Download as PDF, PPTX



![Introduction
The Resource Description Framework
Resource
Description
Framework
(RDF)
Resource
Description
Framework
(RDF)
Formalization of the model
Systematic study of the complexity of
entailment
Formalization of the concept of minimal
representation (core) of an RDF graph
Study of the complexity of
core computation
[Gutierrez
et al. 2011]
Foundational
aspects
Valeria Fionda, Gianluigi Greco ( Department of Mathematics and Computer Science, University ofTrust Models for RDF Data 4 / 28](https://image.slidesharecdn.com/aaai15-150605195835-lva1-app6892/85/Trust-Models-for-RDF-Data-Semantics-and-Complexity-AAAI2015-5-320.jpg)
![Introduction
Extensions of RDF
[G
utierrez, H
urtado,
and
Vaism
an
2007]
Time
Provenance
[Dividino et al. 2009]
Fuzzy
[Straccia 2009]
Trust
[Hartig 2009;
Tomaszuk, Pak,
and Rybinski 2013]
General annotations
[U
drea,Recupero,
and
Subrahm
anian
2010;
Zim
m
erm
ann
etal.2012]
Resource
Description
Framework
(RDF)
Valeria Fionda, Gianluigi Greco ( Department of Mathematics and Computer Science, University ofTrust Models for RDF Data 5 / 28](https://image.slidesharecdn.com/aaai15-150605195835-lva1-app6892/85/Trust-Models-for-RDF-Data-Semantics-and-Complexity-AAAI2015-6-320.jpg)











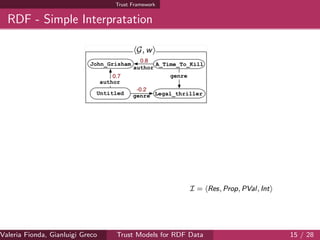
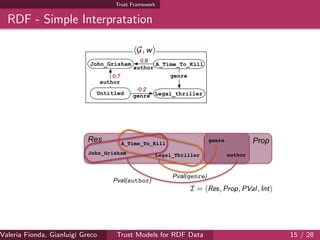
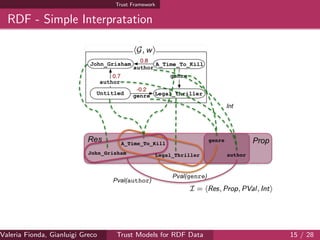
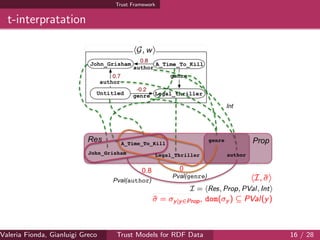
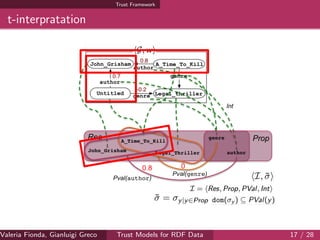



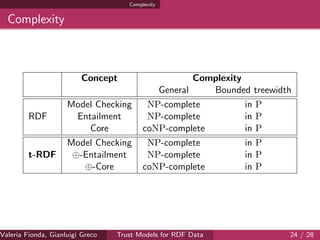
![Complexity
Trust Aggregation Operators
Model Checking
Complexity
General Acyclic
RDF NP-complete in P
t-RDF NP-complete NP-complete
We focus on trust aggregation functions (f⊕) that can be built on top
of binary trust aggregation operators (⊕):
A trust (aggregation) operator ⊕ is the binary operator of an
Idempotent Commutative Ordered Monoid ([−1, 1] ∪ {φ}, ⊕, ) where
the partial order is defined as v v if, and only if, v ⊕ v = v.
Valeria Fionda, Gianluigi Greco ( Department of Mathematics and Computer Science, University ofTrust Models for RDF Data 23 / 28](https://image.slidesharecdn.com/aaai15-150605195835-lva1-app6892/85/Trust-Models-for-RDF-Data-Semantics-and-Complexity-AAAI2015-34-320.jpg)



The document discusses trust models for RDF data, focusing on the significance of associating trust values to enhance reliability in decision-making processes on the semantic web. It introduces a formal framework for reasoning about trust values, emphasizing the complexity challenges involved in managing large volumes of data. Additionally, the authors highlight the necessity of making reasoning problems tractable and propose a prototype system to facilitate this approach.
























































