Download to read offline







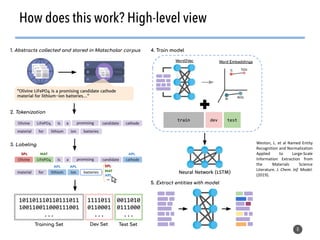
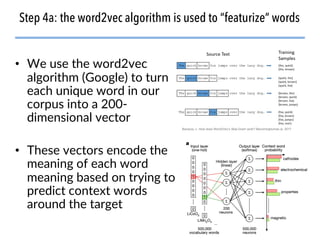


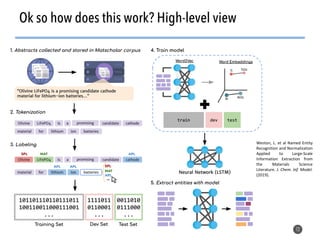

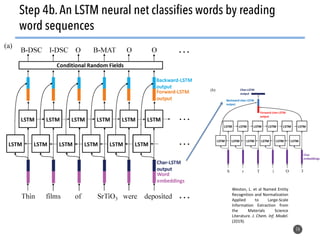
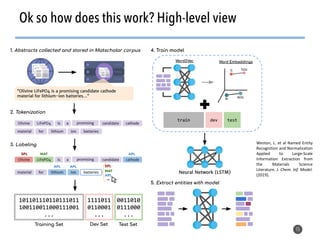

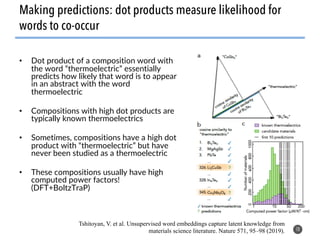
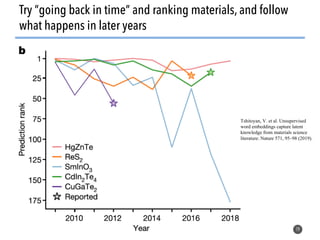






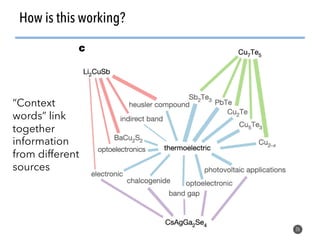


The document discusses the use of natural language processing (NLP) techniques to extract and organize knowledge from millions of materials science journal articles. It specifically highlights the Matscholar project, which employs named entity recognition to facilitate searches and data extraction in materials science literature. The project has collected over 4 million papers, enabling users to connect various topics and materials compositions effectively.























































































