Downloaded 14 times




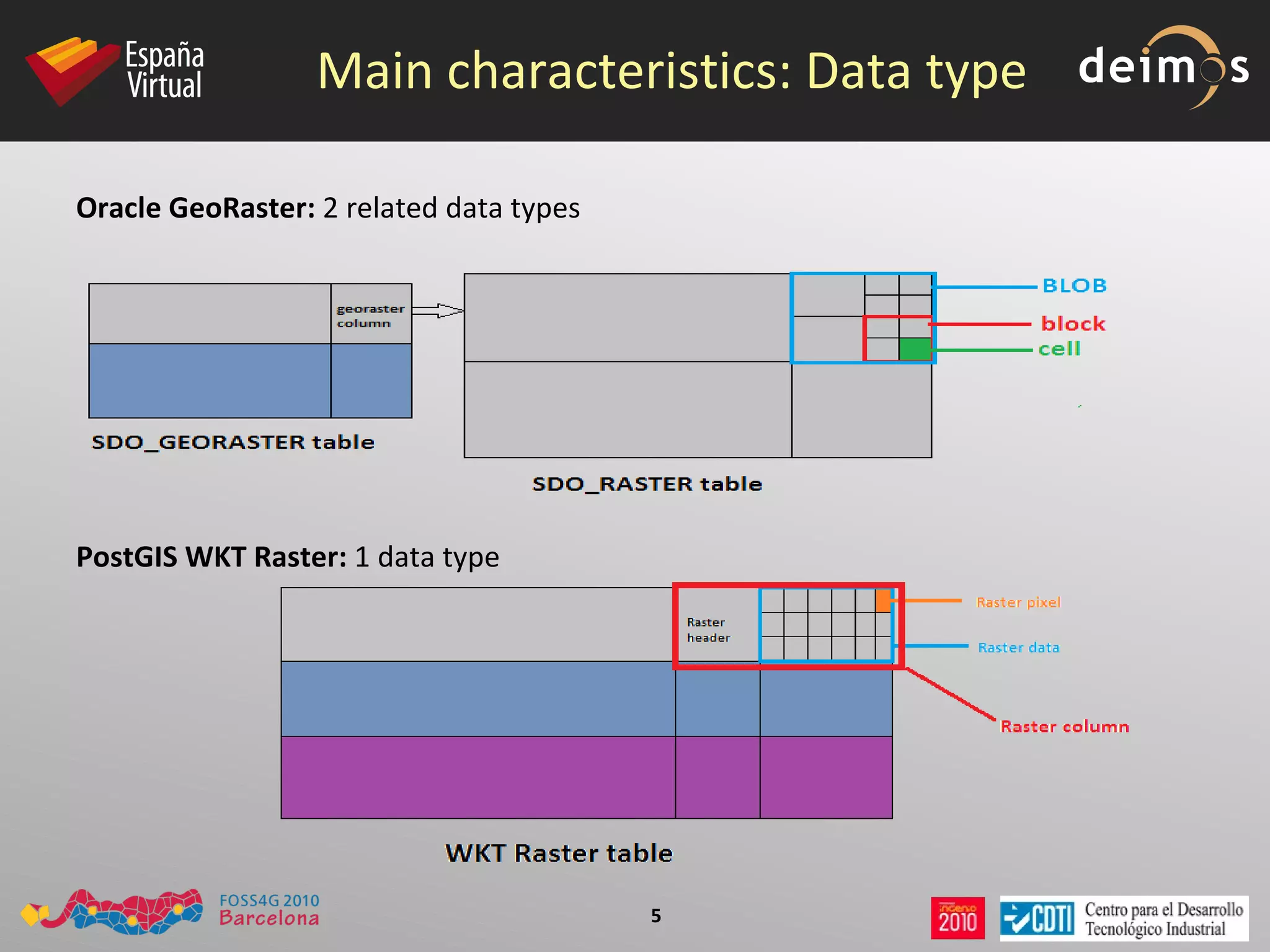
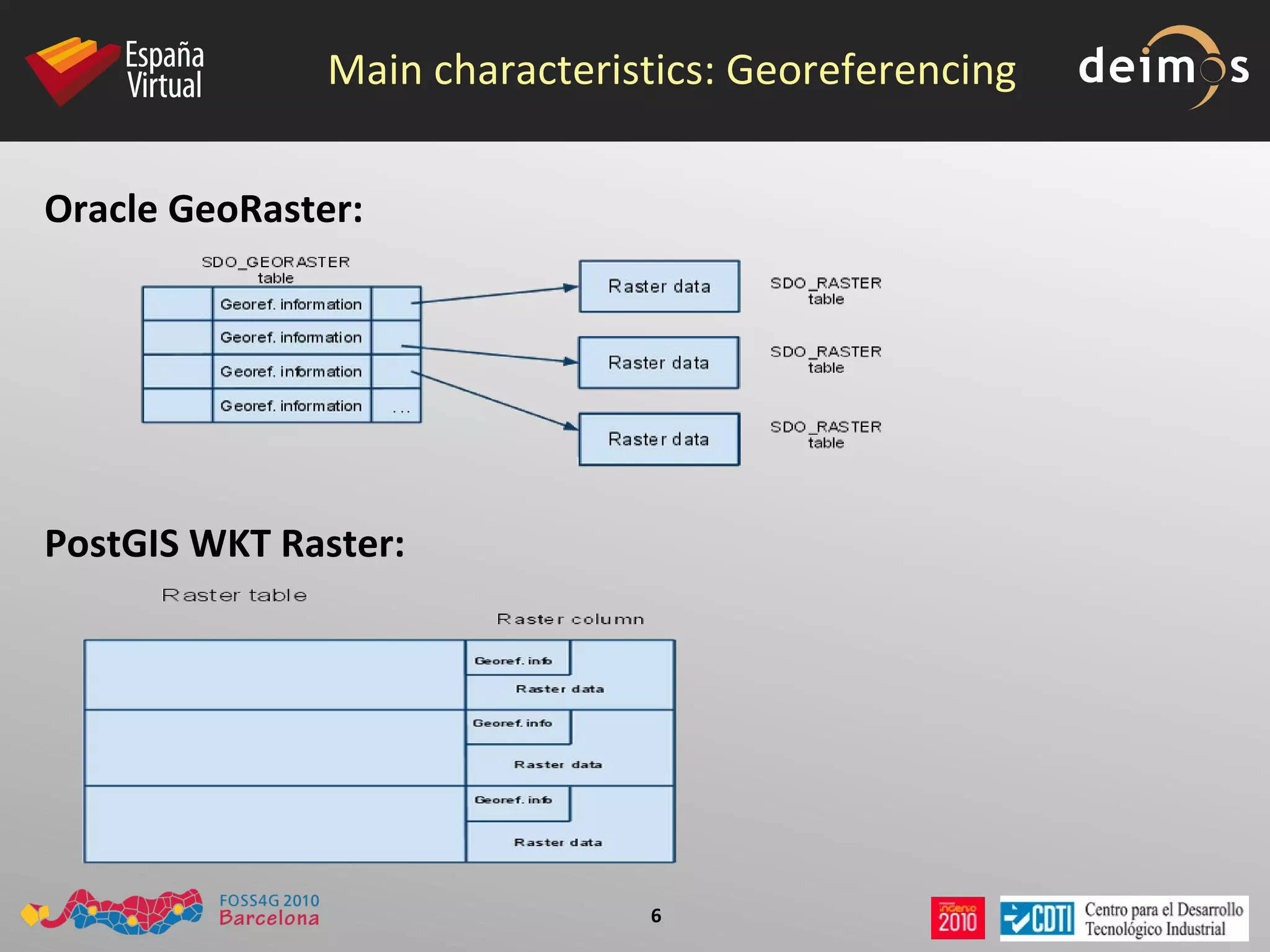






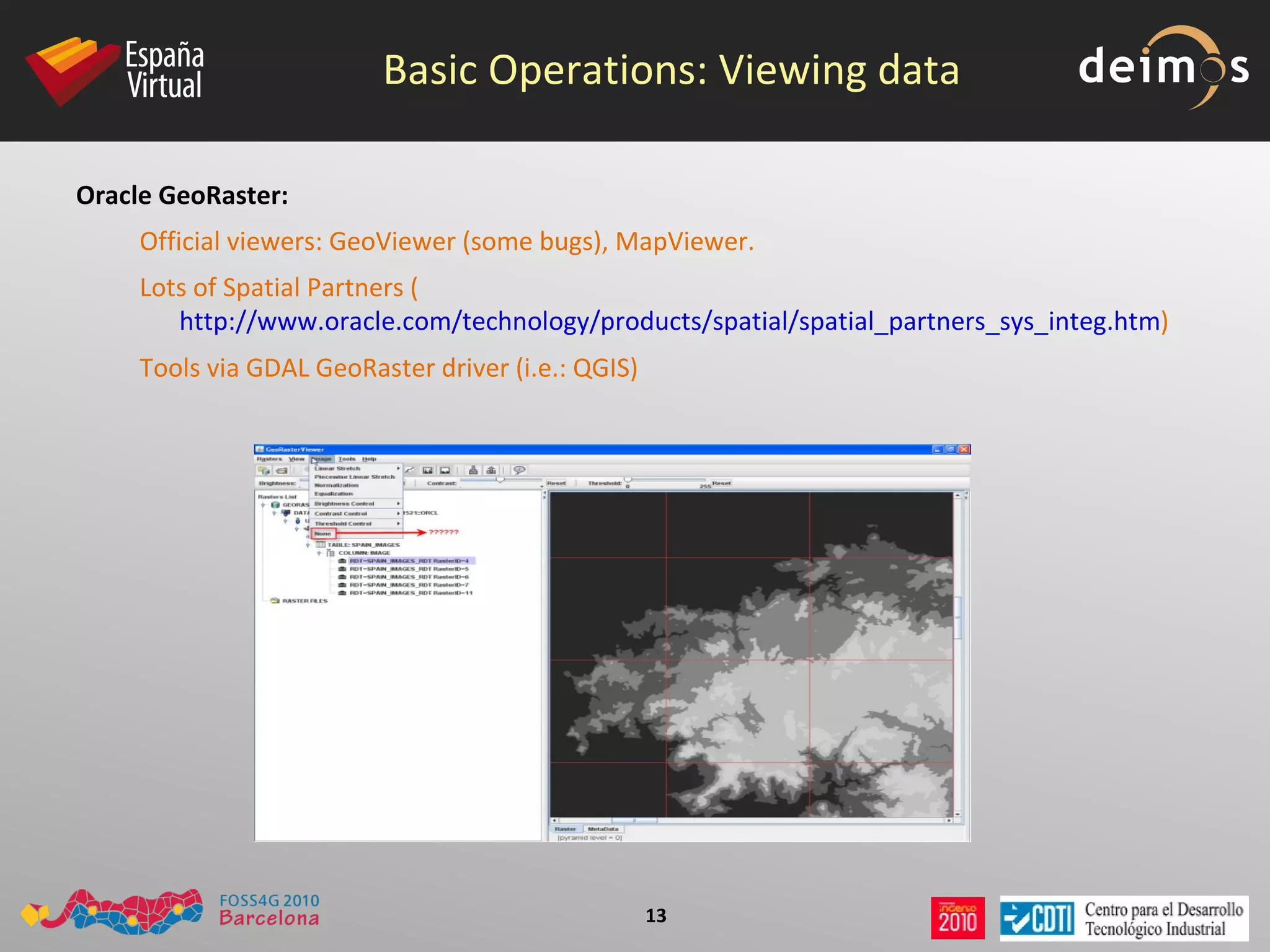




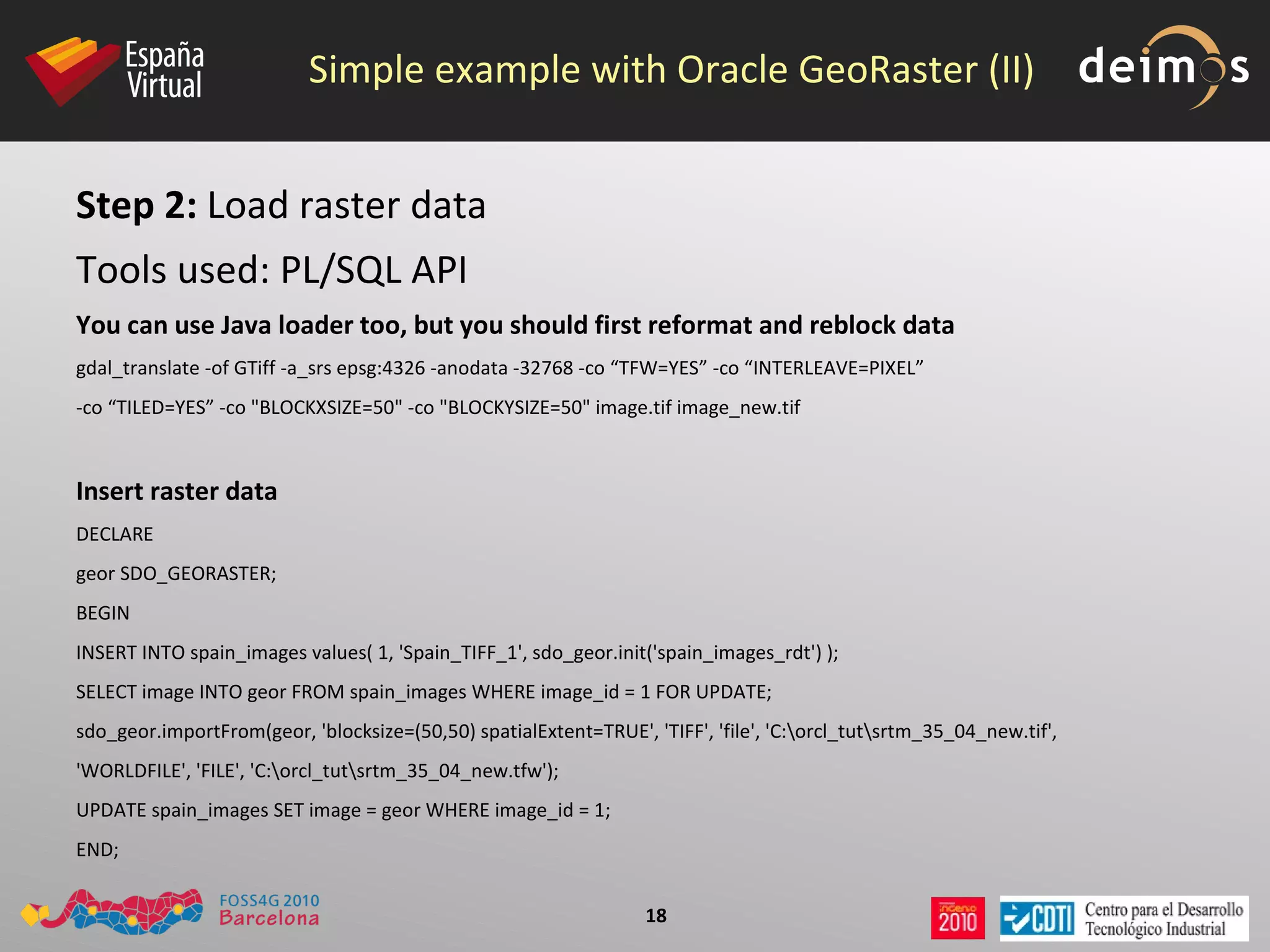
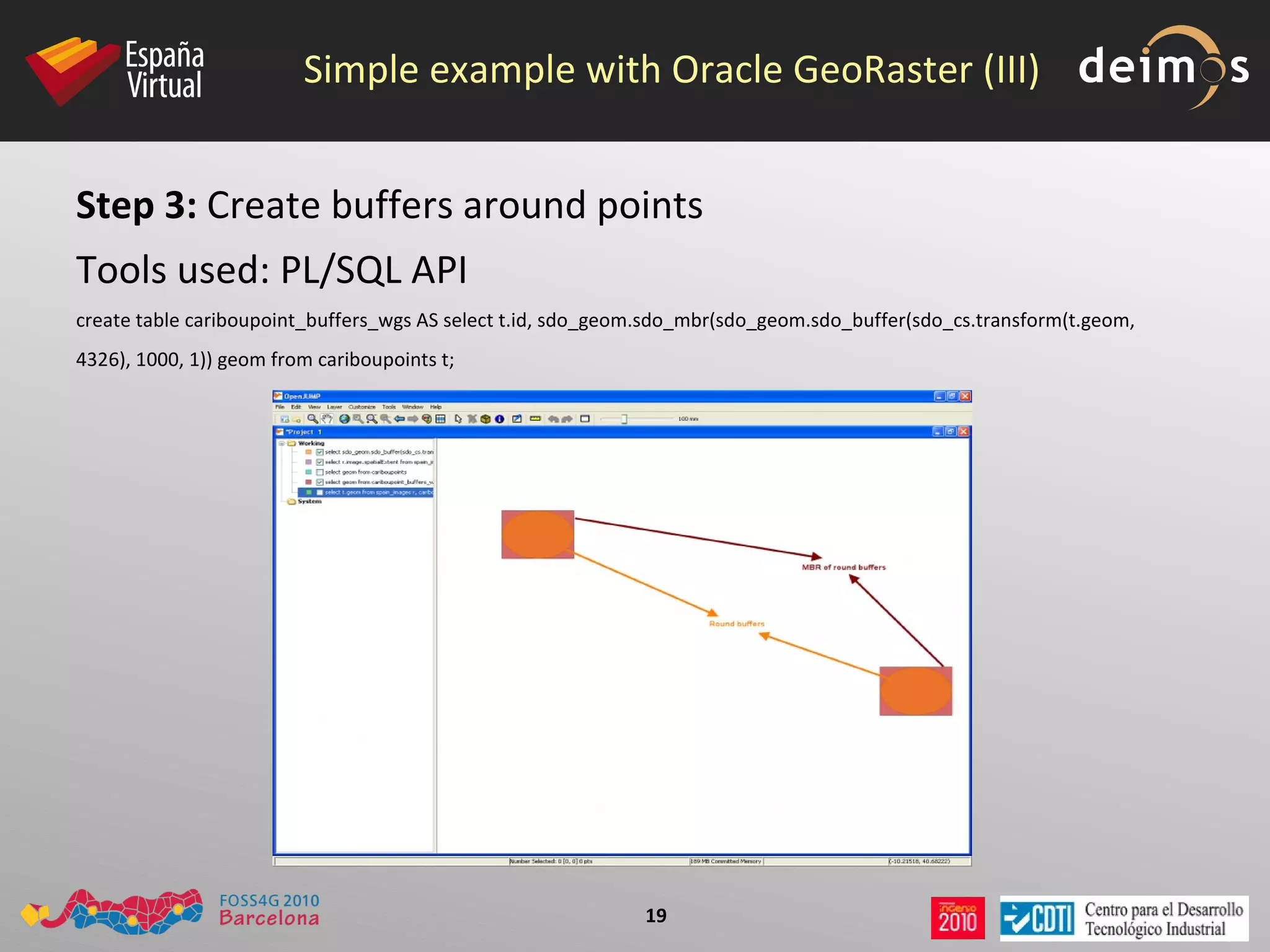





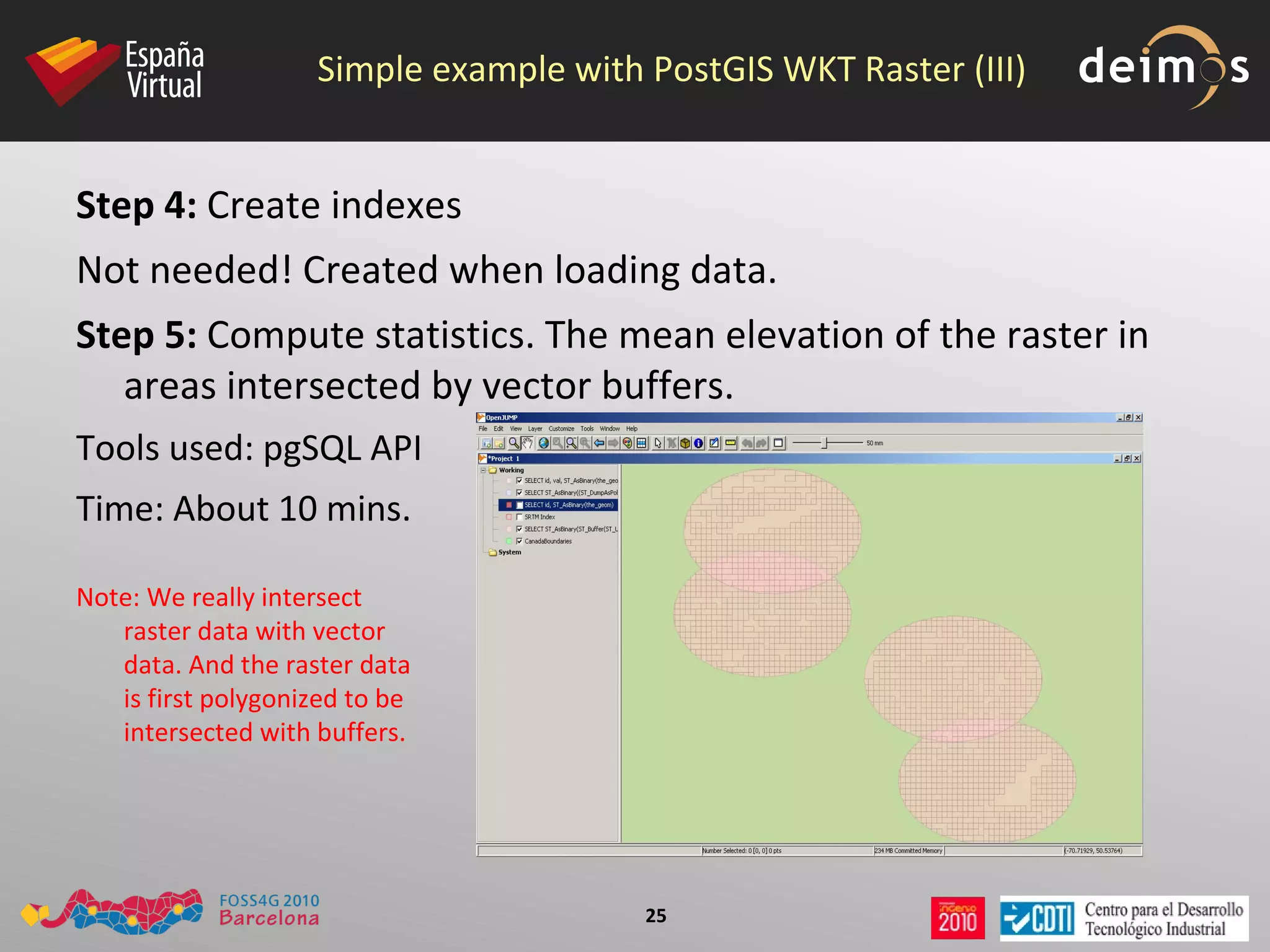

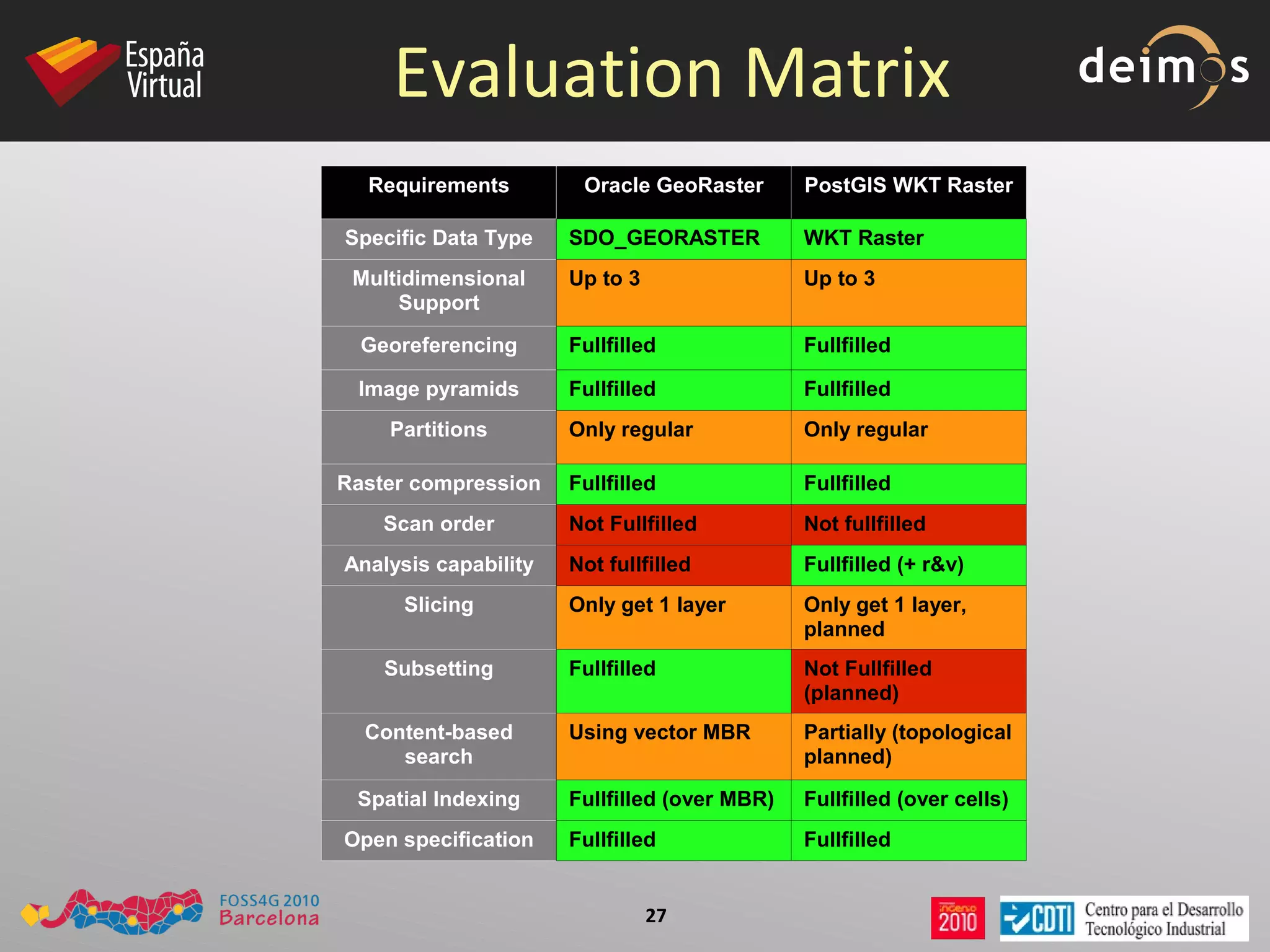



PostGIS WKT Raster is an open source alternative to Oracle GeoRaster that allows raster data to be stored and analyzed in a PostgreSQL/PostGIS database. It uses the Well-Known Text (WKT) format to represent raster data as a single data type, while Oracle GeoRaster uses two related data types. PostGIS WKT Raster supports indexing and analysis of both raster and vector data, unlike Oracle GeoRaster which only allows analysis of raster data using vector extents.























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











