Download to read offline

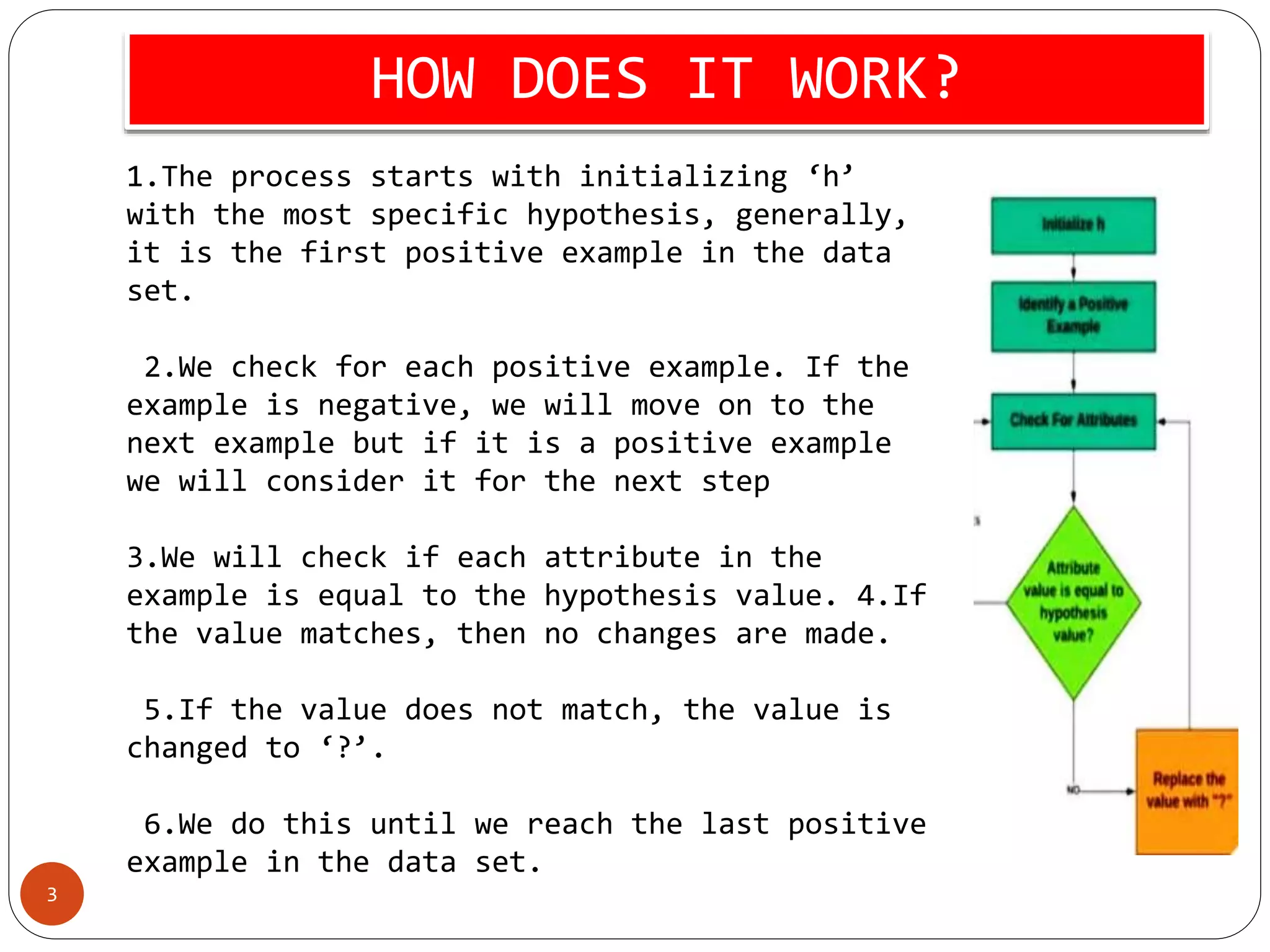


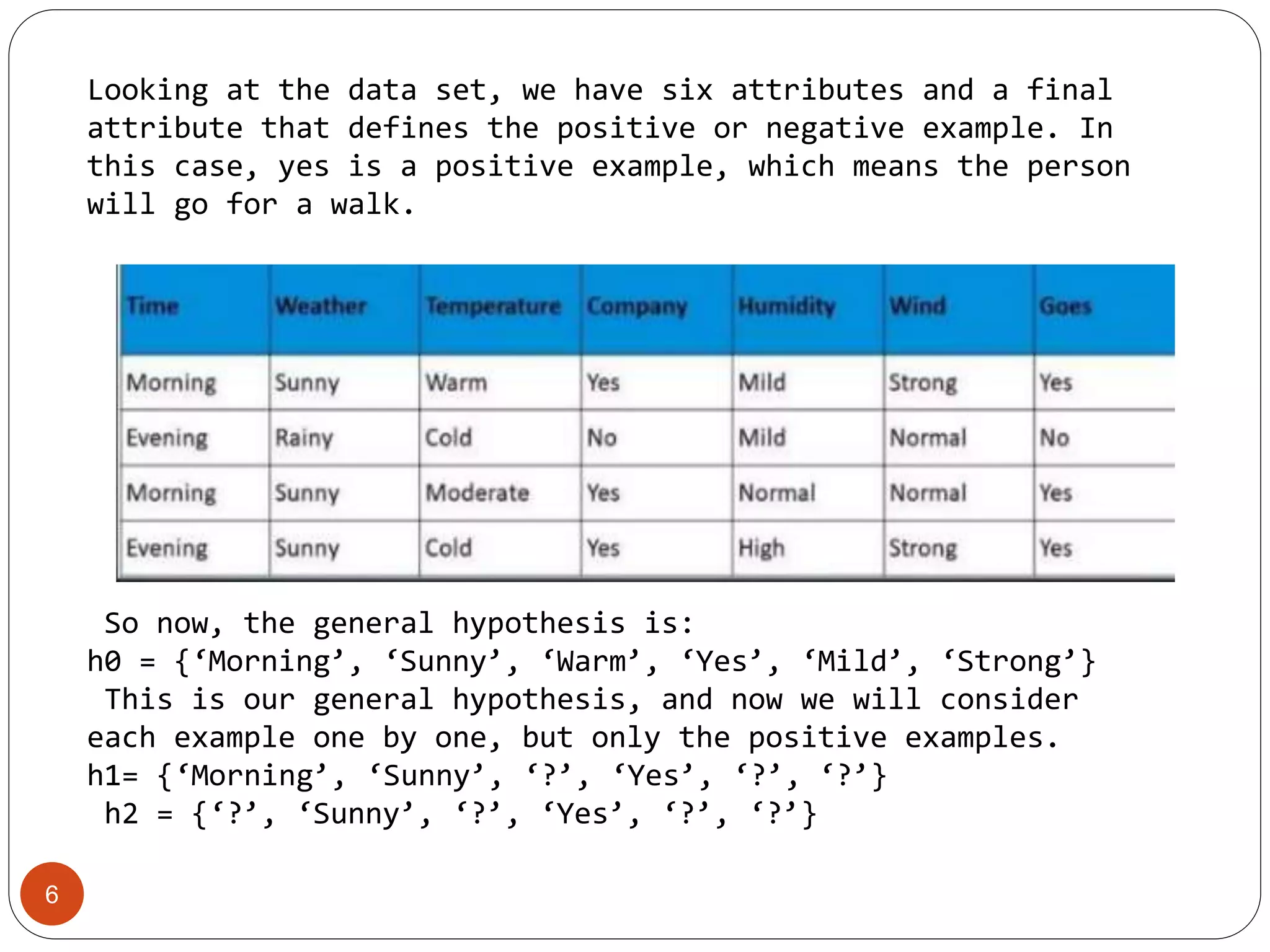


The Find-S algorithm is a fundamental concept learning algorithm in machine learning that identifies the most specific hypothesis matching all positive training cases. It begins by initializing the hypothesis to the first positive example and generalizes it as needed based on subsequent positive instances. Limitations include its inability to assess hypothesis consistency across data and ignoring negative examples, which can lead to misleading outcomes.



































































