Downloaded 35 times




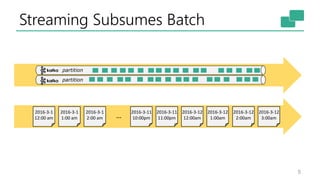
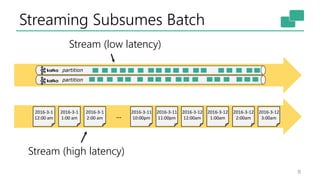
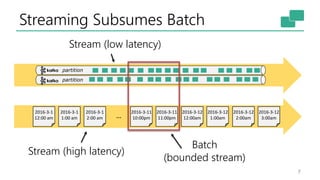
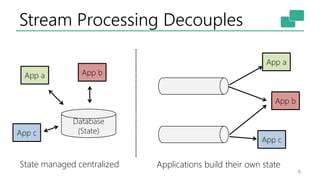
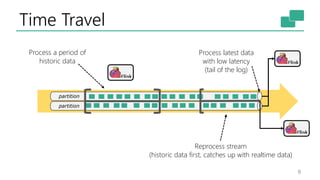

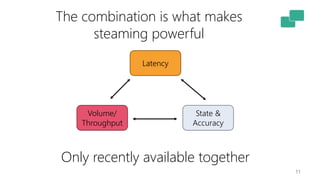
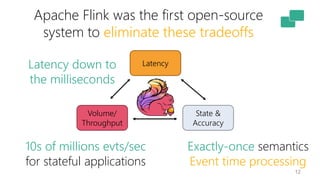
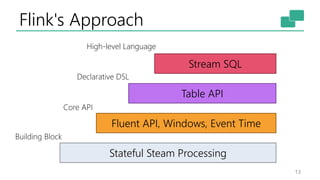
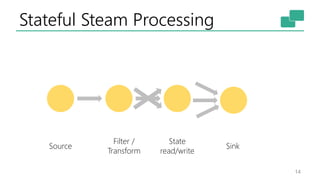
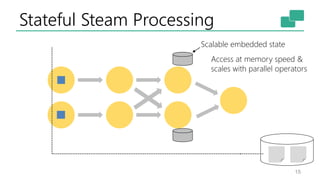
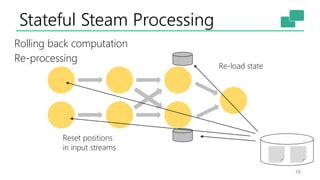
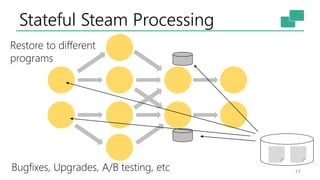

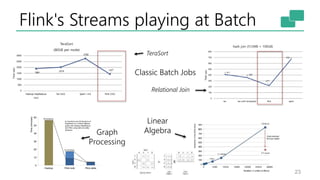

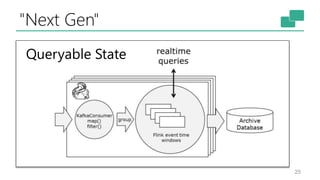
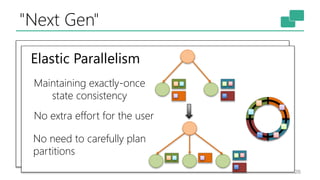






This document discusses the significance of stream processing as a key paradigm, highlighting Apache Flink's approach to enable continuous data processing with low latency and high throughput. It emphasizes features like stateful stream processing, exactly-once semantics, and various APIs for building applications, while also addressing the scalability and performance of Flink. The author presents future directions for stream processing technology, including queryable states and full SQL capabilities on streams.































































































