Downloaded 21 times




















![References
34
[1] D. J. Abadi, A. Marcus, S. R. Madden, and K. Hollenbach, "Scalable semantic web data
management using vertical partitioning," in Proceedings of the 33rd international conference on Very large
data bases, 2007, pp. 411-422.
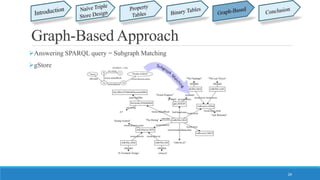
[2] L. Zou, J. Mo, L. Chen, M. T. Özsu, and D. Zhao, "gStore: answering SPARQL queries via
subgraph matching," Proceedings of the VLDB Endowment, vol. 4, pp. 482-493, 2011.
[3] L. Zou, M. T. Özsu, L. Chen, X. Shen, R. Huang, and D. Zhao, "gStore: a graph-based SPARQL
query engine," The VLDB Journal—The International Journal on Very Large Data Bases, vol. 23, pp. 565-
590, 2014.
[4] X. Shen, L. Zou, M. T. Ozsu, L. Chen, Y. Li, S. Han, et al., "A Graph-based RDF Triple Store."](https://image.slidesharecdn.com/navidsedighpourpresentation-160516115629/85/Scalable-Web-Data-Management-using-RDF-34-320.jpg)


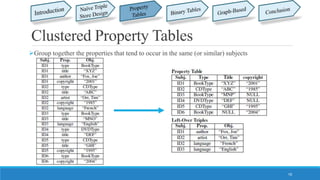
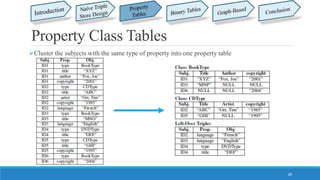
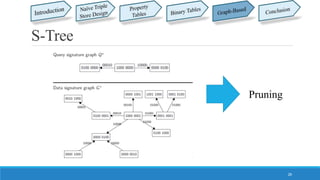
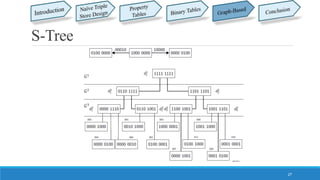
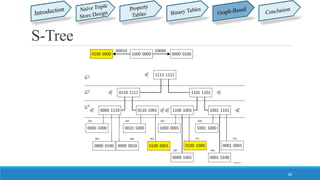
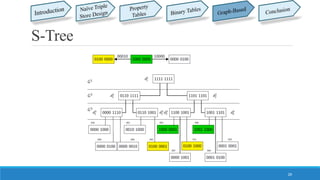
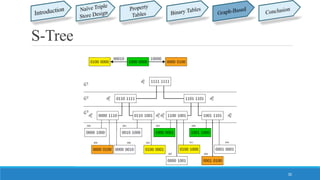
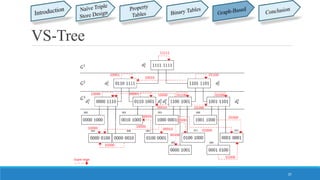
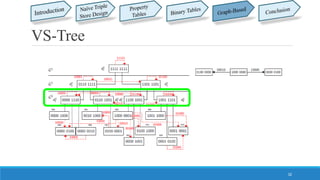
This document summarizes different approaches for managing web data and querying semi-structured data. It discusses challenges like lack of schemas, scale, and volatility of web data. It then describes approaches like property tables, binary tables, and graph-based approaches using the gStore and VS-Tree systems. The document concludes that graph-based approaches like VS-Tree have the best performance and that gStore is more efficient than other approaches for querying RDF triple stores on the web.



































































