






![Serial Example static void SerialUpdateVelocity() { for( int i=1; i<UniverseHeight-1; ++i ) for( int j=1; j<UniverseWidth-1; ++j ) V[i][j] += (S[i][j] - S[i][j-1] + T[i][j] - T[i-1][j])*M[i]; }](https://image.slidesharecdn.com/os-reindersfinal1301/85/Os-Reindersfinal-14-320.jpg)
![Parallel Version blue = original code red = provided by TBB black = boilerplate for library struct UpdateVelocityBody { void operator()( const blocked_range <int>& range ) const { int end = range.end (); for( int i= range.begin (); i<end; ++i ) { for( int j=1; j<UniverseWidth-1; ++j ) { V[i][j] += (S[i][j] - S[i][j-1] + T[i][j] - T[i-1][j])*M[i]; } } } void ParallelUpdateVelocity() { parallel_for ( blocked_range<int> ( 1, UniverseHeight-1), UpdateVelocityBody(), auto_partitioner() ); } Task Parallel control structure Task subdivision handler](https://image.slidesharecdn.com/os-reindersfinal1301/85/Os-Reindersfinal-15-320.jpg)



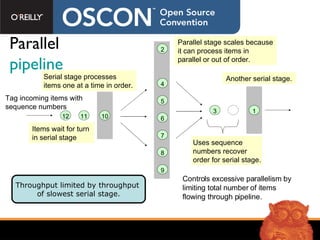


















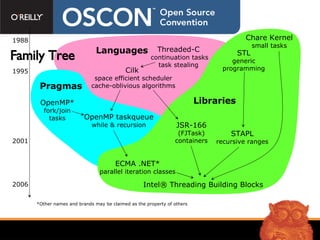
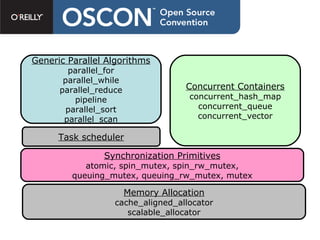
The document discusses Intel Threading Building Blocks (TBB), a C++ template library for parallel programming. TBB provides features like parallel_for to simplify parallelizing loops across CPU cores without managing threads directly. It uses generic programming principles and provides common parallel algorithms, concurrent data structures, and synchronization primitives to make parallel programming more accessible. TBB aims to improve both correctness through avoiding race conditions and performance through efficient hardware utilization.