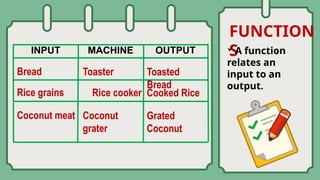
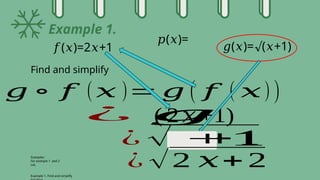
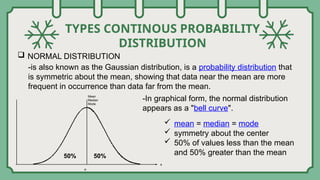
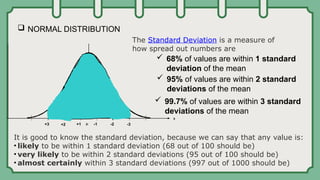
The document explores composite functions, their applications in real-life scenarios such as the discovery of penicillin, and various probability distributions including binomial, Bernoulli, and Poisson distributions. Each distribution is explained with examples illustrating their significance in fields like education and statistics. Additionally, it discusses continuous probability distributions like normal distribution, including its characteristics and formulas.