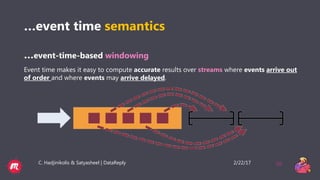
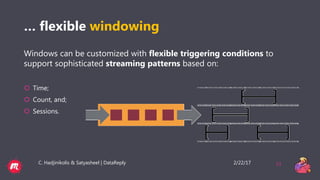
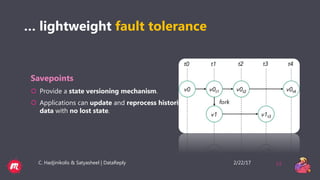
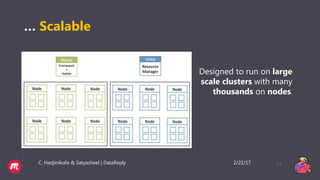
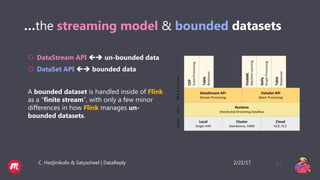
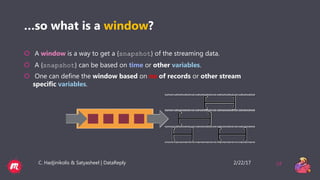
This document provides a tutorial overview of Apache Flink, including what Flink is, why it is useful, how it processes both bounded and unbounded data, the anatomy of a Flink application, windowing in Flink, and how it handles event time and process time. Flink is an open-source stream and batch processing platform that can process infinite datasets continuously while maintaining accuracy and recovering from failures. It provides exactly-once semantics through checkpointing and handles both bounded finite datasets and unbounded streaming data through its DataStream and DataSet APIs. The tutorial then discusses windowing concepts in Flink and provides code examples of word count applications with and without windows. It also explains the concepts of event time and processing time in F