Downloaded 12 times



![PIKM 2010 – Workshop for Ph.D. Students in Information and Knowledge Management
October 30, 2010 – Fairmont Royal York, Toronto, Canada
What is Exploratory Search?
[Gary Marchionini. Exploratory Search: From Finding to understanding. Communications of the ACM, 49(4): 41-46, 2006]](https://image.slidesharecdn.com/pikm2010-slideshare-101029145745-phpapp01/75/From-Exploratory-Search-to-Web-Search-and-back-PIKM-2010-4-2048.jpg)
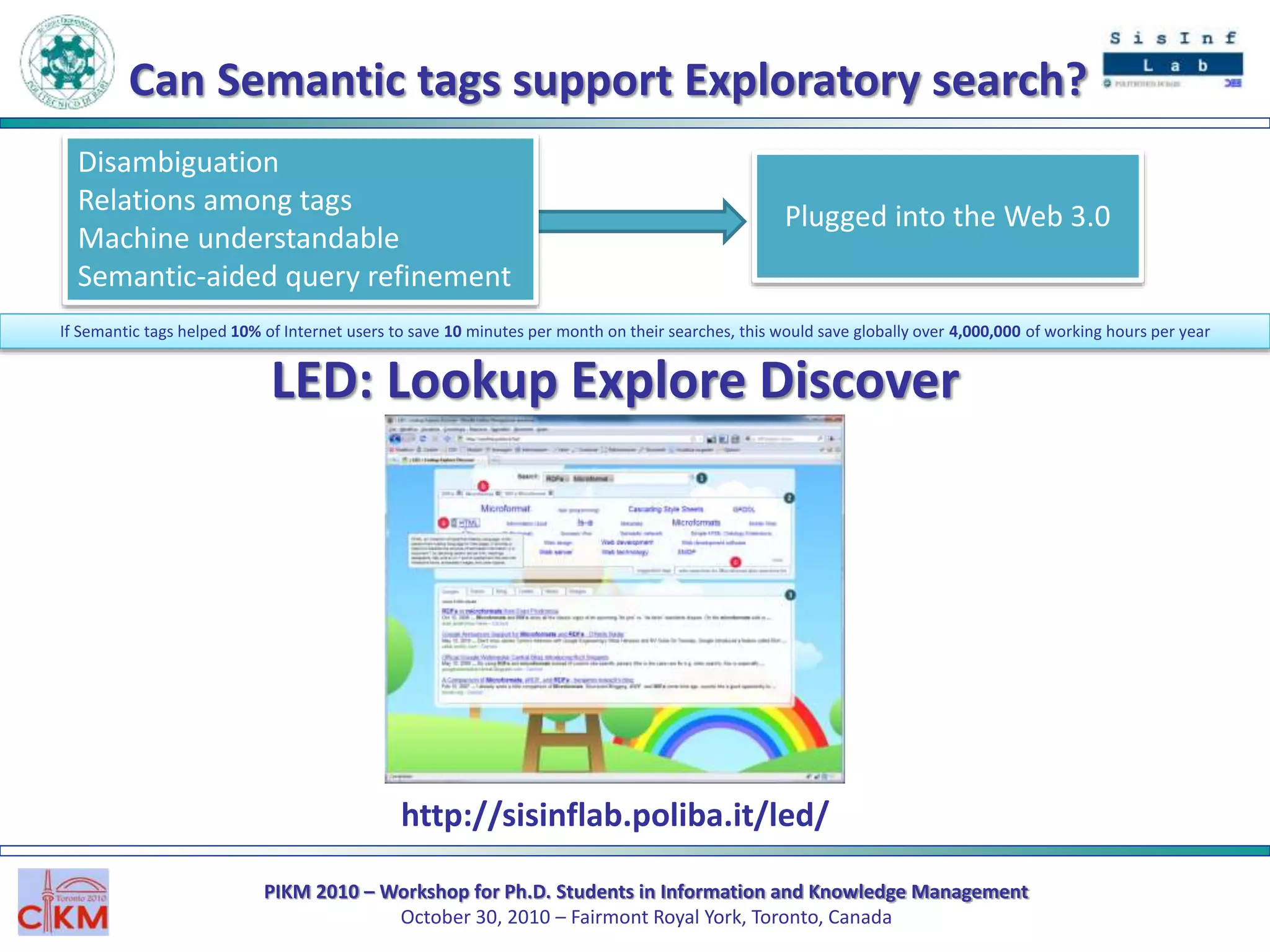
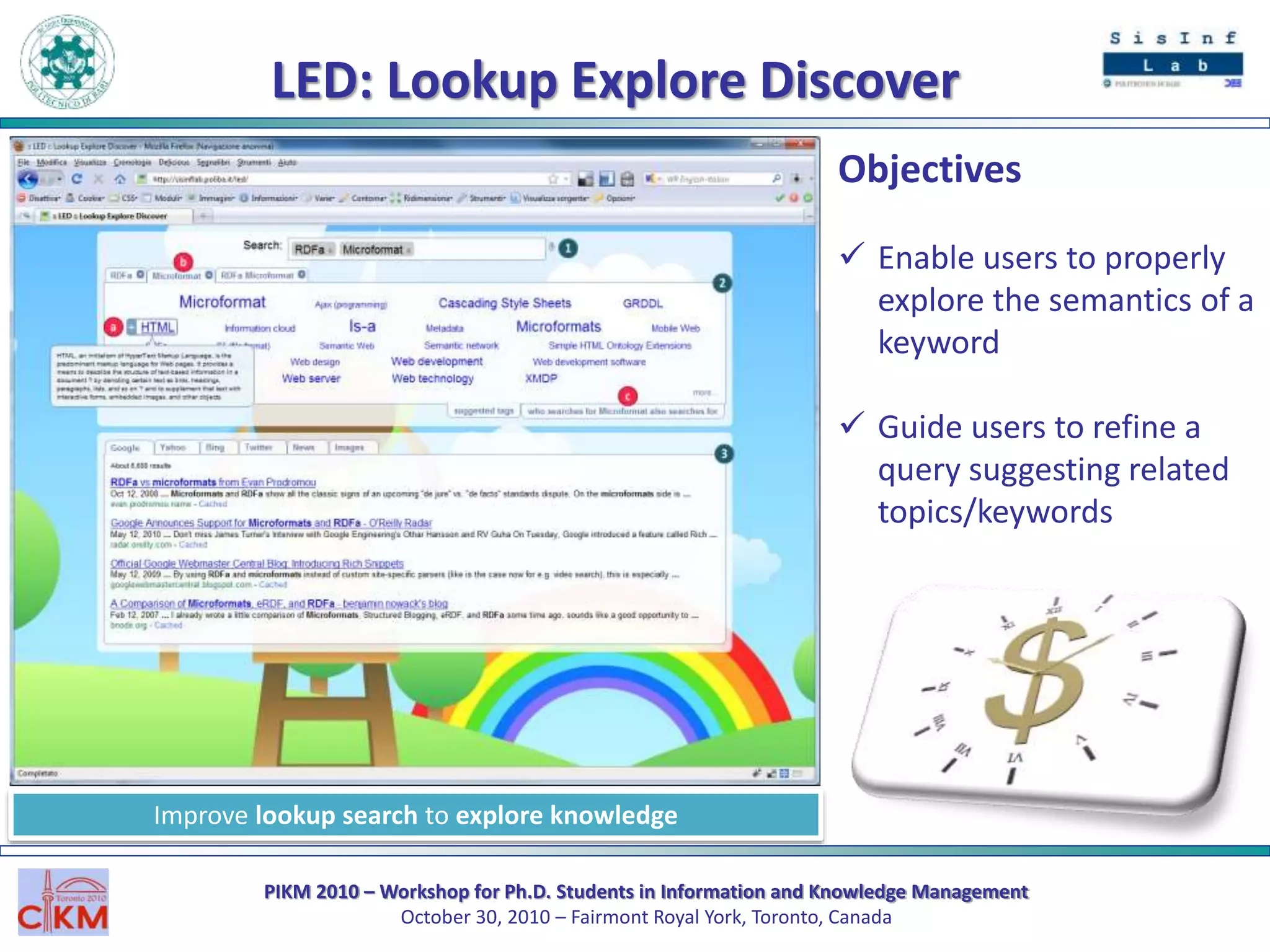


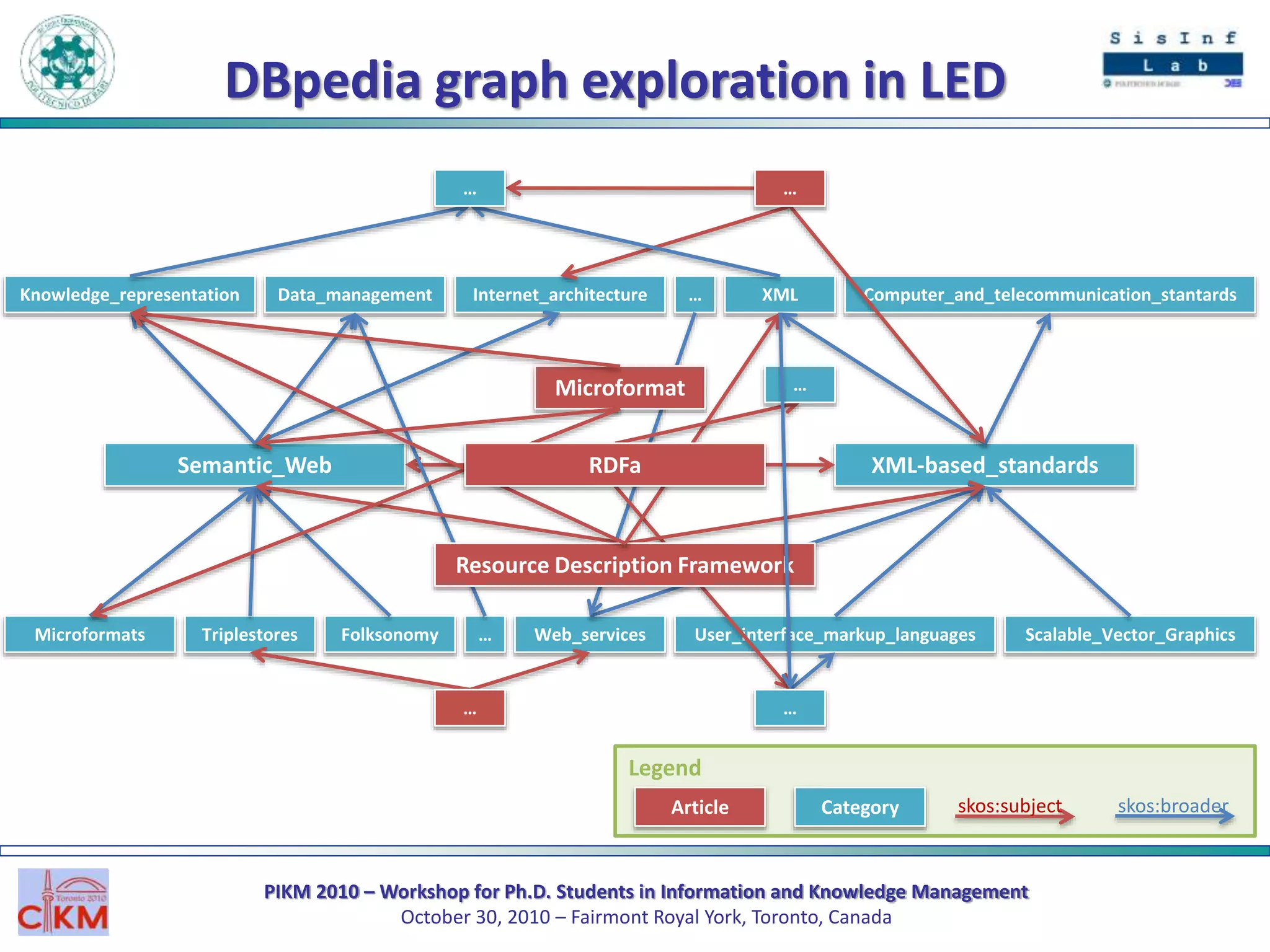
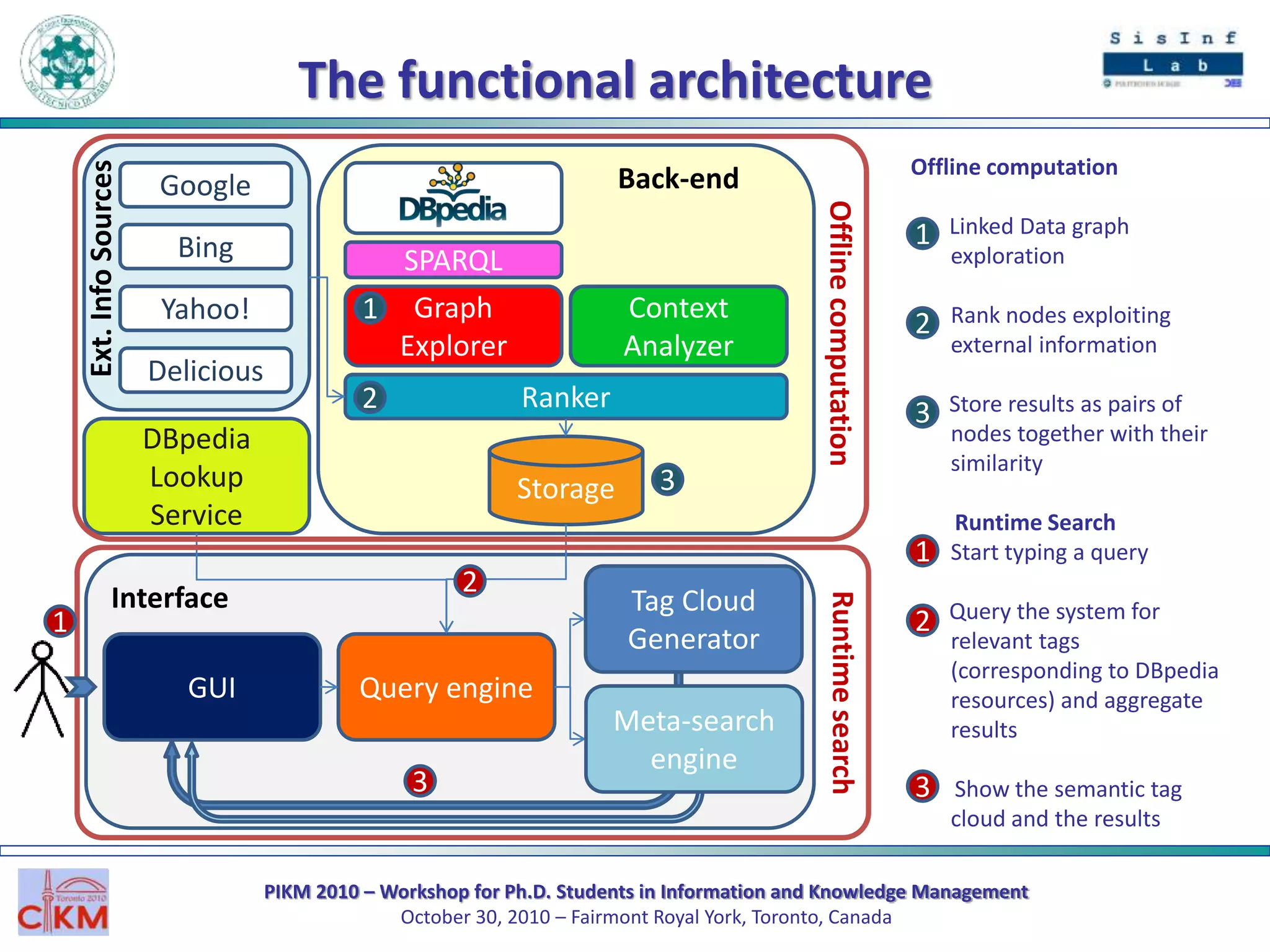



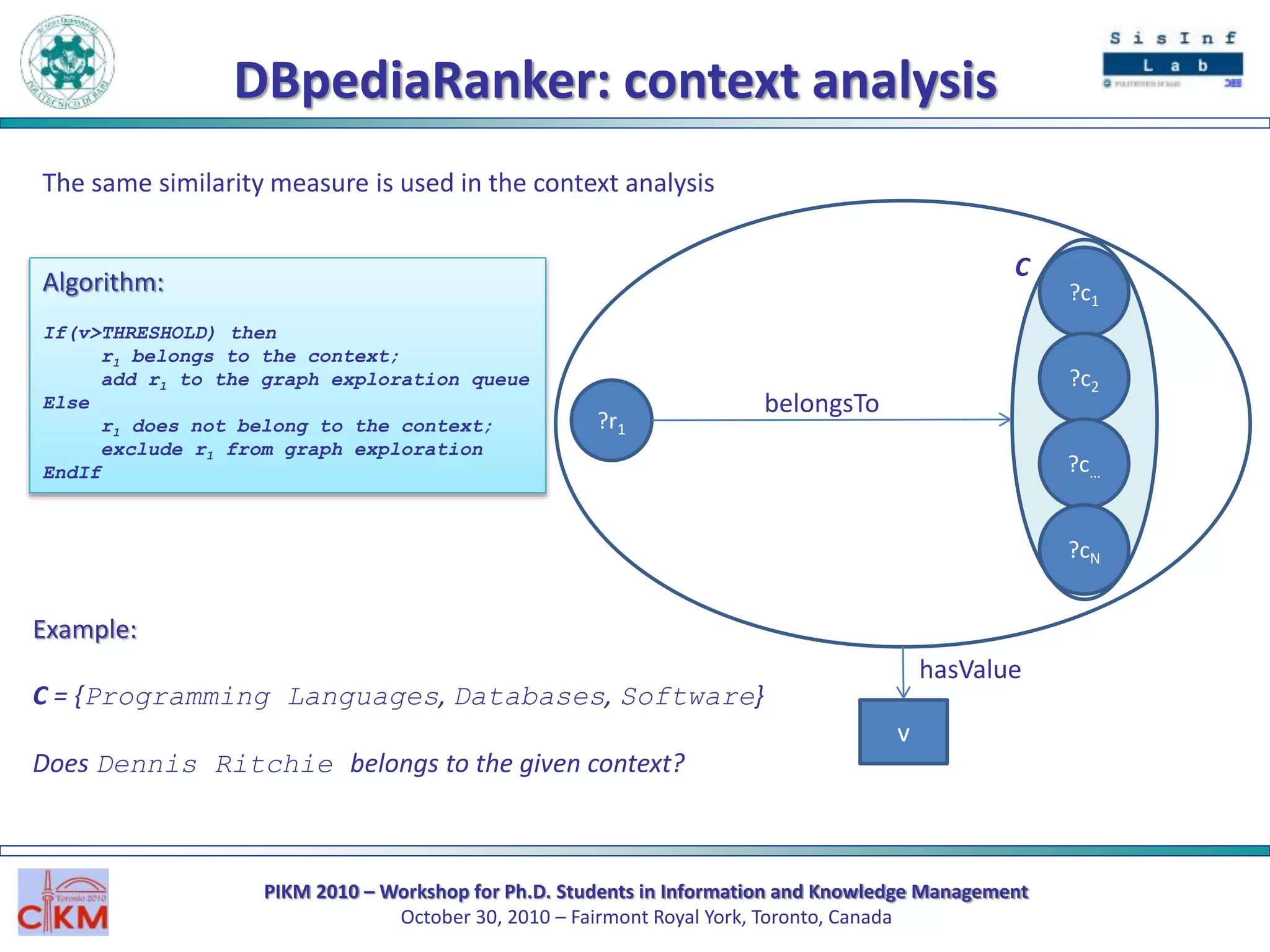
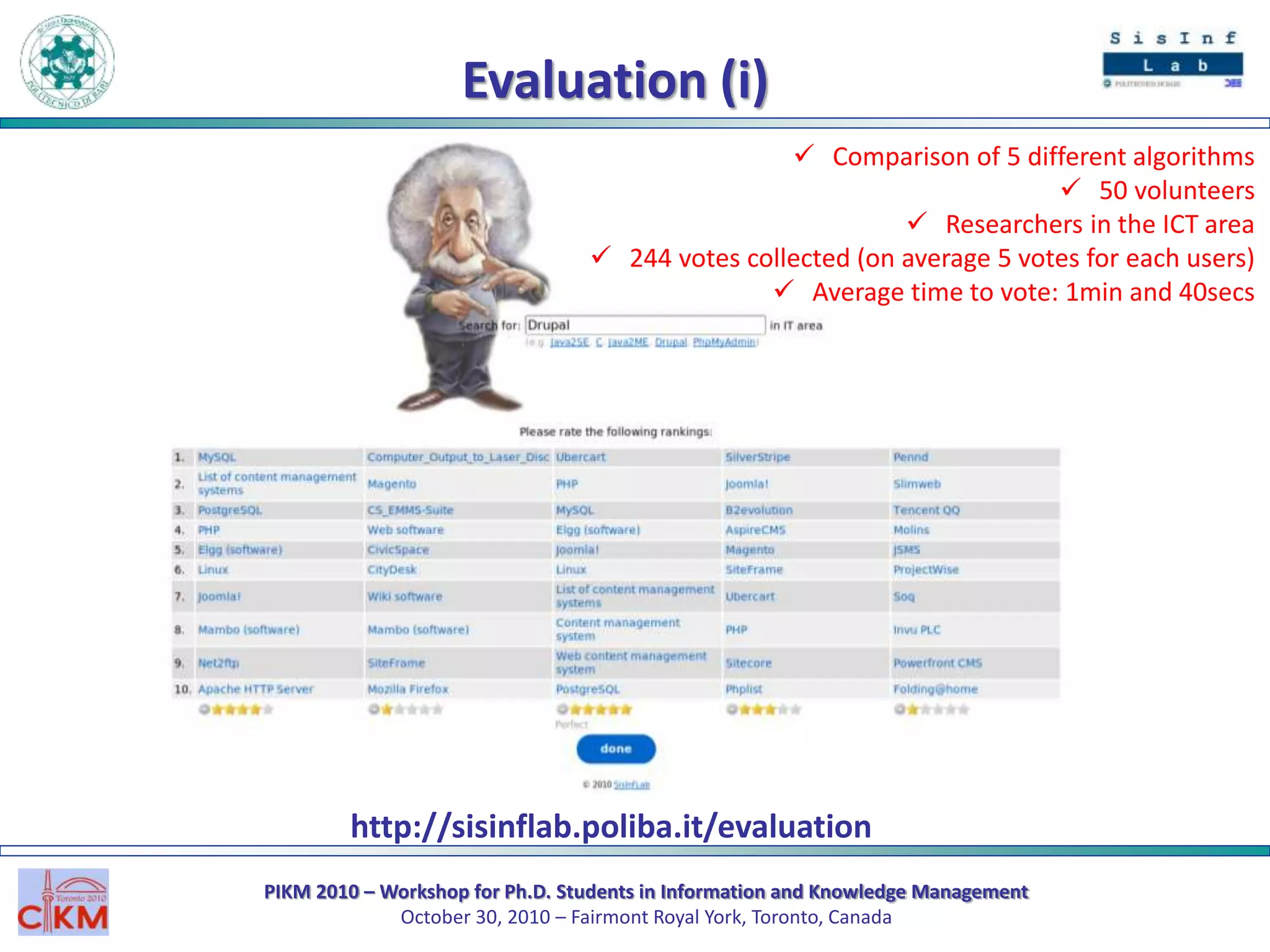




The document outlines the PIKM 2010 workshop for Ph.D. students focusing on exploratory search and knowledge management held in Toronto. It introduces the LED system for enhancing semantic exploration of keywords through tags and discusses the DBpedia ranking algorithm for resource evaluation. Future work includes improving ranking methods and developing a RESTful API for novel applications.

















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













