Download to read offline



















































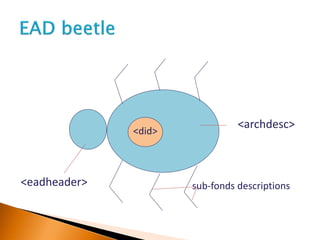


















![<ead>…
<archdesc>
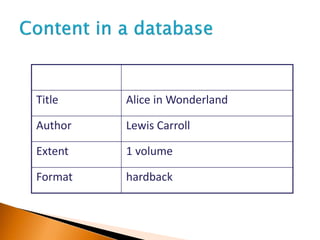
[collection level description here]
◦ <dsc>
<c01>[series] description 1
<c02>[file] description 1</c02>
<c02>[file] description 2
<c03>[item] 1</c03>
<c03>[item] 2</c03>
</c02>
</c01>
<c01>[series] description 2....
◦ </dsc>
</archdesc>
</ead>
c02 c02
c03 c03
c01](https://image.slidesharecdn.com/archiveshubead2010extended-101116061120-phpapp02/85/Archives-hub-ead-2010_extended-73-320.jpg)


![<dsc type="combined">
<c level="series">
<did> <unitid>Series 1</unitid>
<unittitle>Correspondence</unittitle> </did>
<scopecontent>[...]</scopecontent>
<c level="subseries">
<did> <unitid>Subseries 1.1</unitid>
<unittitle>Outgoing Correspondence</unittitle> </did>
<c level="file"> <did> <unittitle>AbbingerAldrich</unittitle> </did>
</c> </c> </c> </dsc>](https://image.slidesharecdn.com/archiveshubead2010extended-101116061120-phpapp02/85/Archives-hub-ead-2010_extended-76-320.jpg)














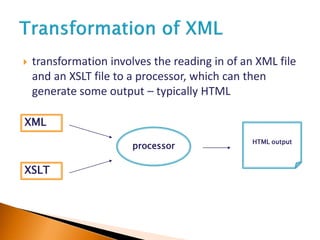
The document provides an introduction to interoperability, XML, EAD structure and syntax, EAD hierarchies, and the UK Archives Discovery Network. It defines interoperability as the ability of systems to exchange and use shared information. XML is introduced as a meta-language for defining document structures with meaningful tags. EAD is described as an XML standard for encoding archival finding aids to facilitate search, retrieval, and navigation of archival descriptions. EAD allows for flexible description of archival materials and supports sharing of data between systems.

























![Xml theory 2005_[ngohaianh.info]_1_introduction-to-xml](https://cdn.slidesharecdn.com/ss_thumbnails/xmltheory2005ngohaianh-140302210326-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































