Download to read offline



![2
Where the value represented in this definition is a whitespace-separated list of
items, each of which is the string value of an ISO3166 (ISO3166-2), defined
elsewhere in the Open Travel Schema set. So, given that ISO3166 is defined as:
<xs:simpleType name="ISO3166">
<xs:annotation>
<xs:documentation xml:lang="en">Specifies a 2 character country code as defined in
ISO3166.</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:string">
<xs:pattern value="[a-zA-Z]{2}"/>
</xs:restriction>
</xs:simpleType>
Where the restriction is now defined by a Regex pattern, based on the W3C
Primitive “xs:string”, and hence a valid value for ListOfISO3166 would be:
“UK DE IT FR”
In addition, in the Open Travel set, we can find a SimpleType involving a Union,
TimeOrDateTimeType:
<xs:simpleType name="TimeOrDateTimeType">
<xs:annotation>
<xs:documentation xml:lang="en">Allows for the specification of a date time or just
time.</xs:documentation>
</xs:annotation>
<xs:union memberTypes="xs:dateTime xs:time"/>
</xs:simpleType>
Here we see a pair of entities, “xs:dateTime” and “xs:time”, types from the W3C
Primitive family, which can occupy the object “TimeOrDateTimeType”, but only one of
these may be referenced at any one time.
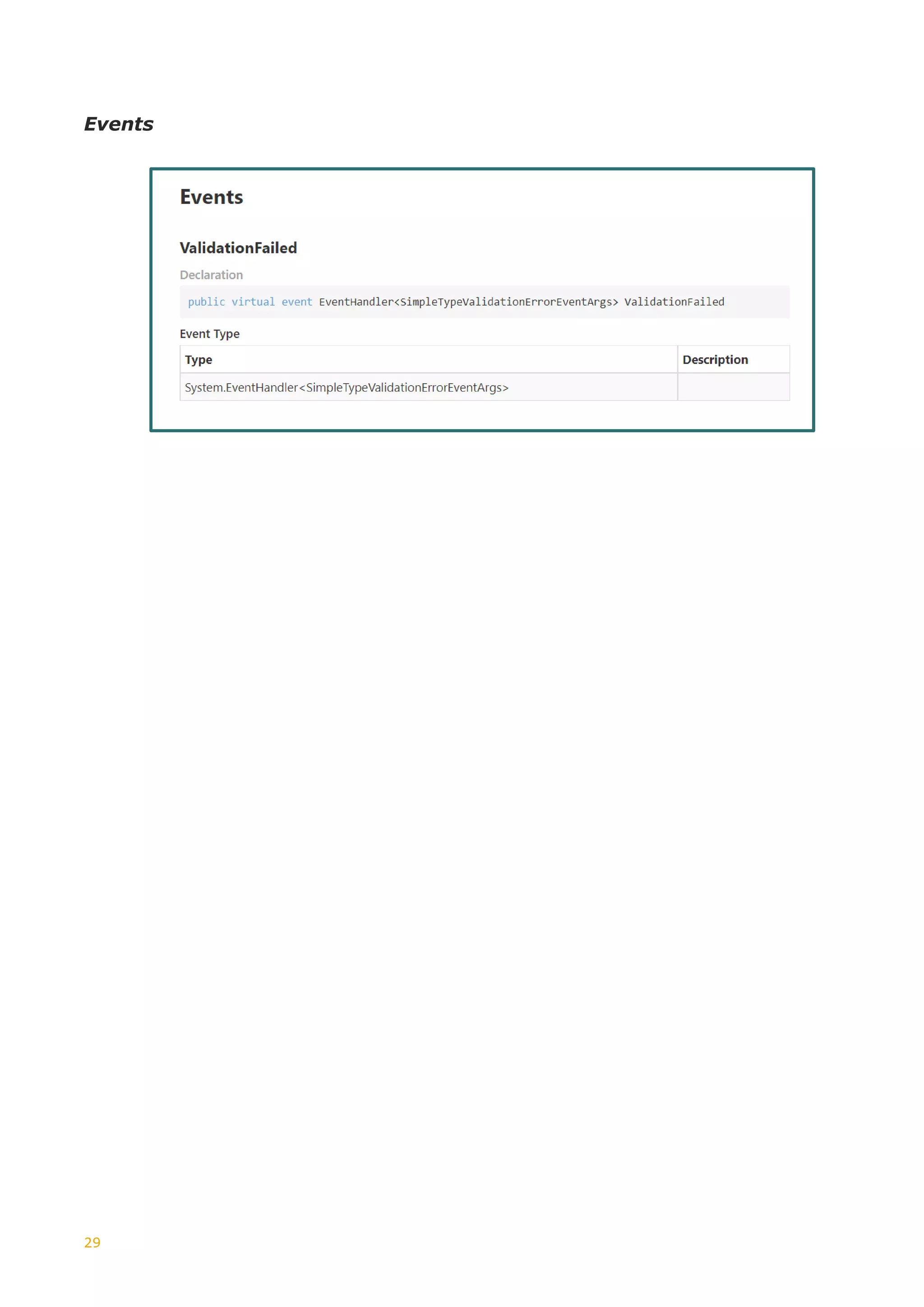
As noted in the previous article, the Choice and Union W3C Schema idioms are not
reflected in modern strong typed languages such as C#, Java or Kotlin.
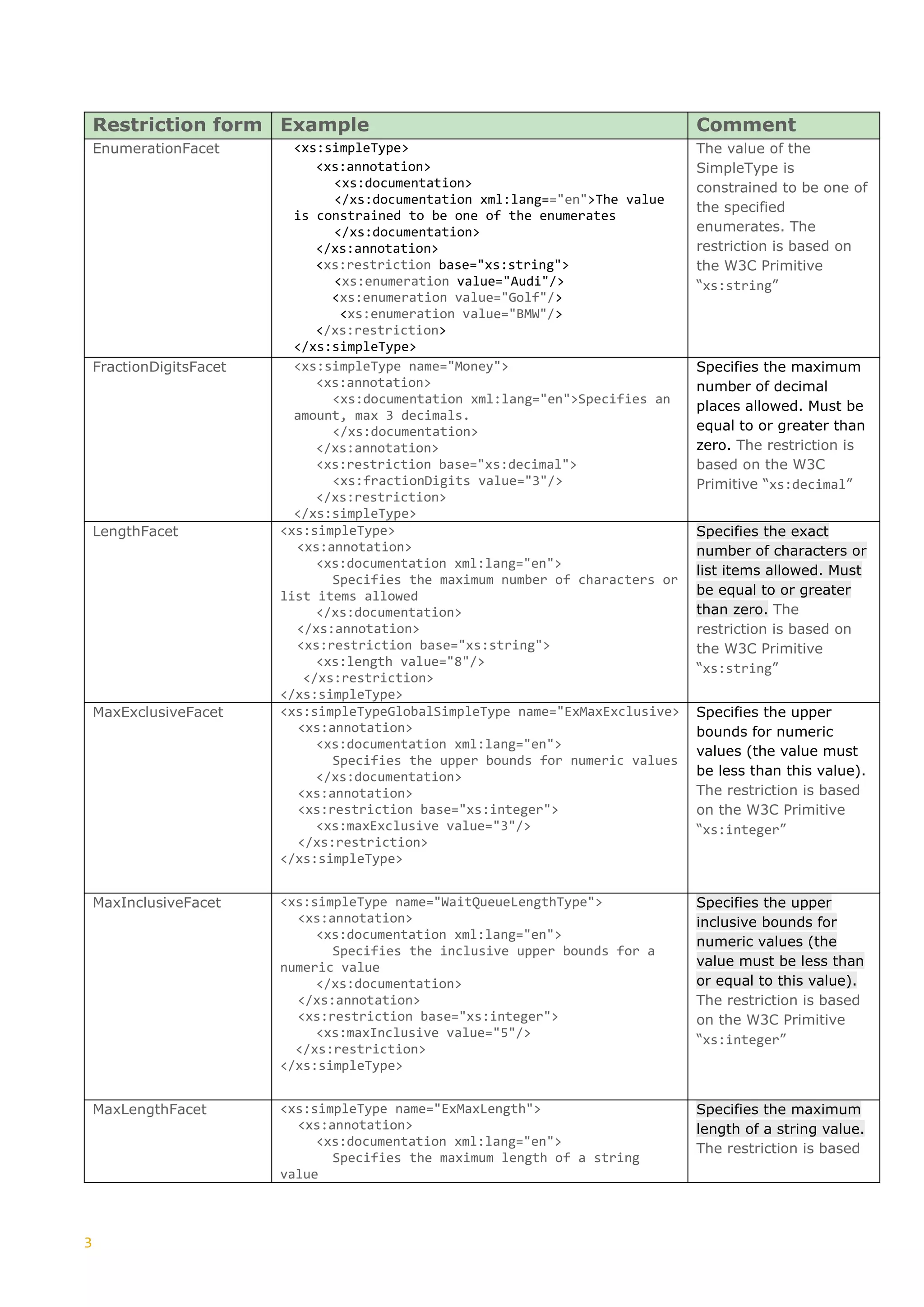
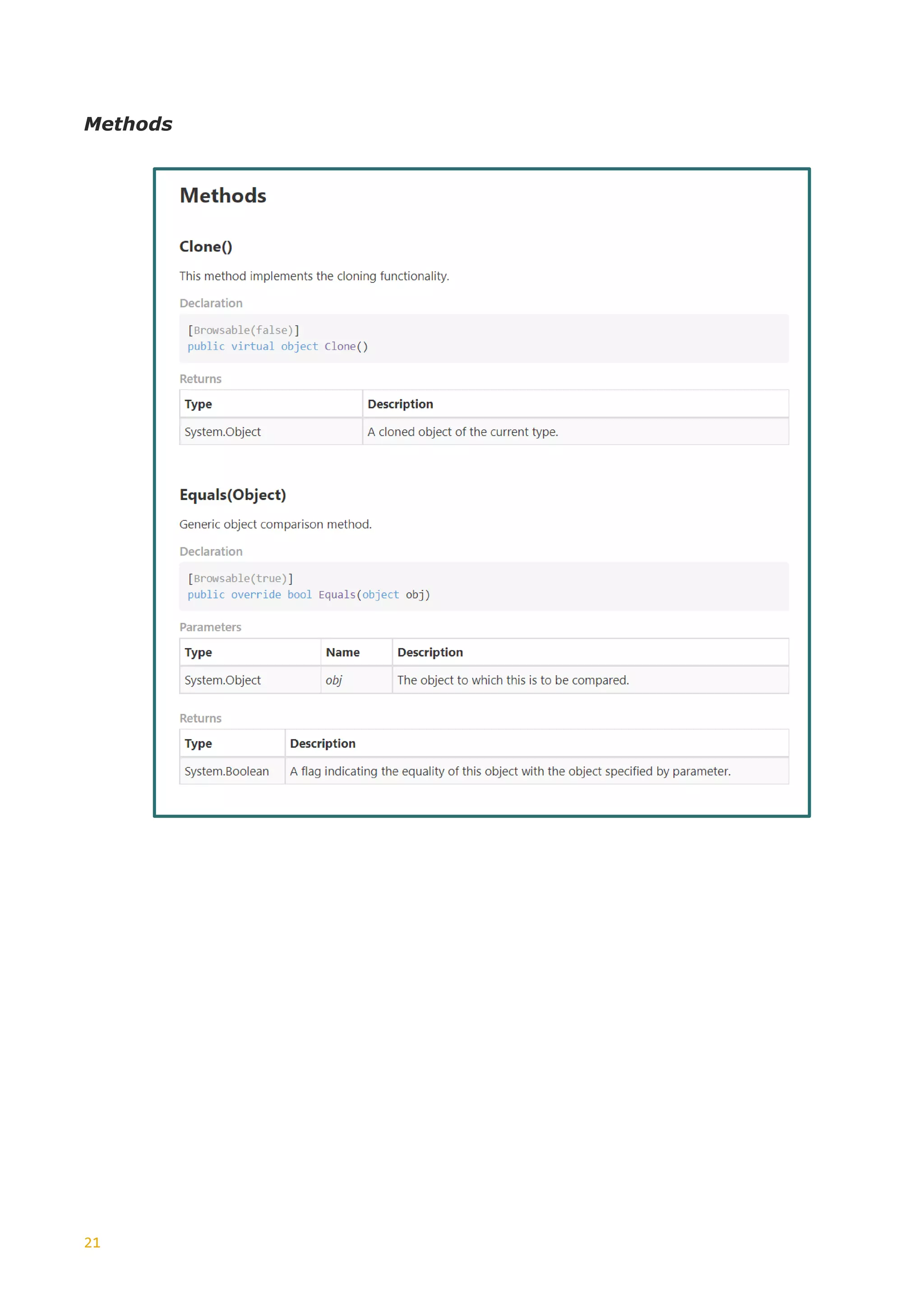
RESTRICTIONS
In the previous section, we encountered the SimpleType component, “restriction”.
In particular, we highlighted the “minLength” and “pattern” forms.
These are only two of the possible restriction forms, restriction facets, which can be
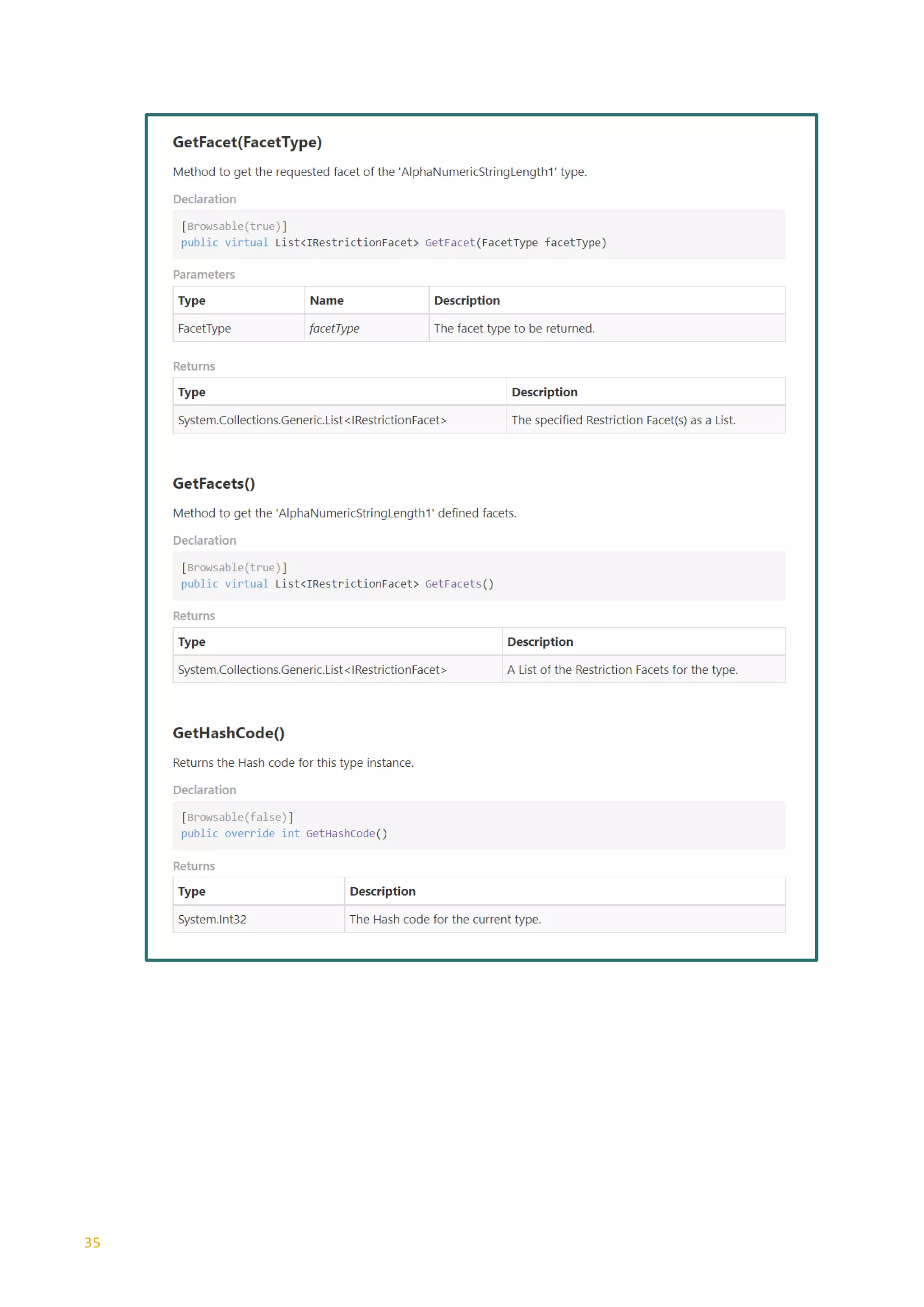
applied to specify the range of valid values for a SimpleType. The table below shows
the extent of such restriction facets:](https://image.slidesharecdn.com/generationxsdarticle-part2-220828151558-67e96f7b/75/Generation_XSD_Article-Part-2-pdf-4-2048.jpg)
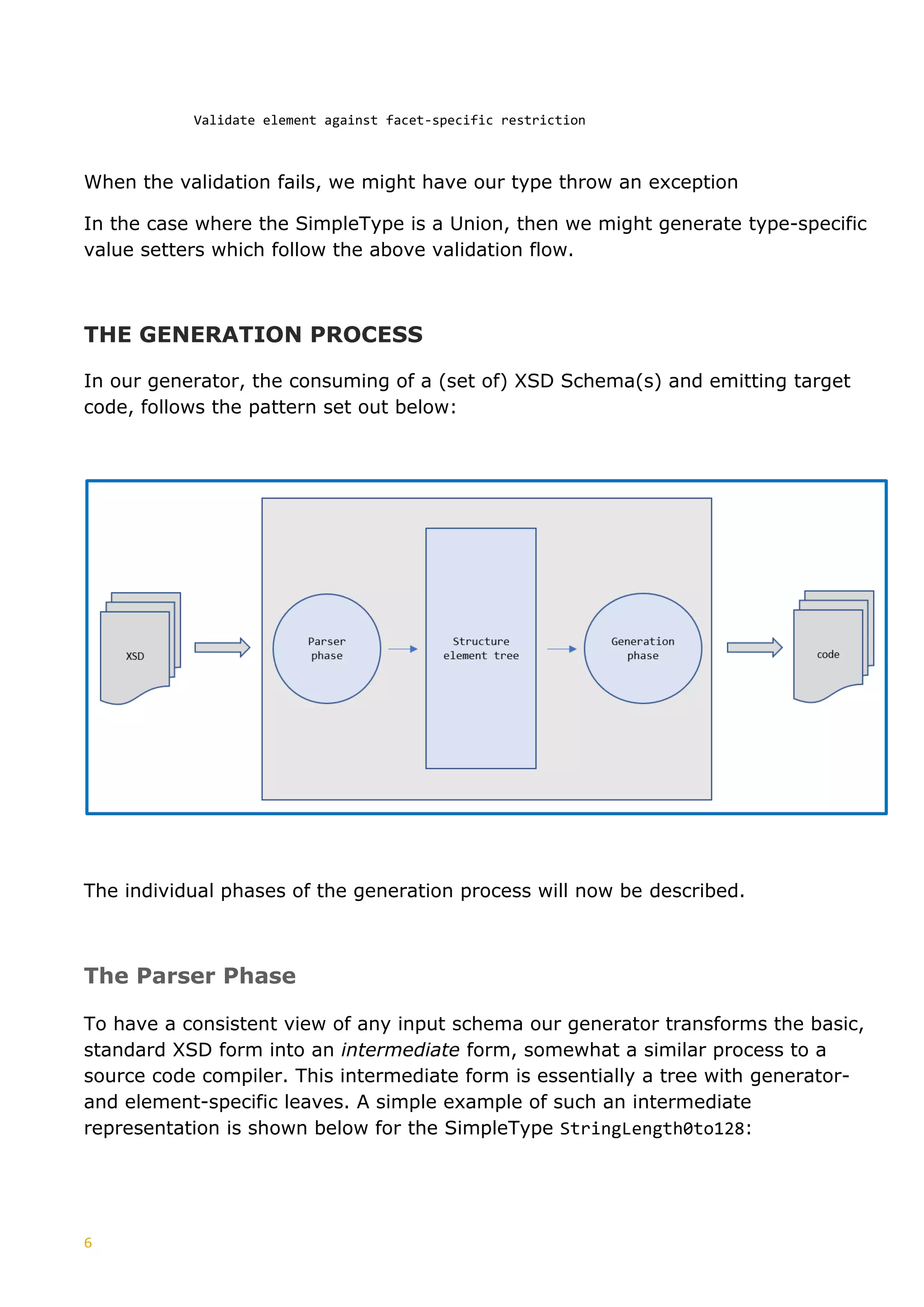
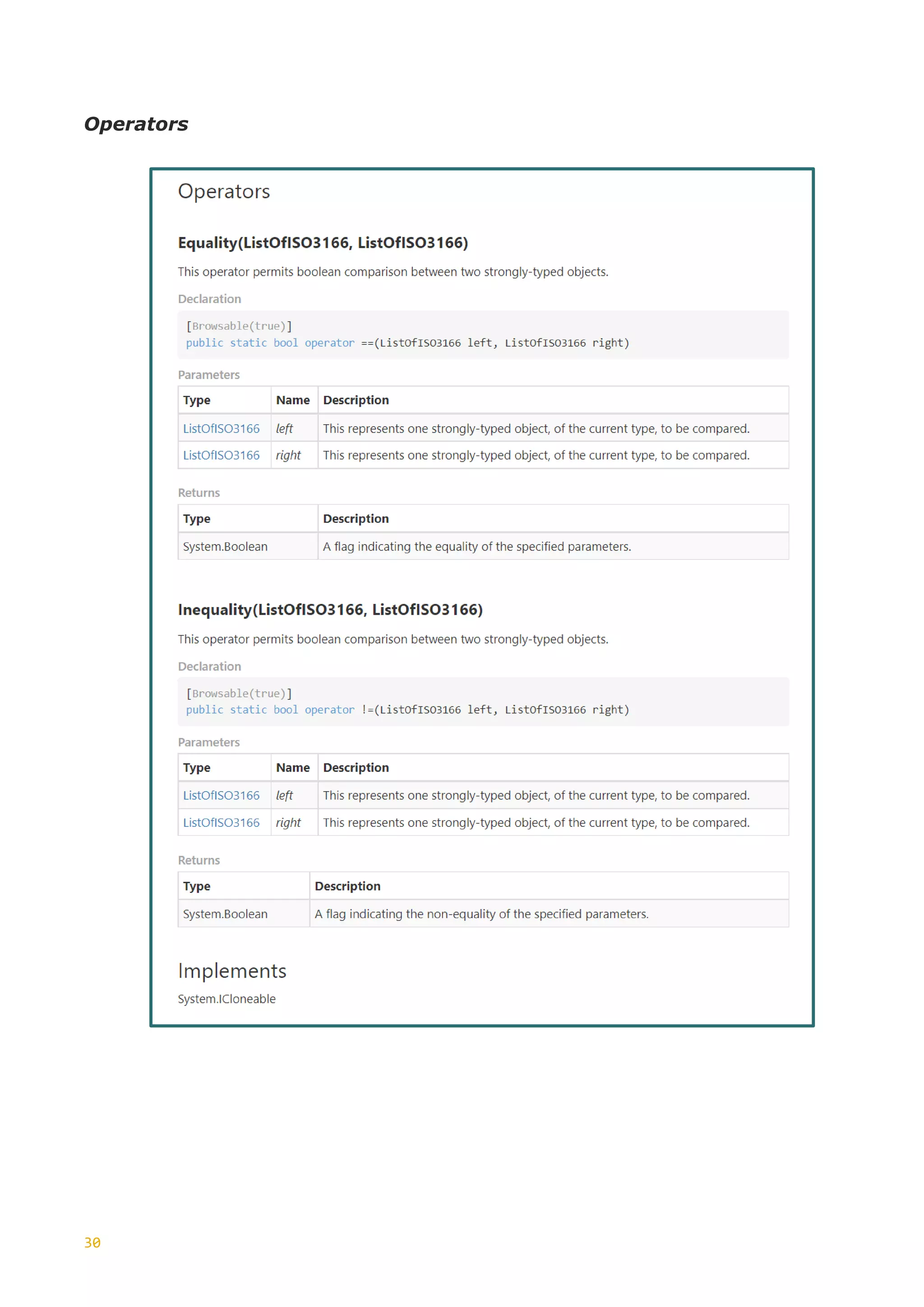
![4
</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:string">
<xs:maxLength value="12"/>
</xs:restriction>
</xs:simpleType>
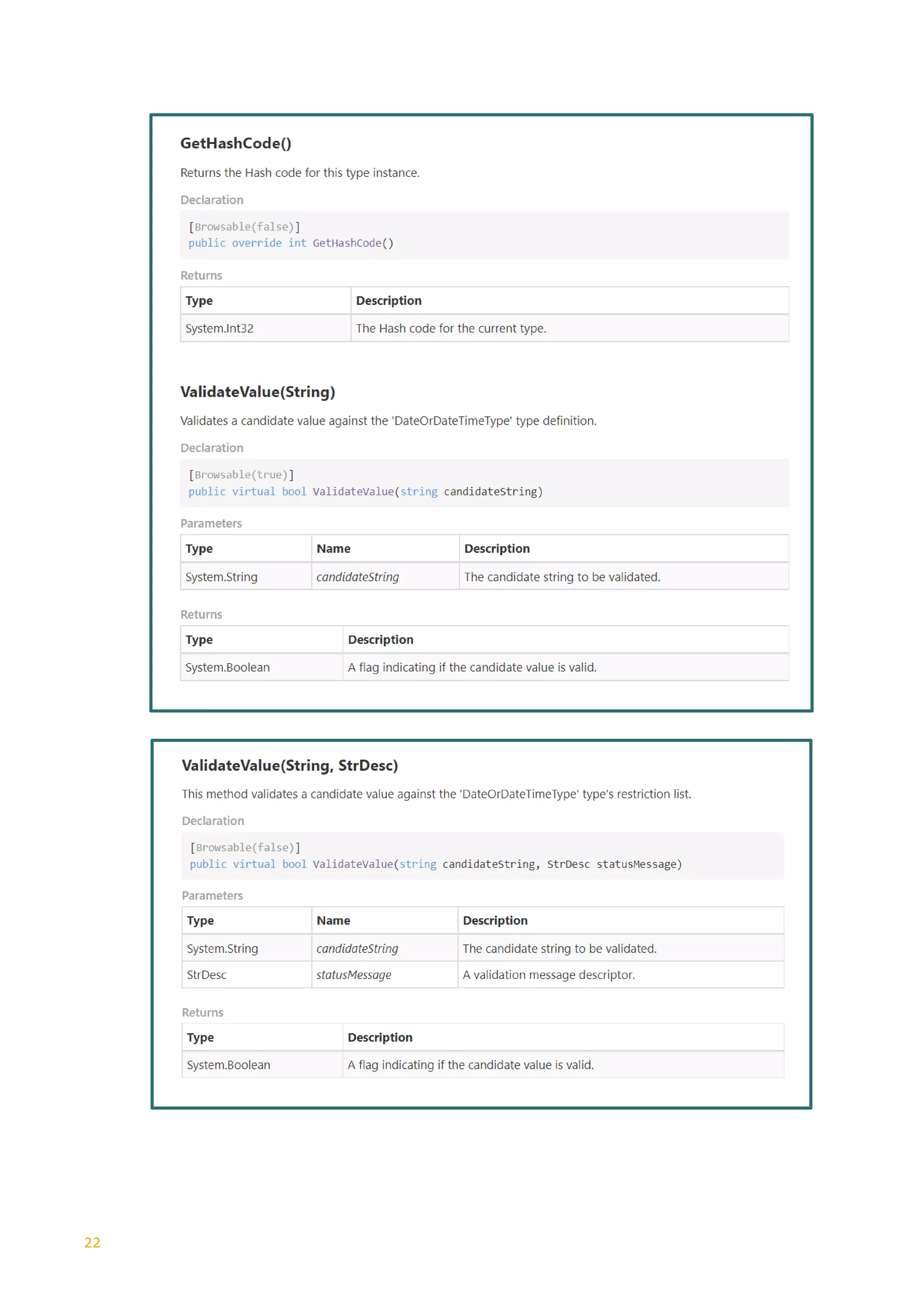
on the W3C Primitive
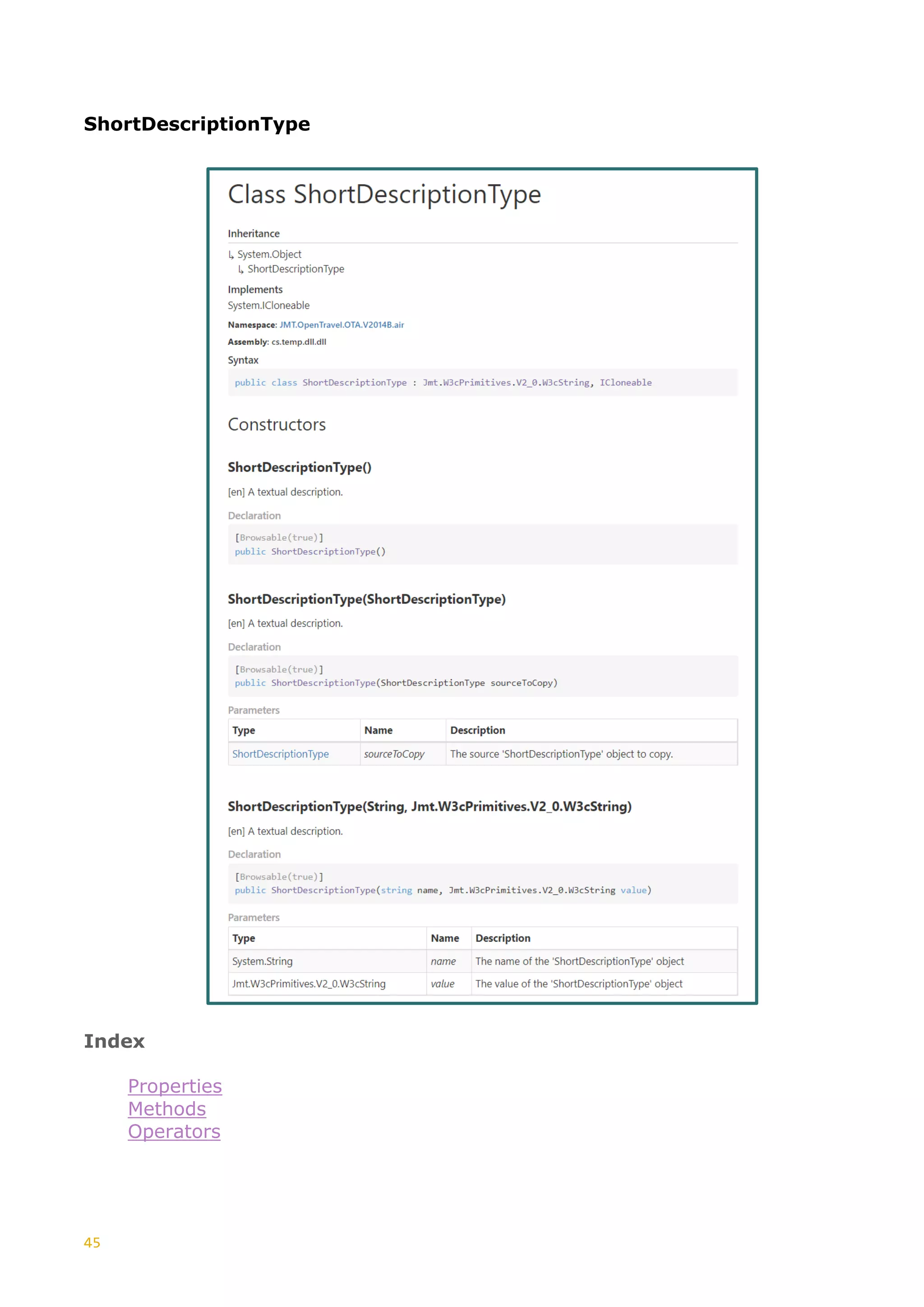
“xs:string”
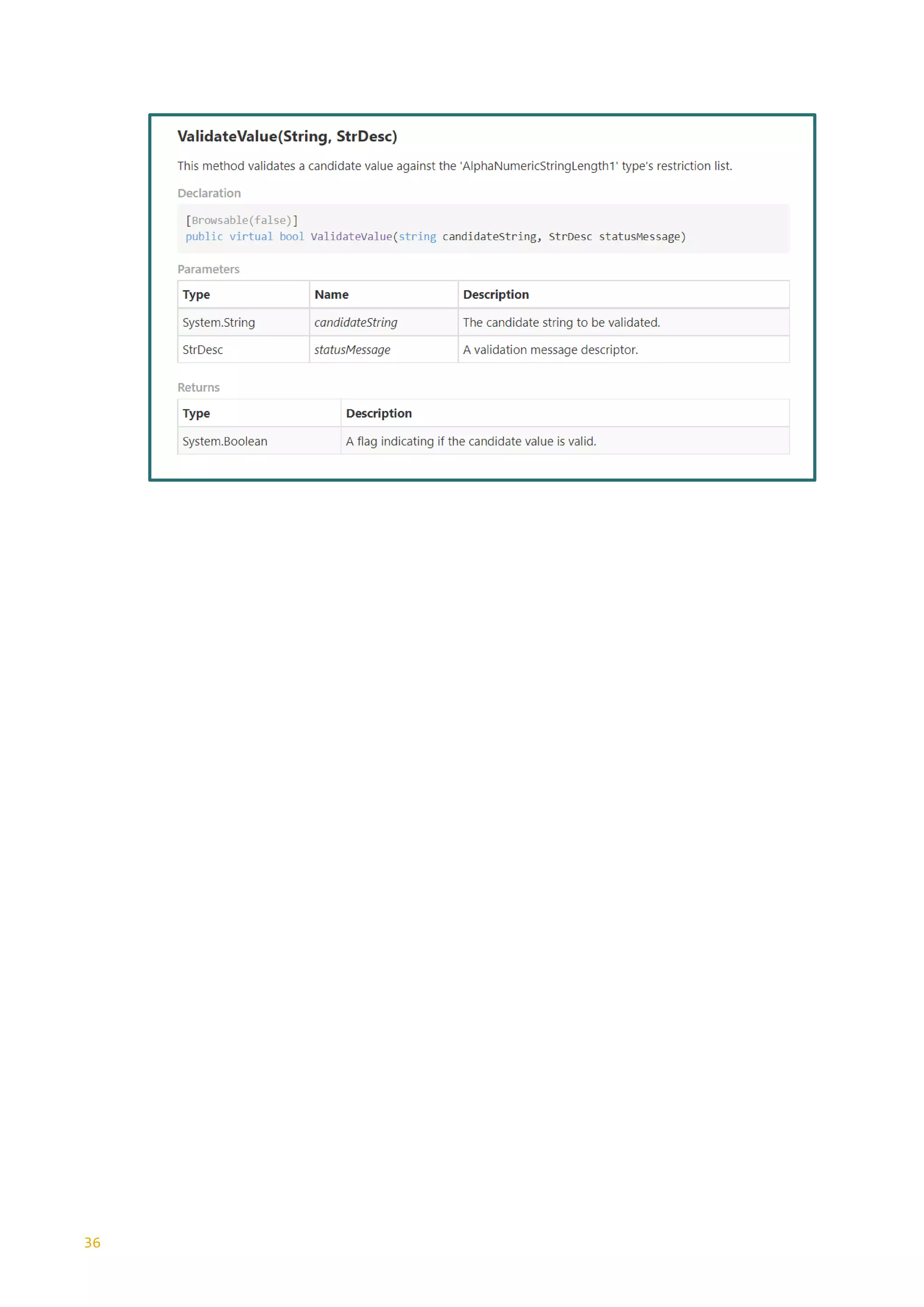
MinExlusiveFacet <xs:simpleType name="ExMinExclusive">
<xs:annotation>
<xs:documentation xml:lang="en">
Specifies the minimum exclusive bound for a
numeric value
</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:integer">
<xs:minExclusive value="1" />
</xs:restriction>
</xs:simpleType>
Specifies the lower
bounds for numeric
values (the value must
be greater than this
value). The restriction is
based on the W3C
Primitive “xs:string”
MinInclusiveFacet <xs:simpleType name="ExMinInclusive">
<xs:annotation>
<xs:documentation xml:lang="en">
Specifies the lower inclusive bounds for a
numeric value
</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
Specifies the lower
bounds for numeric
values (the value must
be greater than or equal
to this value). The
restriction is based on
the W3C Primitive
“xs:integer”
MinLengthFacet <xs:simpleType name="StateProvCodeType">
<xs:annotation>
<xs:documentation xml:lang="en">The standard
code or abbreviation for the state, province, or
region.</xs:documentation>
</xs:annotation>
<xs:restriction base="StringLength1to8">
<xs:minLength value="2"/>
</xs:restriction>
</xs:simpleType>
Specifies the minimum
number of characters or
list items allowed. Must
be equal to or greater
than zero. The
restriction is based on
the OTA type
“StringLength1to8”
MinMaxLengthFacet <xs:simpleType name="StringLength0to255">
<xs:annotation>
<xs:documentation xml:lang="en">Used for
Character Strings, length 0 to
255.</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:string">
<xs:minLength value="0"/>
<xs:maxLength value="255"/>
</xs:restriction>
</xs:simpleType>
Specifies the minimum
inclusive and maximum
inclusive number of
characters or list items
allowed. The restriction
is based on the W3C
Primitive “xs:string”
PatternFacet <xs:simpleType>
<xs:annotation>
<xs:documentation xml:lang="en">
Defines, via a Regex expression, the exact
sequence of characters that are acceptable
</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:string">
<xs:pattern value="[a-zA-Z0-9]{8}"/>
</xs:restriction>
</xs:simpleType>
Defines the exact
sequence of characters
that are acceptable. The
restriction is based on
the W3C Primitive
“xs:string”](https://image.slidesharecdn.com/generationxsdarticle-part2-220828151558-67e96f7b/75/Generation_XSD_Article-Part-2-pdf-6-2048.jpg)

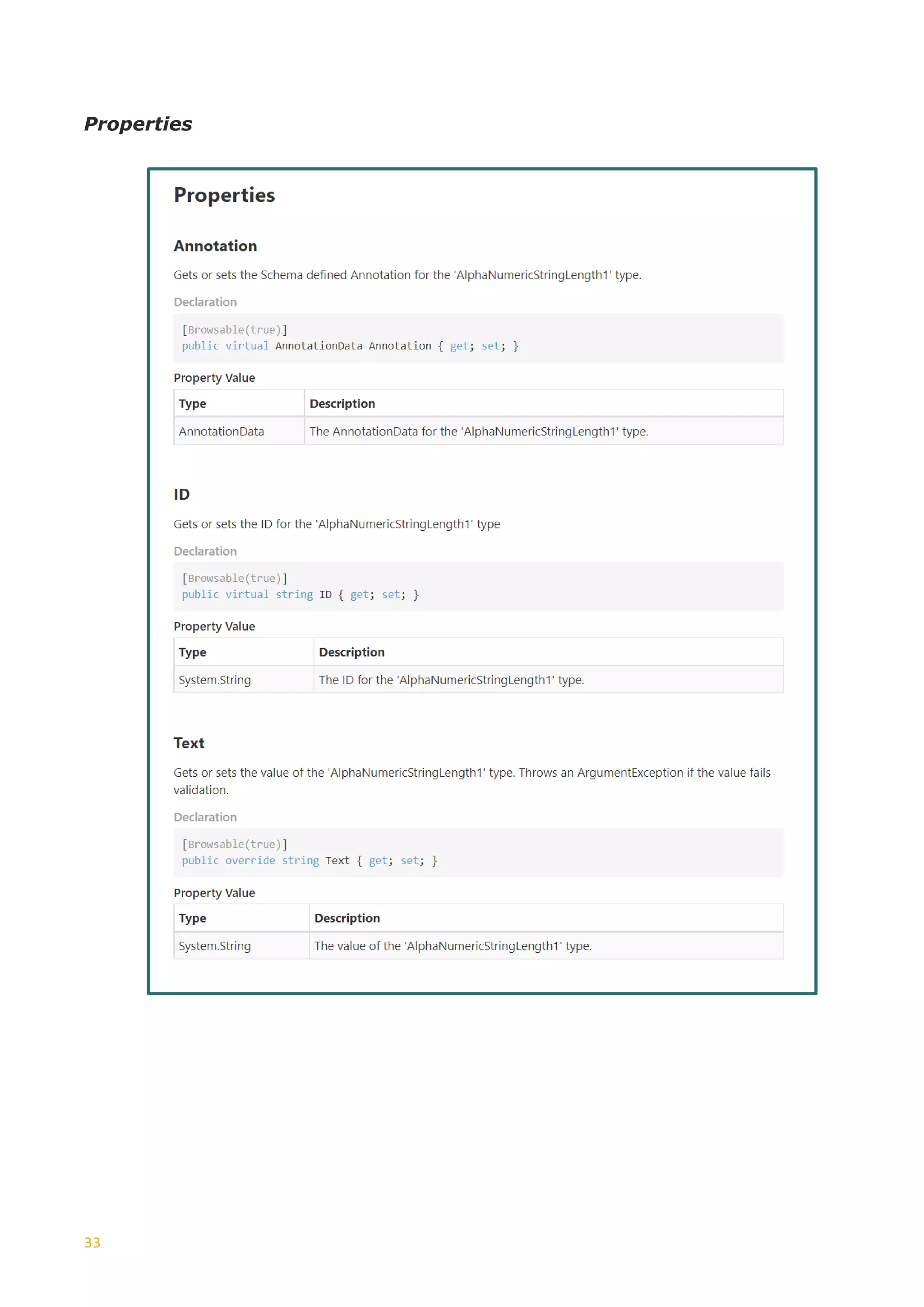
![7
XML
<xs:simpleType name="StringLength0to128">
<xs:annotation>
<xs:documentation xml:lang="en">Used for Character Strings, length 0 to 128.
</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:string">
<xs:minLength value="0"/>
<xs:maxLength value="128"/>
</xs:restriction>
</xs:simpleType>
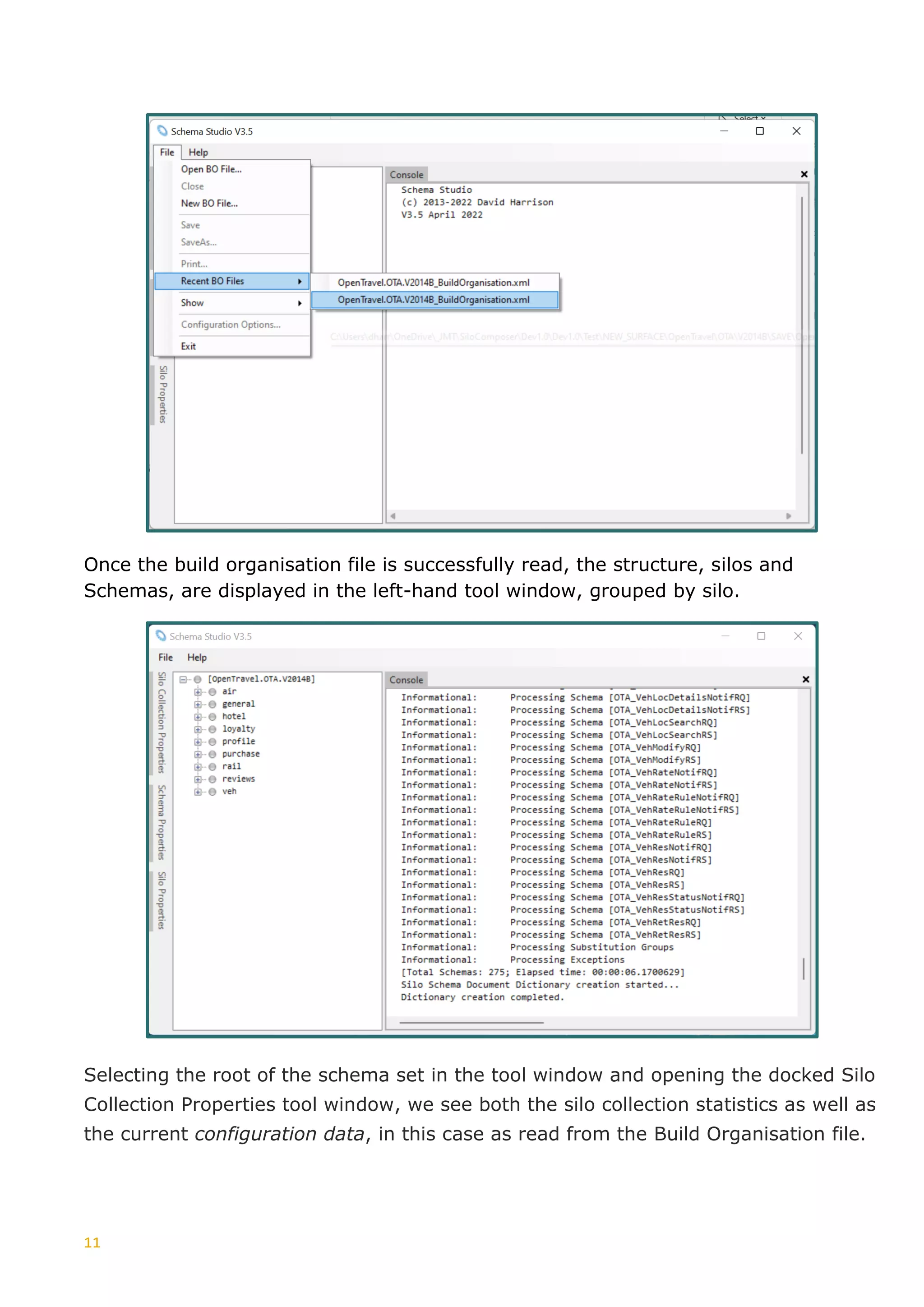
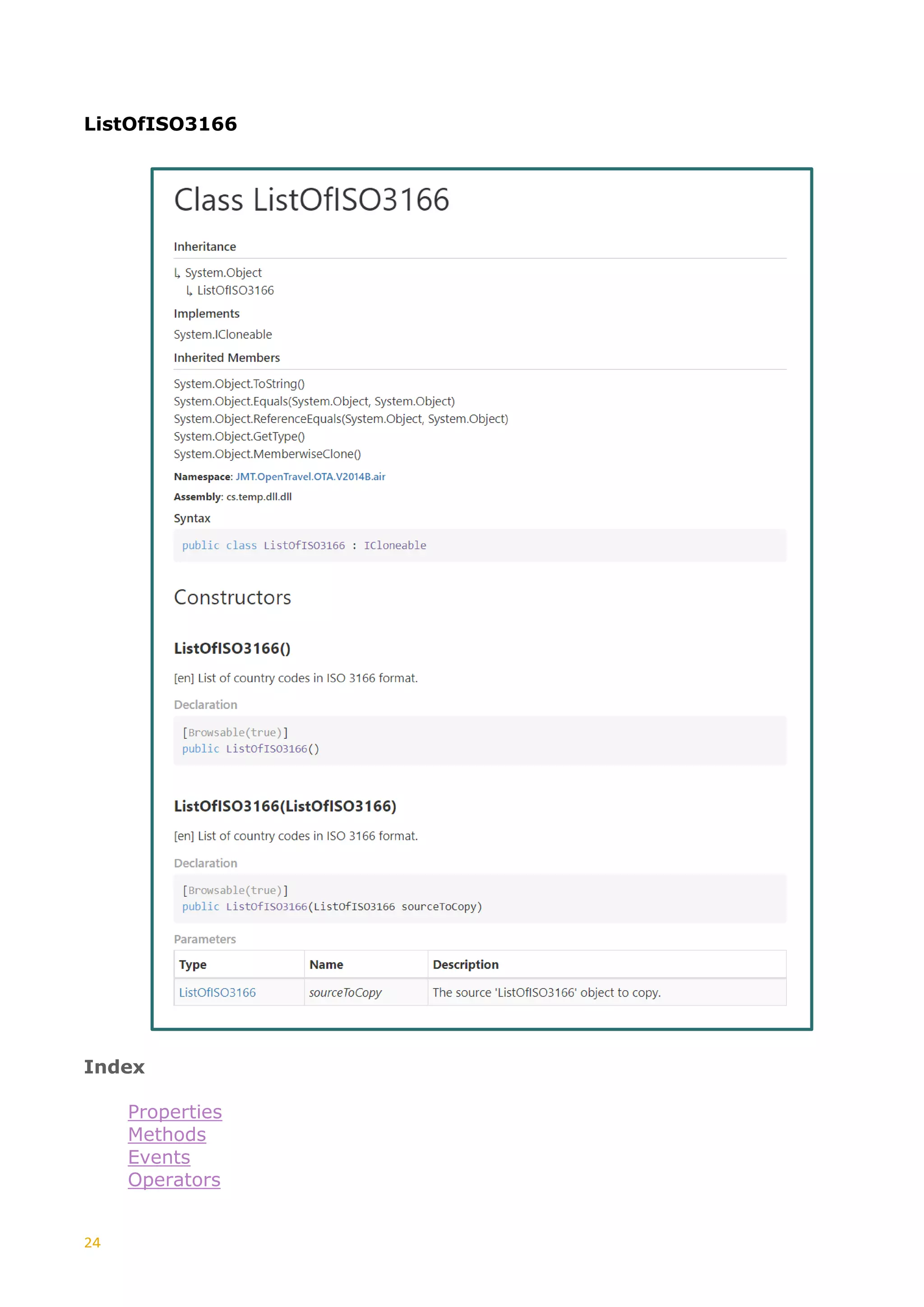
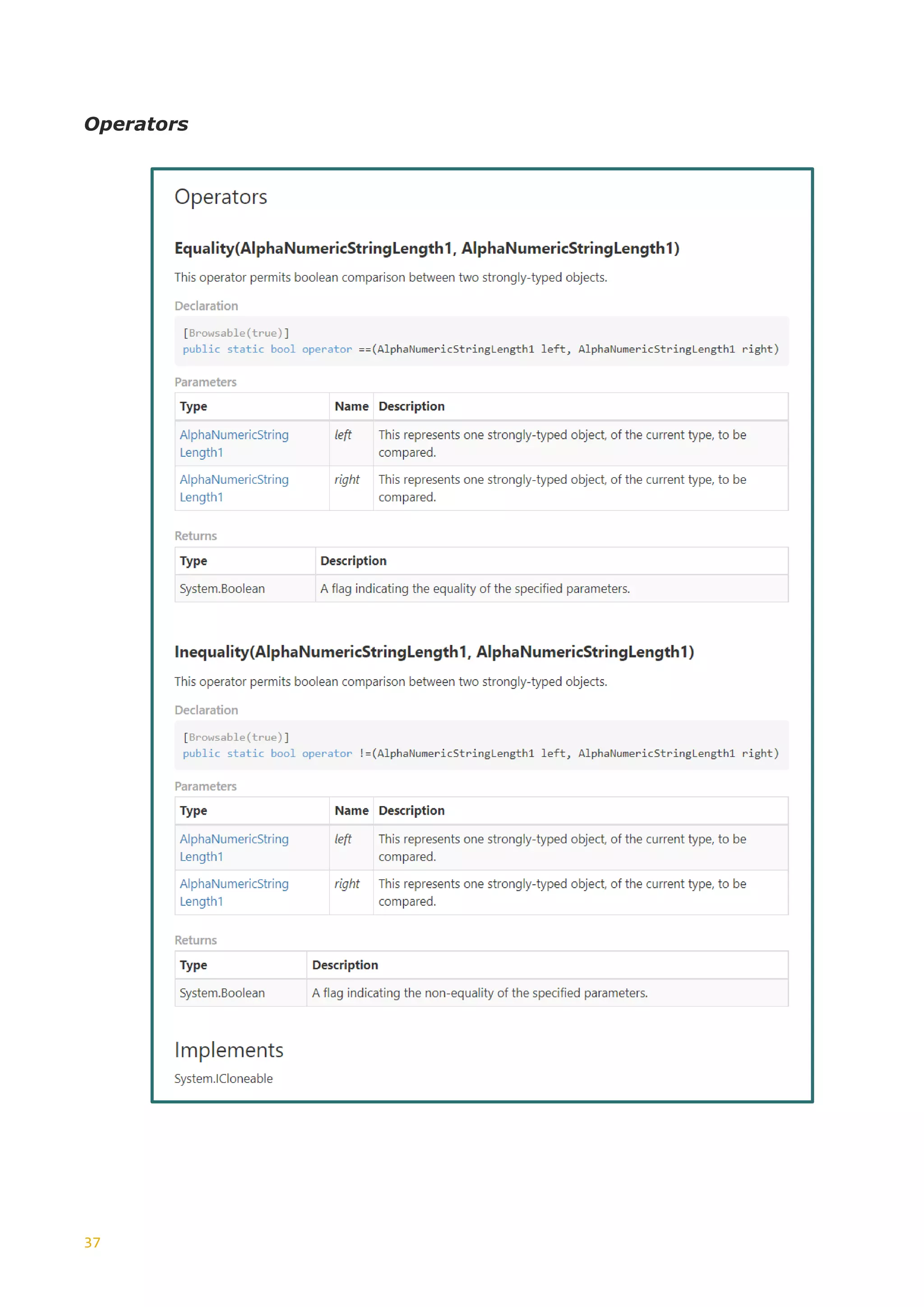
Tree
+--------------------------
SimpleType:- StringLength0to128
Documentation:- [en] Used for Character Strings, length 0 to 128.
SimpleTypeRestriction:- baseType: xs:string
MinLengthRestriction: baseType: xs:string minLength: 0
MaxLengthRestriction: baseType: xs:string maxLength: 128
+--------------------------
The tree node textual representation given here is quite simple. Things get
somewhat more complex when we look at ComplexType and Element types where
various content models come into play.
The Generation Phase
In the generation phase, the structure element tree is scanned, and the elements
are passed to the generator, which uses a target language-specific extension part to
emit the final form.](https://image.slidesharecdn.com/generationxsdarticle-part2-220828151558-67e96f7b/75/Generation_XSD_Article-Part-2-pdf-9-2048.jpg)





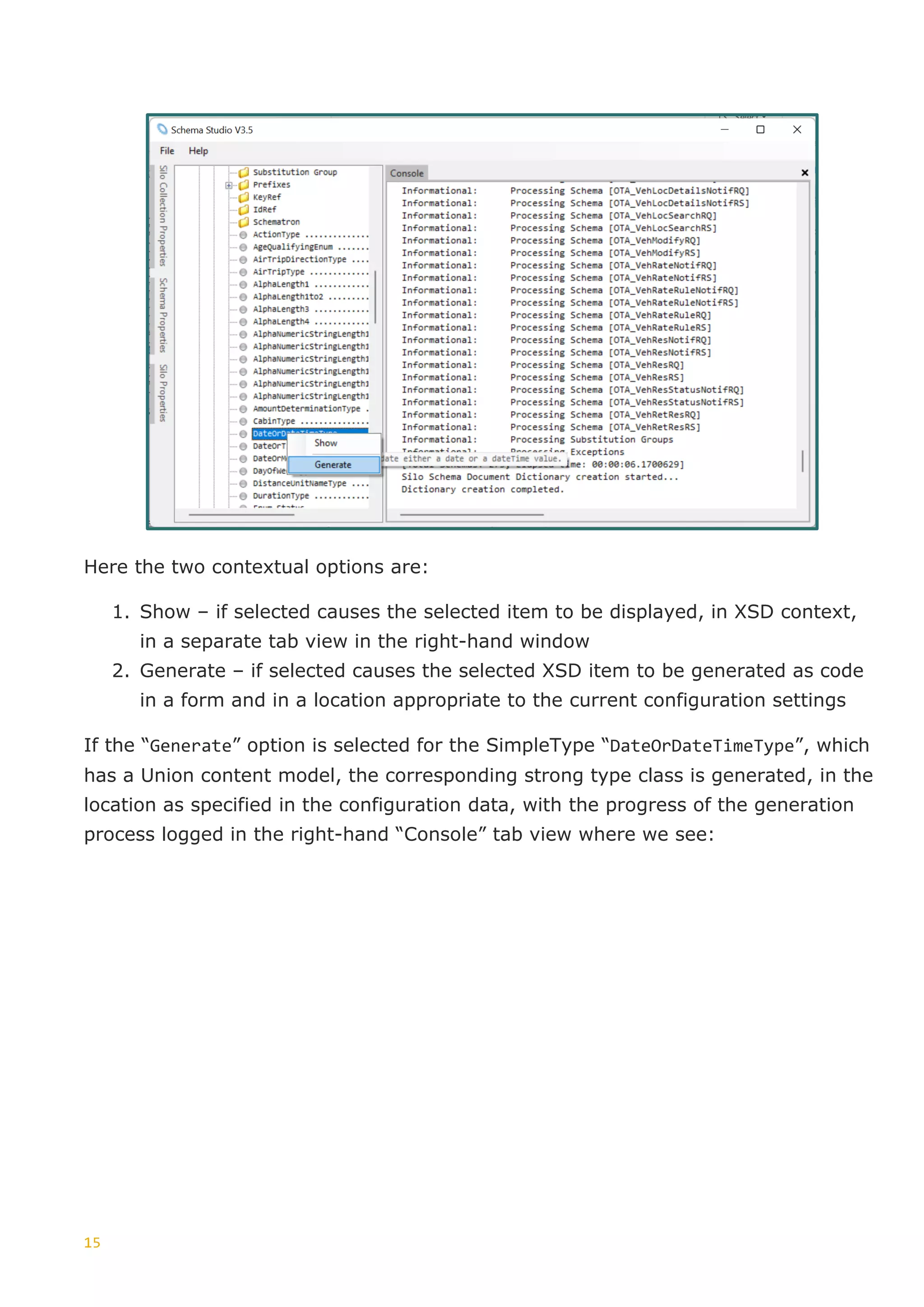


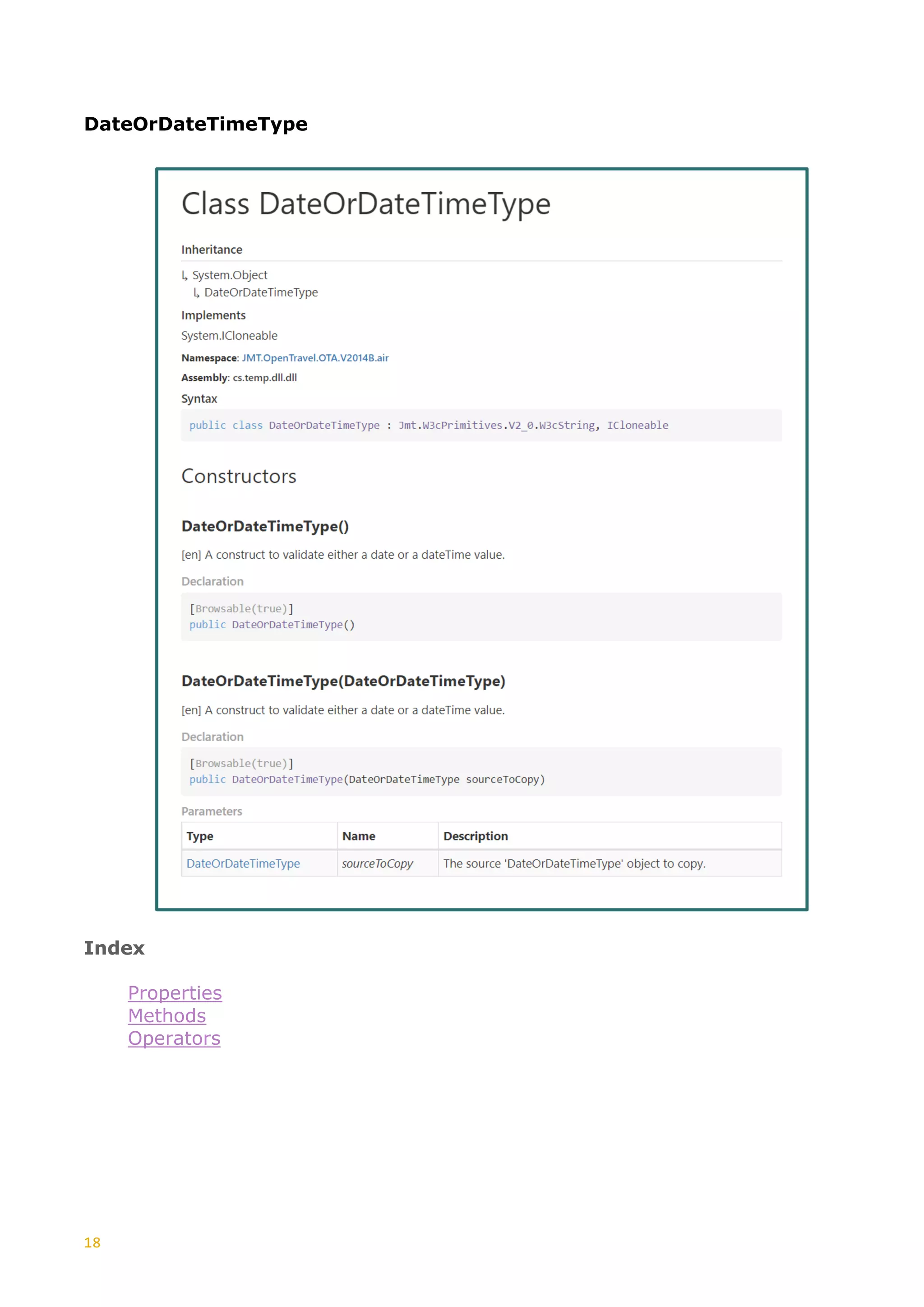
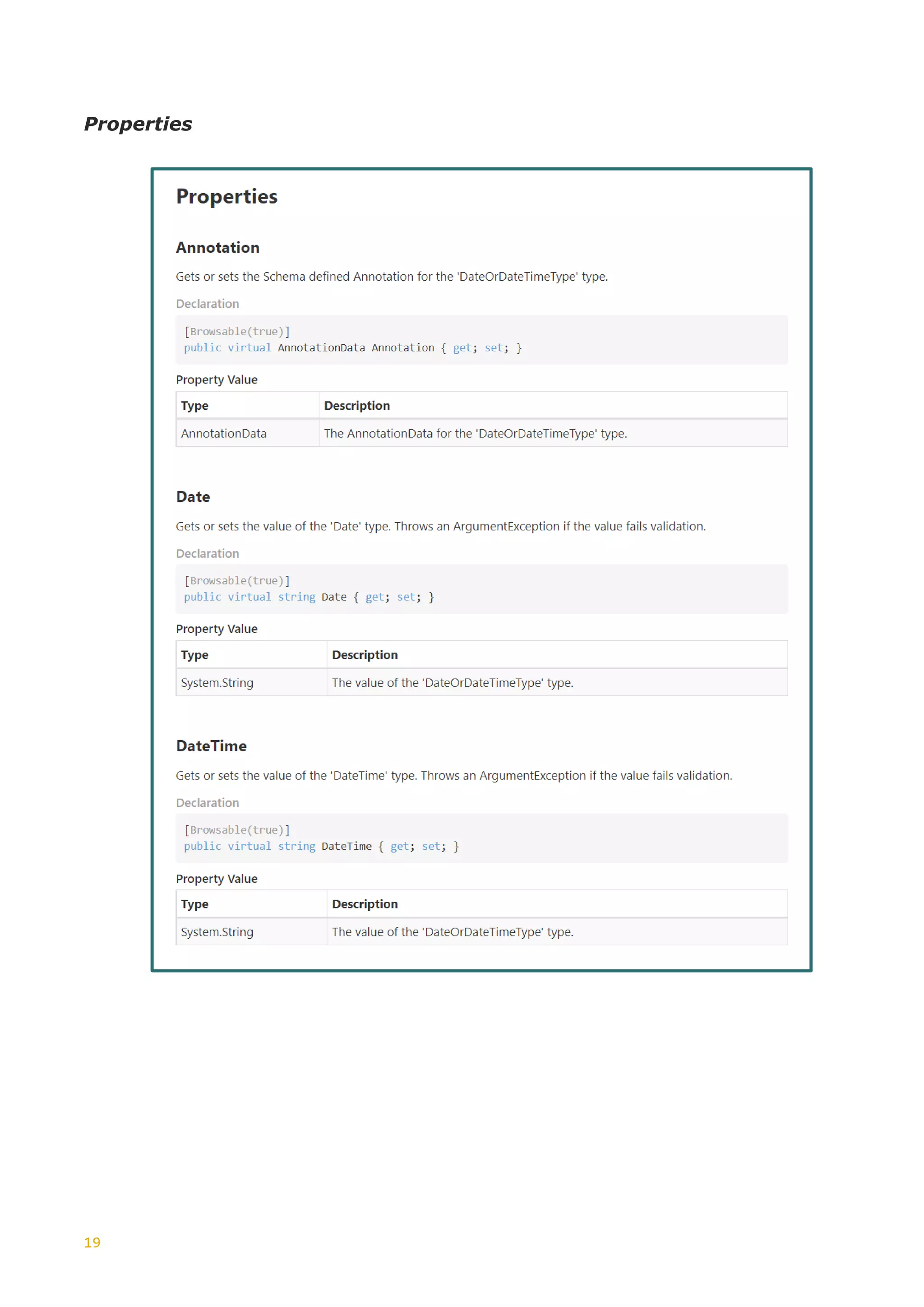






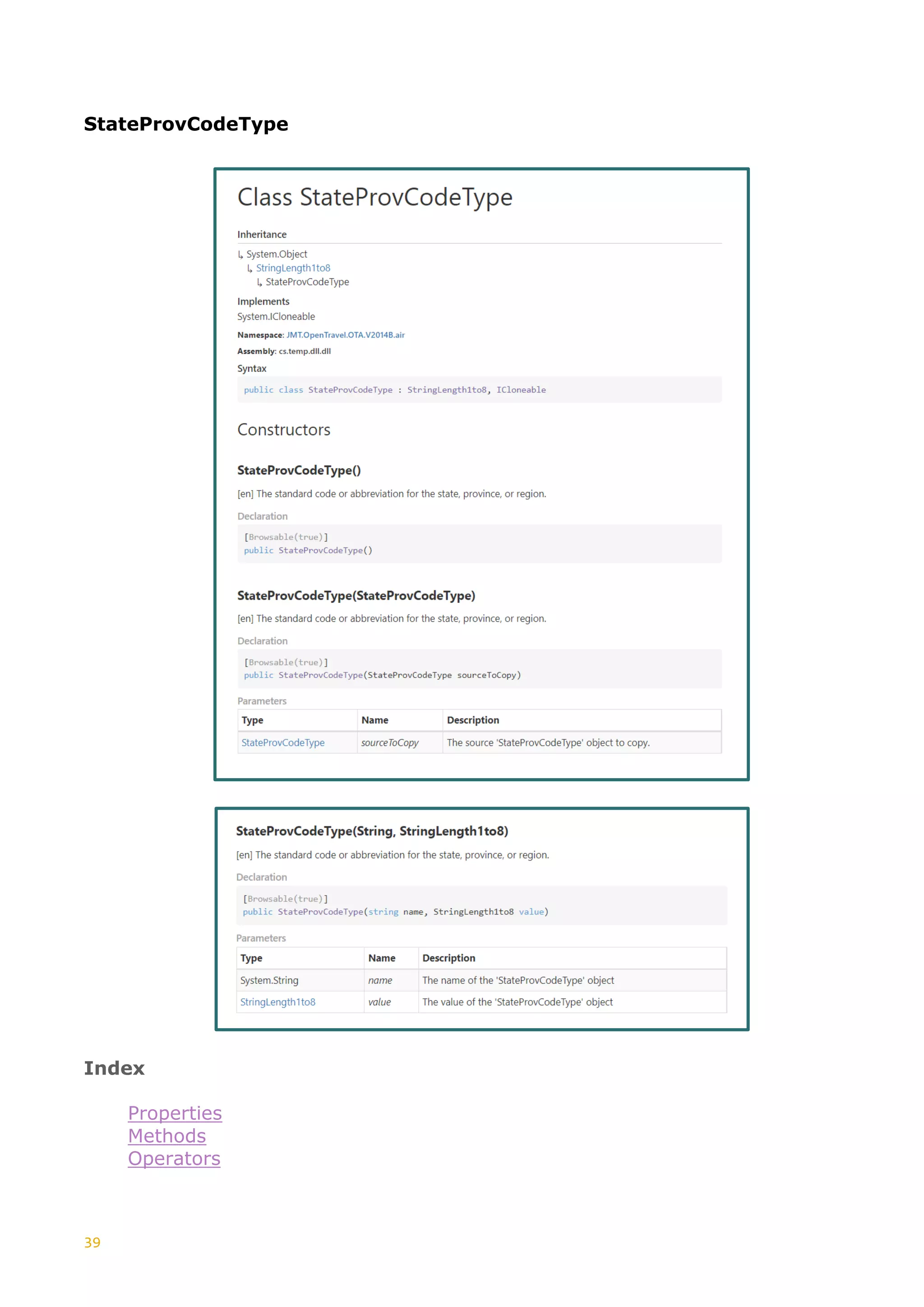
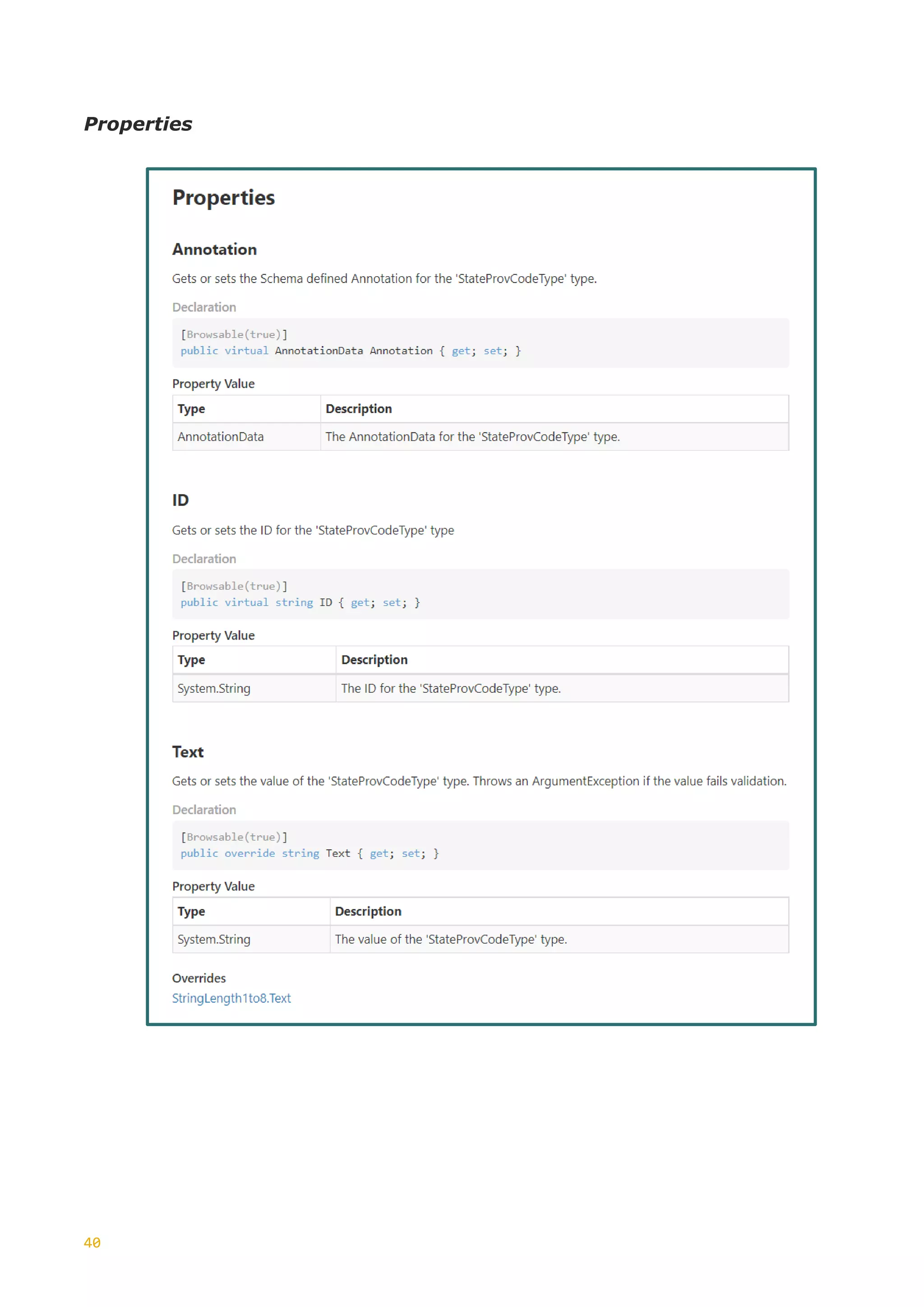


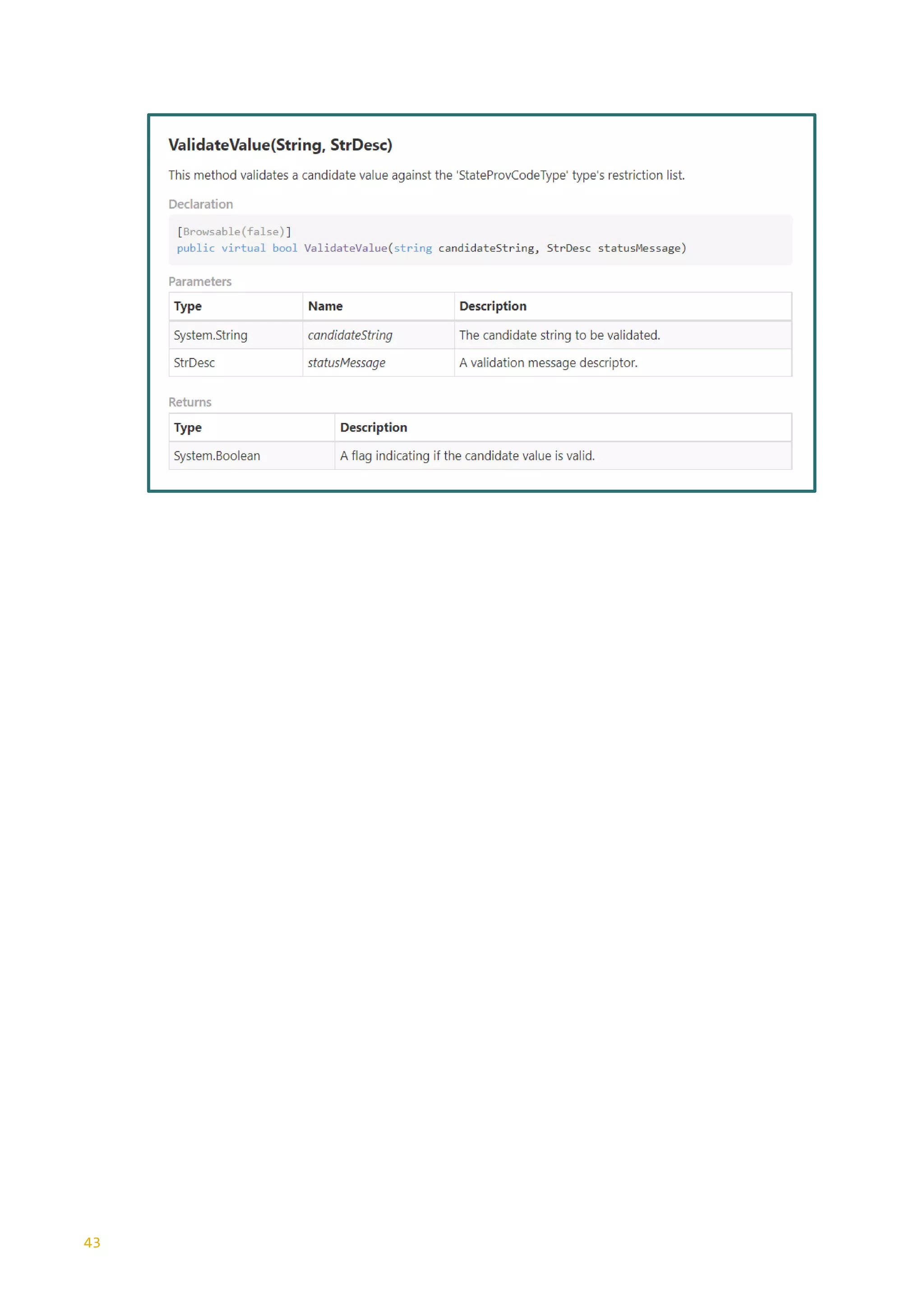
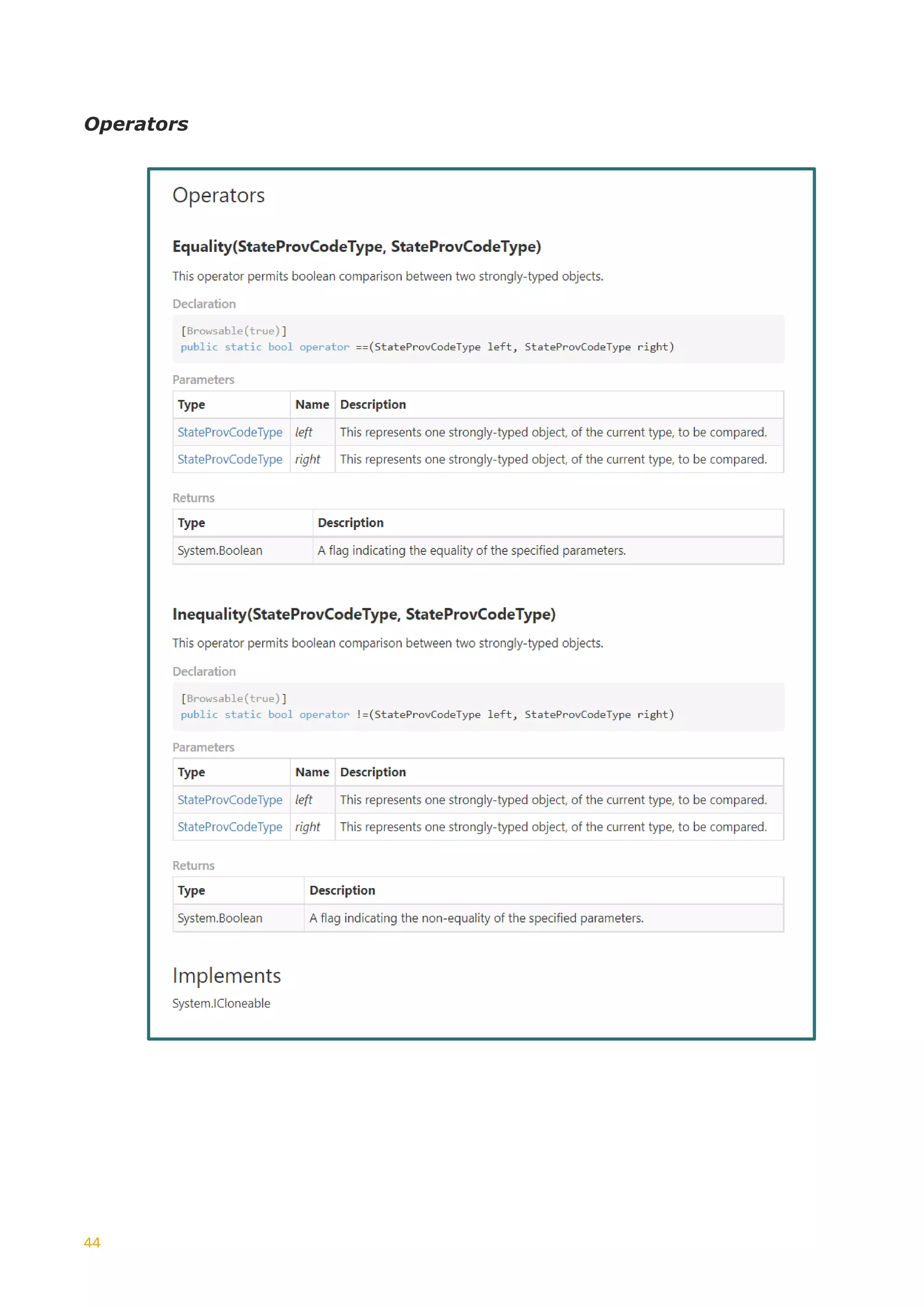


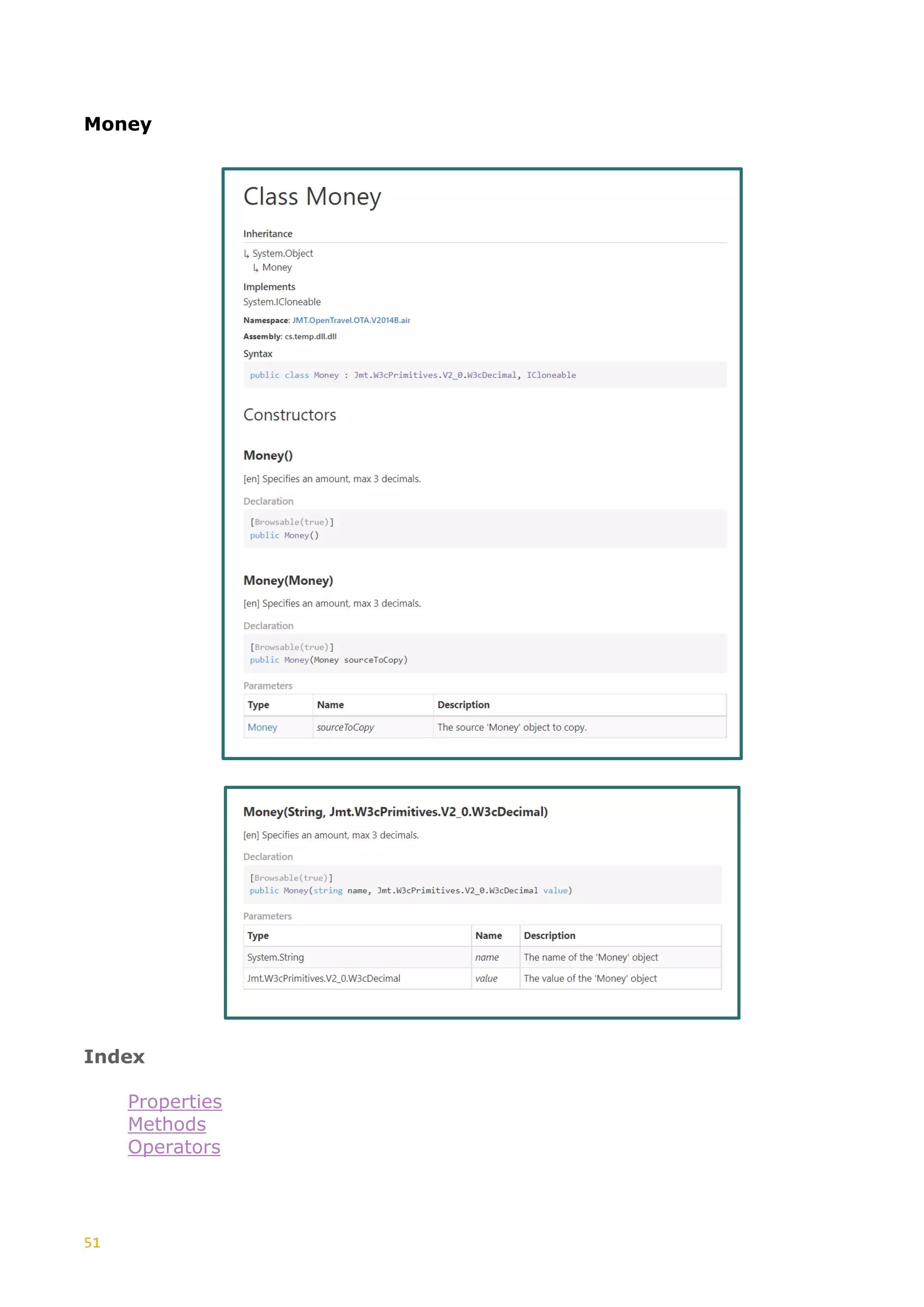



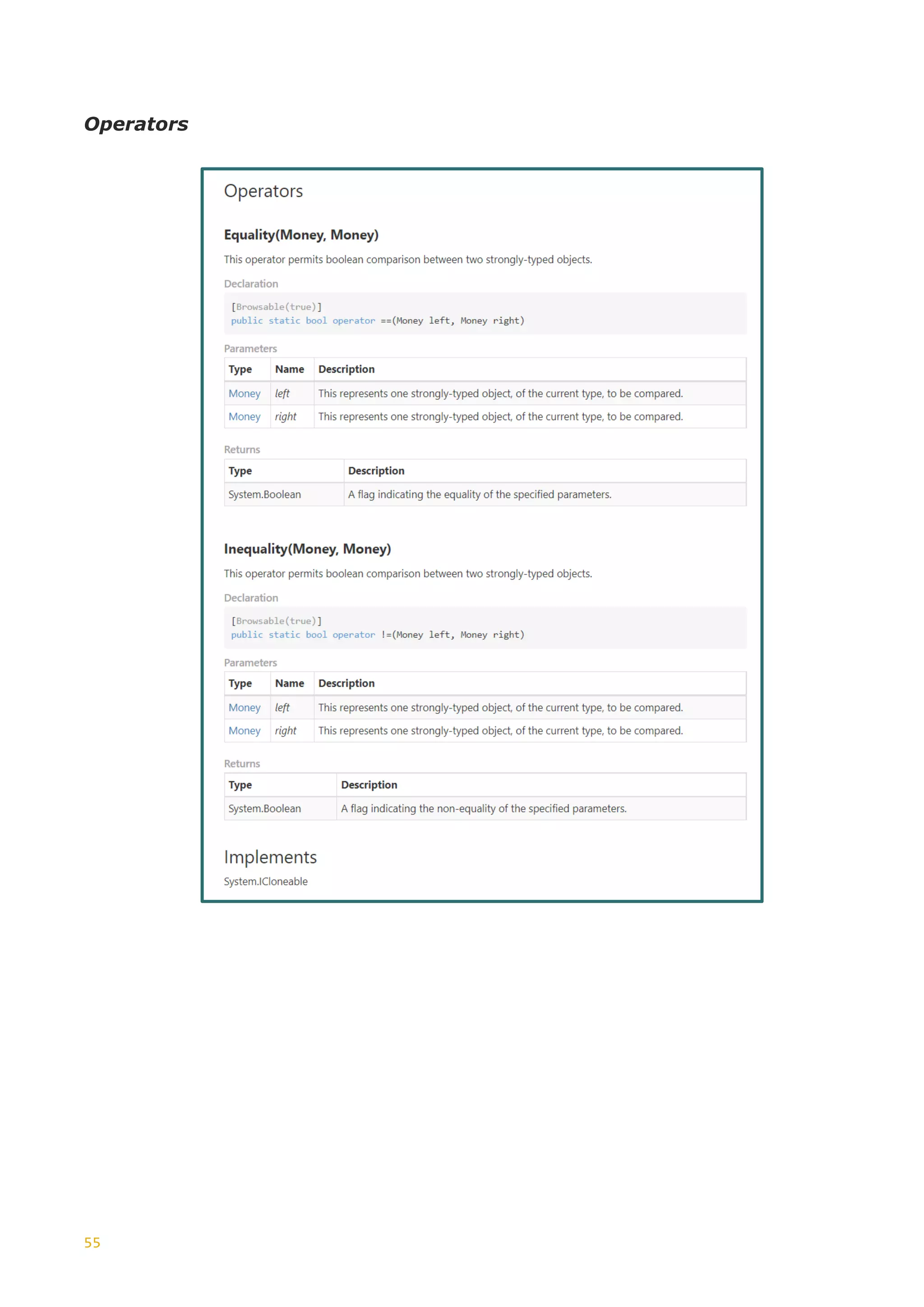







This document discusses the generation of XSD schemas, focusing on simple types, restrictions, and the process of translating W3C schema definitions into programming languages like C# and Java. It examines various types of restrictions that can be applied to simple types and provides a description of how schema studio functions in processing these types. Additionally, it includes examples of simple types and their constraints from an Open Travel schema set, along with the generation process involved in creating code from these schemas.

















































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)











