergen Hoeller is co-founder of the Spring Framework open source
project.",
"twitter": "https://twitter.com/springjuergen",
"picture": "http://www.springio.net/wp-content/uploads/2014/11/
juergen_hoeller-220x220.jpeg"
}
}](https://image.slidesharecdn.com/mongowebinar6-160707212008/85/Polyglot-Persistence-with-MongoDB-and-Neo4j-12-320.jpg)
![MongoDB
Use Cases
• Product catalog
• User profiles
• Metadata
• Content
• Events
• Analytics
{
"session": {
"title": "12 Years of Spring: An Open Source Journey",
"abstract": "Spring emerged as a core open source project in early 2003 and
evolved to a broad portfolio of open source projects up until 2015."
},
"topics": [
"keynote",
"spring"
],
"room": "Auditorium",
"timeslot": "Wed 29th, 09:30-10:30",
"speaker": {
"name": "Juergen Hoeller",
"bio": "Juergen Hoeller is co-founder of the Spring Framework open source
project.",
"twitter": "https://twitter.com/springjuergen",
"picture": "http://www.springio.net/wp-content/uploads/2014/11/
juergen_hoeller-220x220.jpeg"
}
}
https://www.mongodb.com/use-cases/](https://image.slidesharecdn.com/mongowebinar6-160707212008/85/Polyglot-Persistence-with-MongoDB-and-Neo4j-13-320.jpg)
![MongoDB
Use Cases
• Product catalog
• User profiles
• Metadata
• Content
• Events
• Analytics
{
"session": {
"title": "12 Years of Spring: An Open Source Journey",
"abstract": "Spring emerged as a core open source project in early 2003 and
evolved to a broad portfolio of open source projects up until 2015."
},
"topics": [
"keynote",
"spring"
],
"room": "Auditorium",
"timeslot": "Wed 29th, 09:30-10:30",
"speaker": {
"name": "Juergen Hoeller",
"bio": "Juergen Hoeller is co-founder of the Spring Framework open source
project.",
"twitter": "https://twitter.com/springjuergen",
"picture": "http://www.springio.net/wp-content/uploads/2014/11/
juergen_hoeller-220x220.jpeg"
}
}
https://www.mongodb.com/use-cases/](https://image.slidesharecdn.com/mongowebinar6-160707212008/85/Polyglot-Persistence-with-MongoDB-and-Neo4j-14-320.jpg)

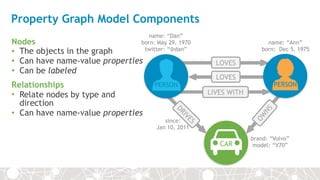
![Cypher: SQL for graphs
CREATE (:Person { name:“Dan”} ) -[:LOVES]-> (:Person { name:“Ann”} )
LOVES
Dan Ann
LABEL PROPERTY
NODE NODE
LABEL PROPERTY](https://image.slidesharecdn.com/mongowebinar6-160707212008/85/Polyglot-Persistence-with-MongoDB-and-Neo4j-17-320.jpg)

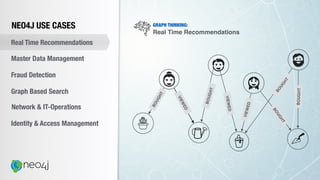
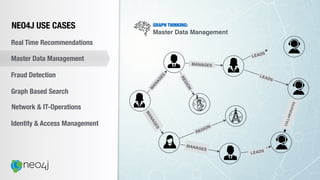
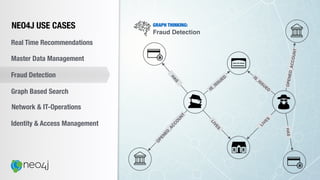
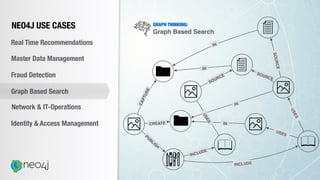












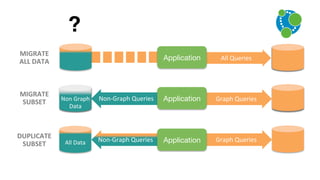
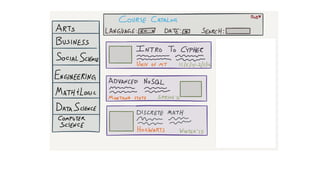
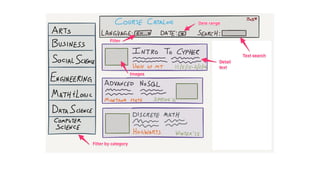
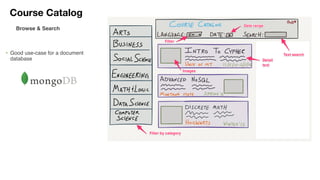

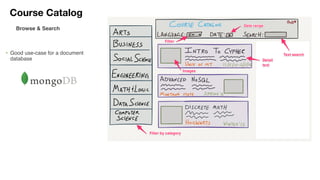
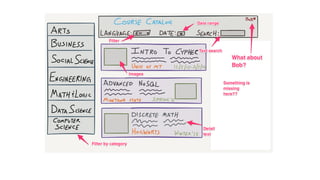
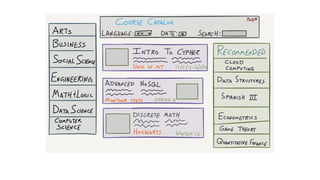
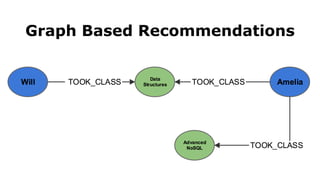
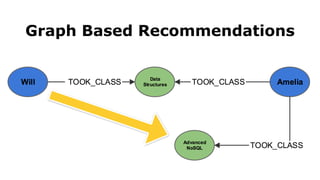





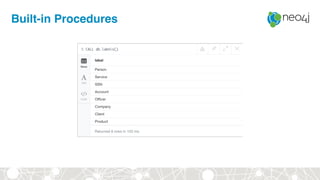







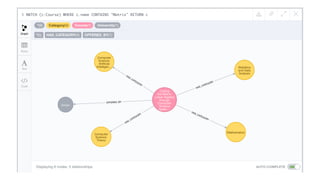



![Document to property graph
{
"session": {
"title": "12 Years of Spring: An Open Source Journey",
"abstract": "Spring emerged as a core open source
project in early 2003 and evolved to a broad portfolio of
open source projects up until 2015."
},
"topics": [
"keynote",
"spring"
],
"room": "Auditorium",
"timeslot": "Wed 29th, 09:30-10:30",
"speaker": {
"name": "Juergen Hoeller",
"bio": "Juergen Hoeller is co-founder of the Spring
Framework open source project.",
"twitter": "https://twitter.com/springjuergen",
"picture": "http://www.springio.net/wp-content/
uploads/2014/11/juergen_hoeller-220x220.jpeg"
}
}](https://image.slidesharecdn.com/mongowebinar6-160707212008/85/Polyglot-Persistence-with-MongoDB-and-Neo4j-78-320.jpg)
![{
"session": {
"title": "12 Years of Spring: An Open Source Journey",
"abstract": "Spring emerged as a core open source
project in early 2003 and evolved to a broad portfolio of
open source projects up until 2015."
},
"topics": [
"keynote",
"spring"
],
"room": "Auditorium",
"timeslot": "Wed 29th, 09:30-10:30",
"speaker": {
"name": "Juergen Hoeller",
"bio": "Juergen Hoeller is co-founder of the Spring
Framework open source project.",
"twitter": "https://twitter.com/springjuergen",
"picture": "http://www.springio.net/wp-content/
uploads/2014/11/juergen_hoeller-220x220.jpeg"
}
}
Document to property graph](https://image.slidesharecdn.com/mongowebinar6-160707212008/85/Polyglot-Persistence-with-MongoDB-and-Neo4j-79-320.jpg)