Download as PDF, PPTX



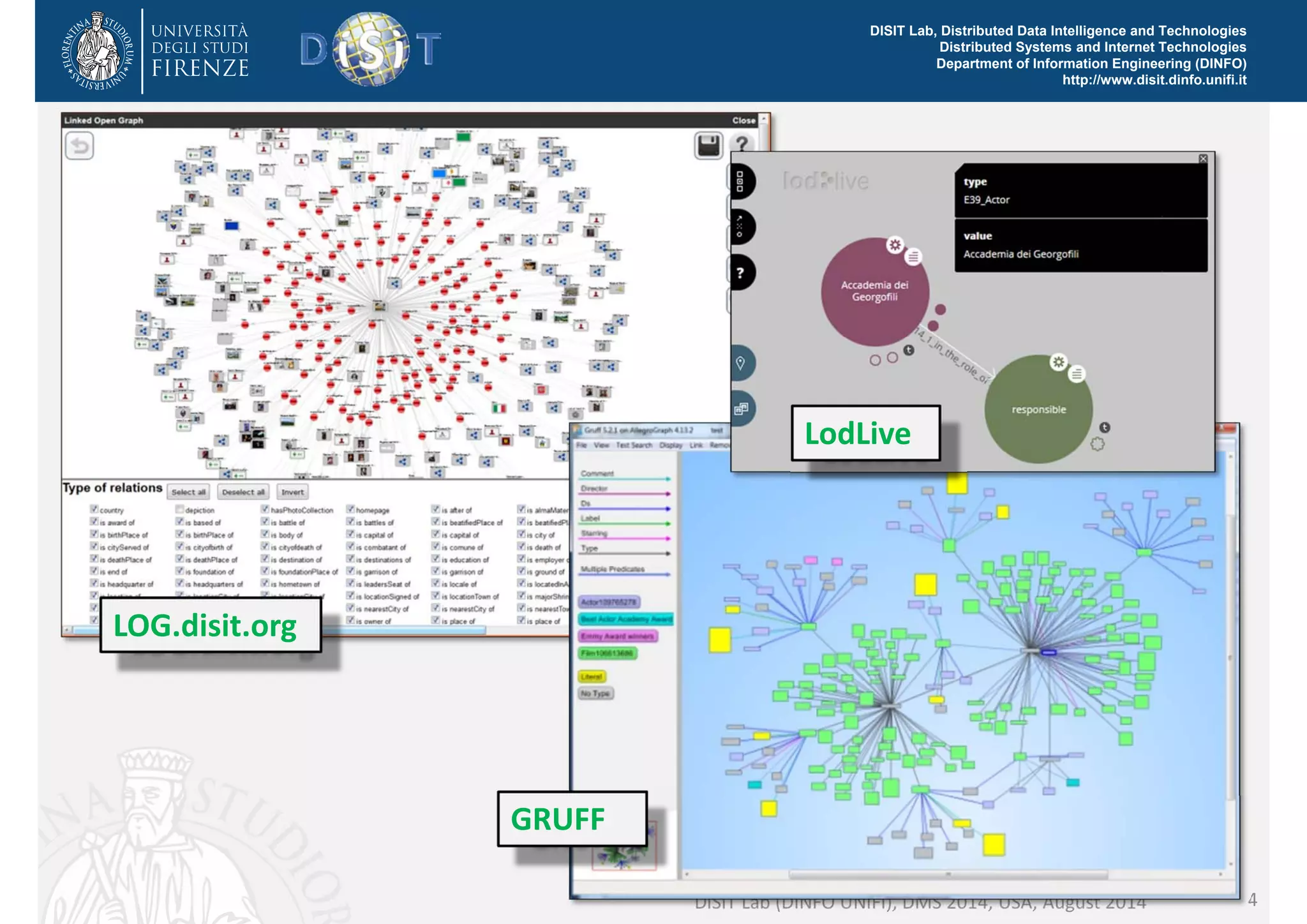

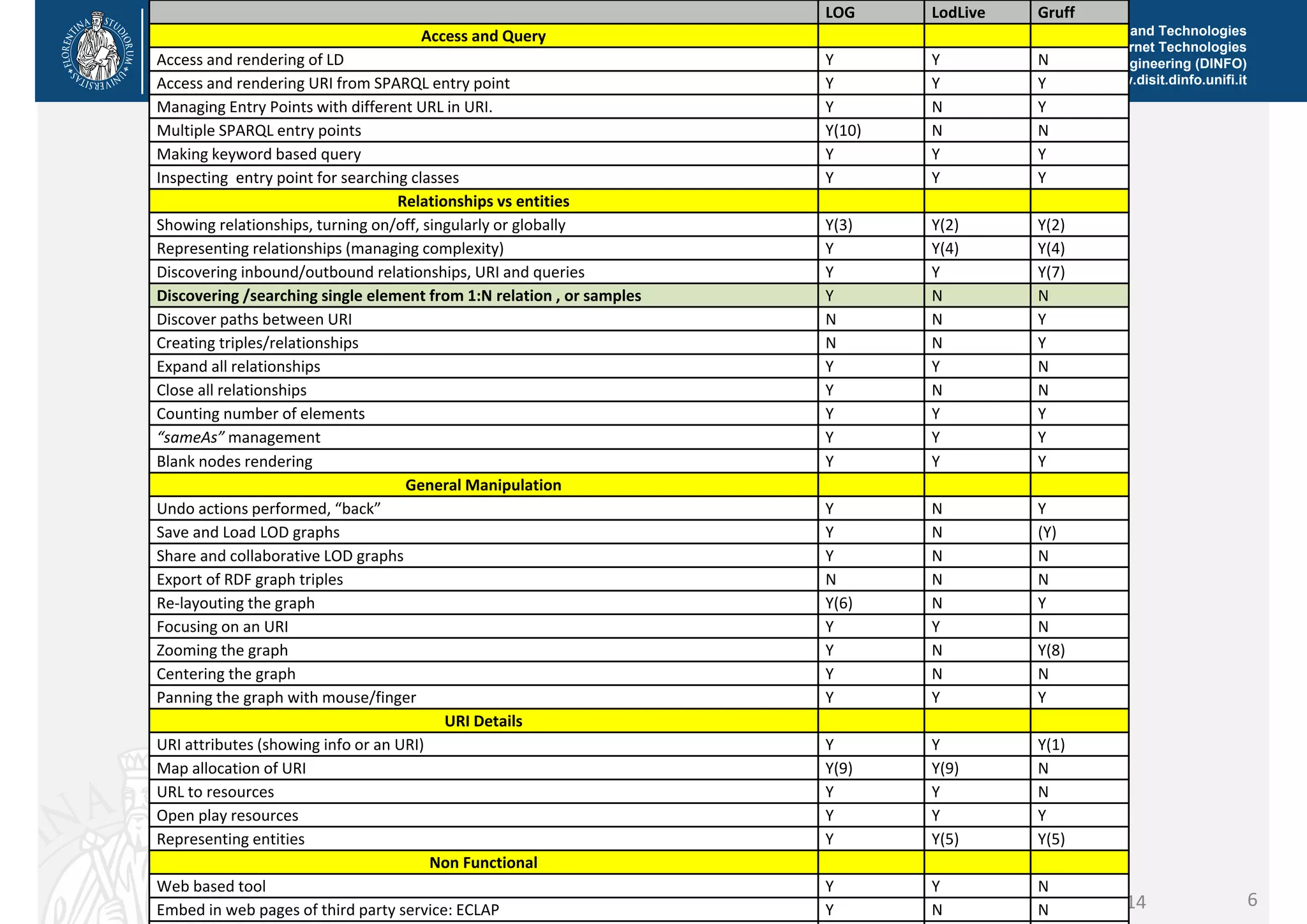
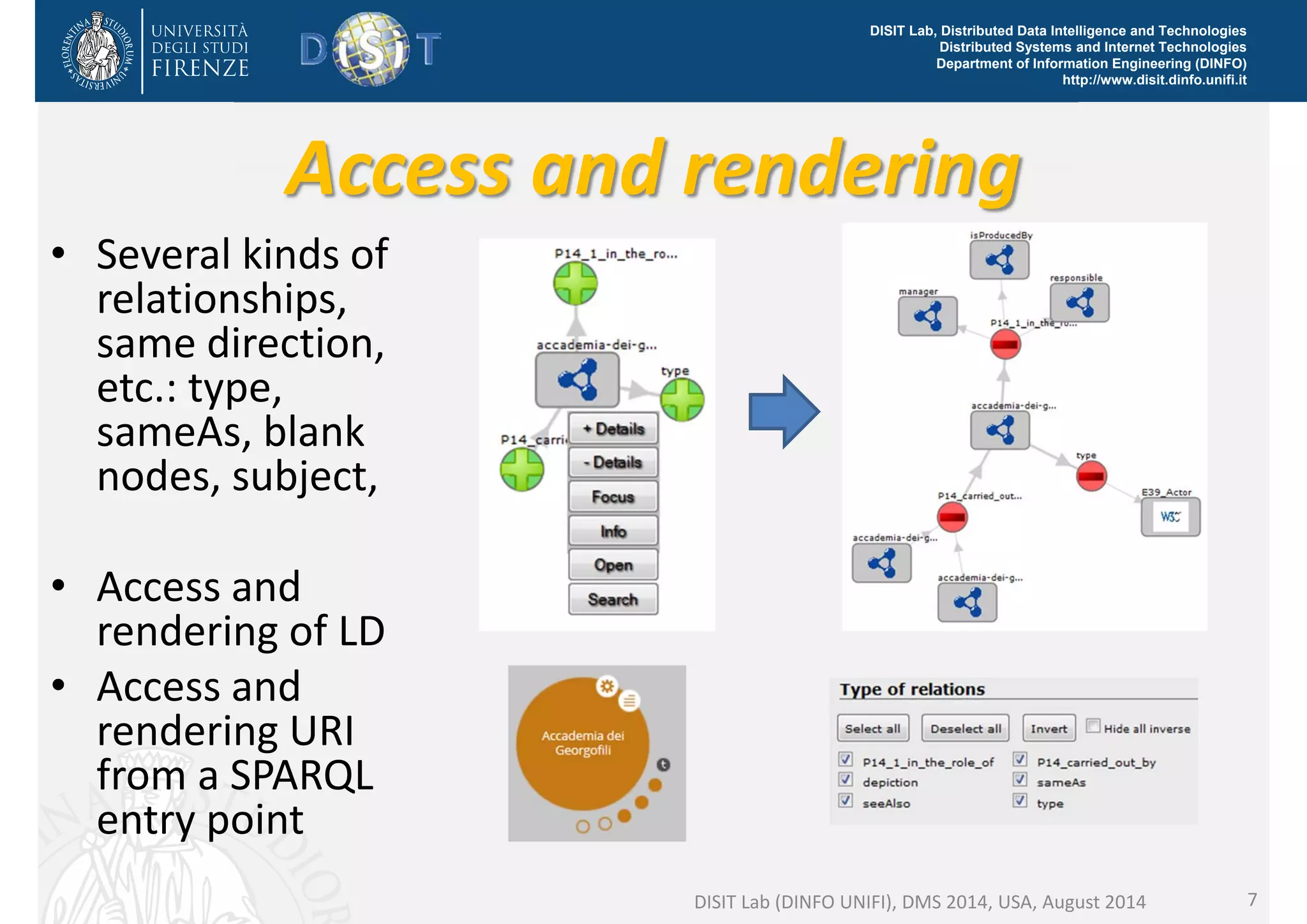
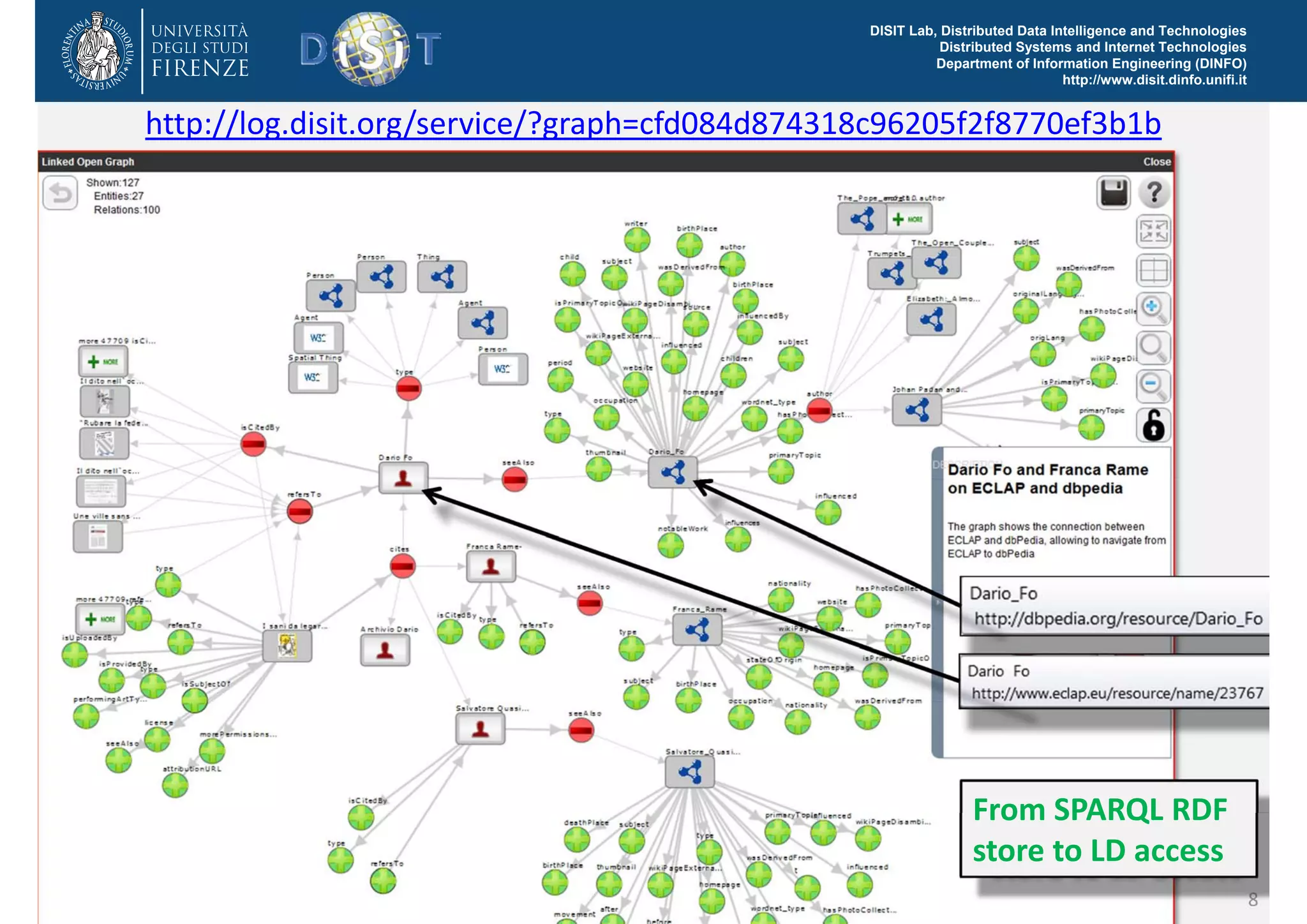
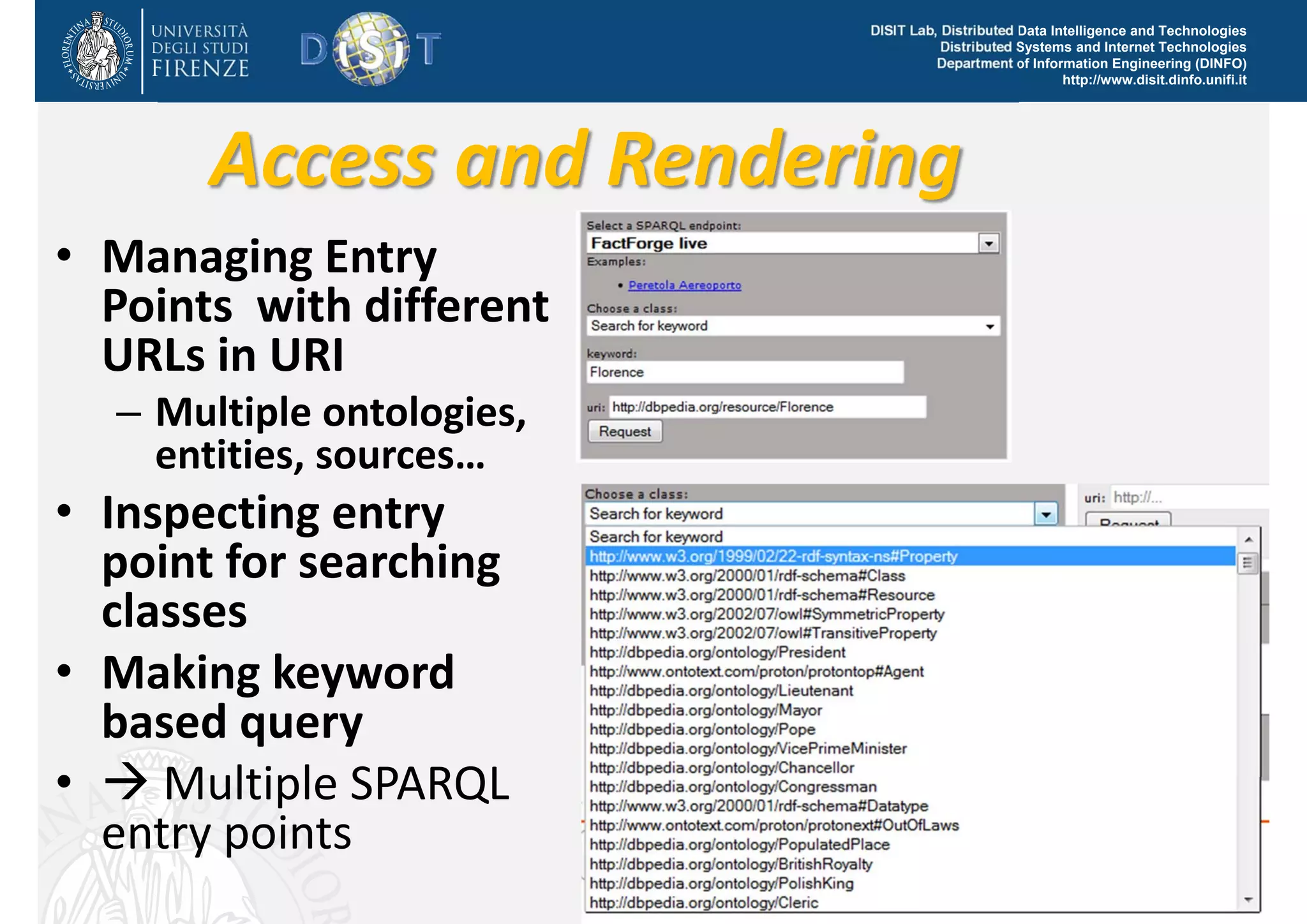

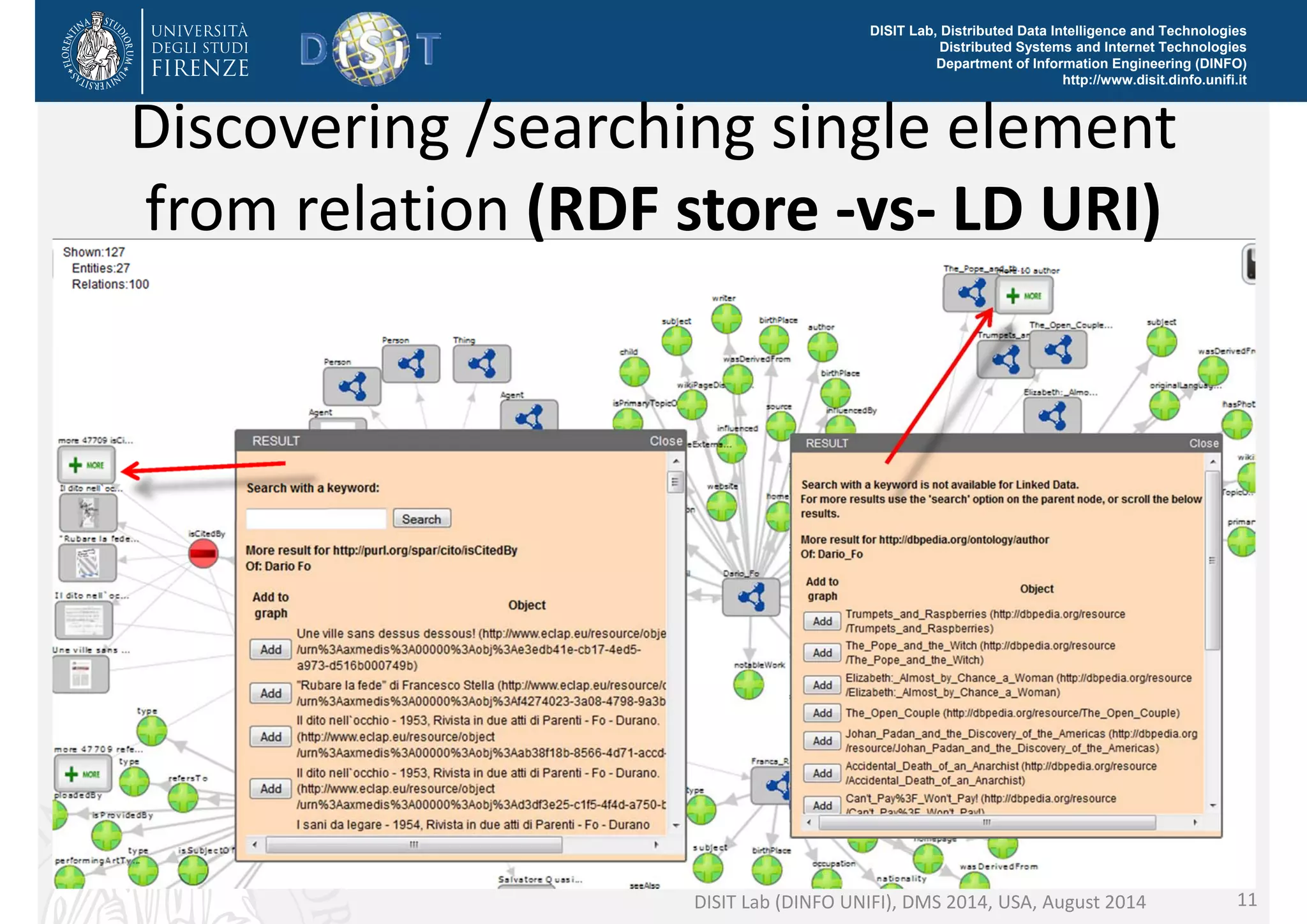
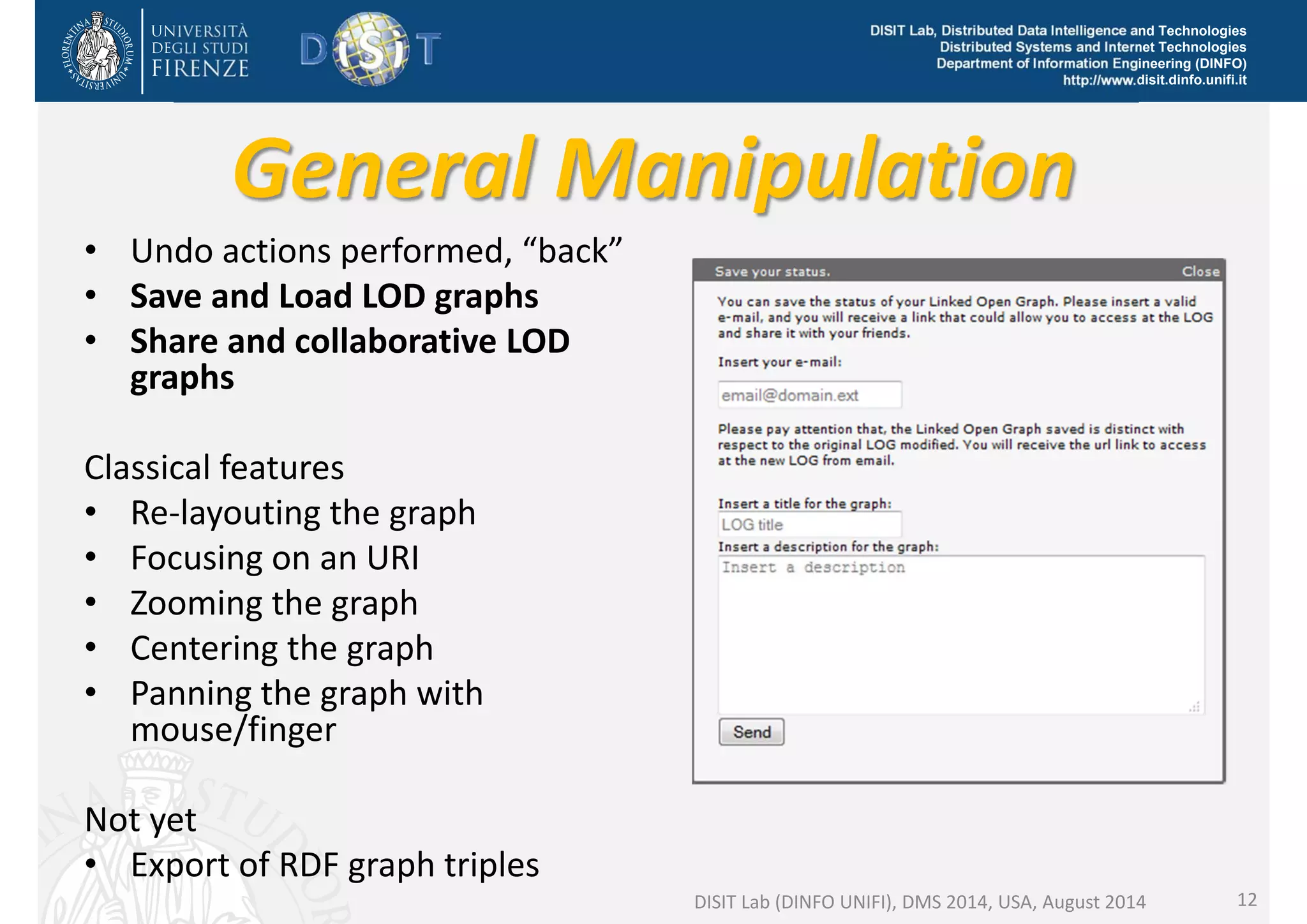

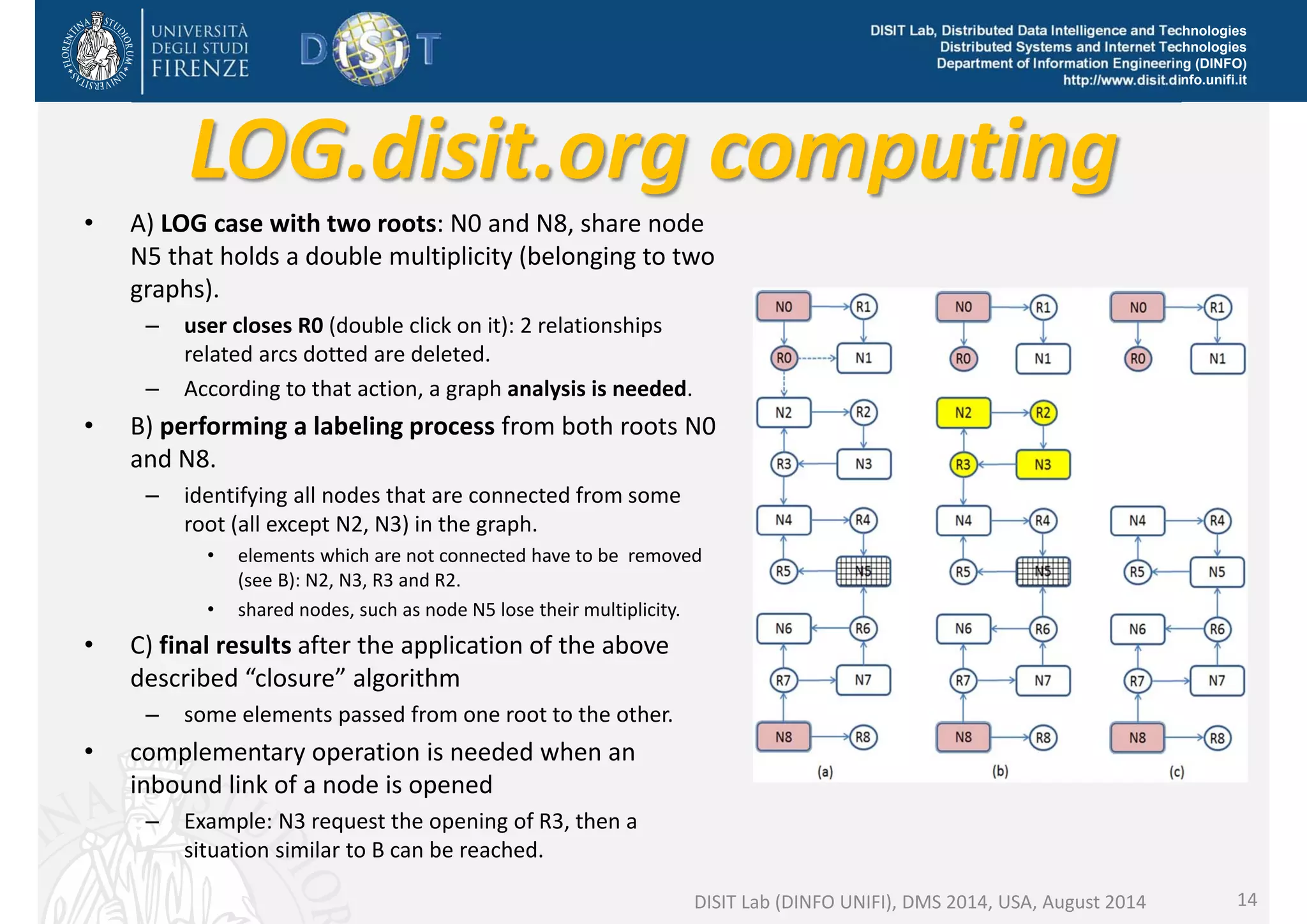
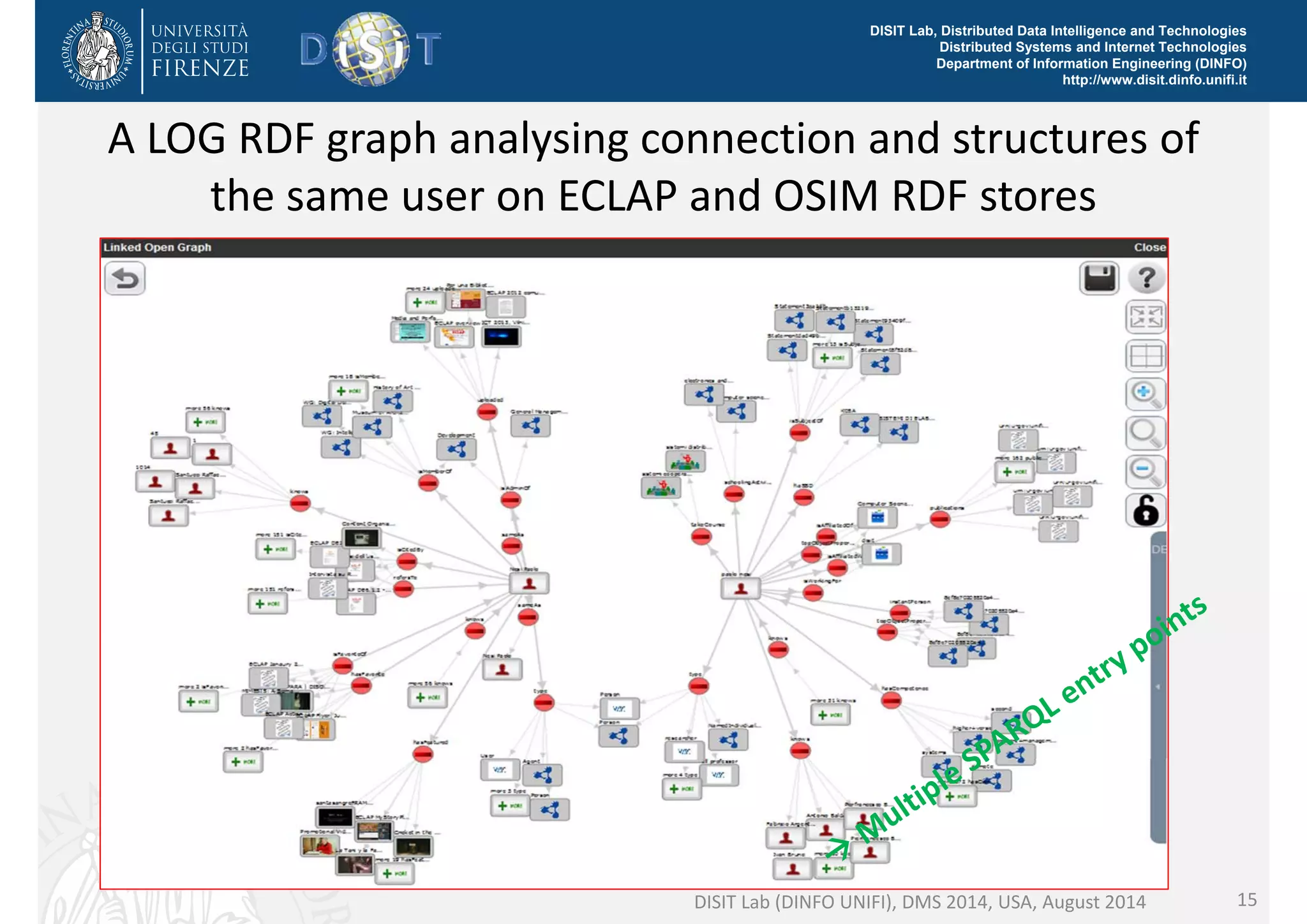





The document discusses the development of a distributed knowledge base (KB) leveraging Linked Open Data (LOD) and RDF technologies through SPARQL entry points. It outlines major features for accessing, querying, and manipulating linked data and emphasizes the integration and comparison of multiple data sources for enhanced understanding and exploration. The proposed model, log.disit, aims to support collaborative work, progressive browsing, and advanced querying capabilities in the domain of semantic web applications.










































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











