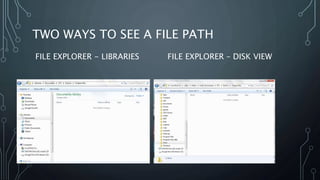
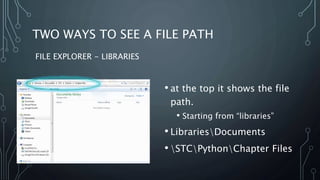
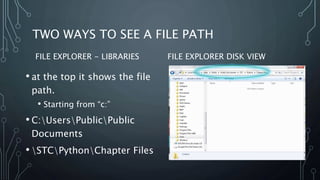
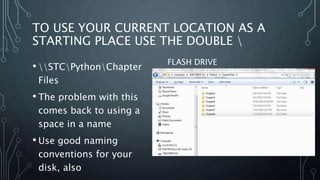
The document explains file paths in programming, detailing how programs locate data and module files first in the current directory and then in specified file paths. It describes two methods to view file paths using File Explorer—one from 'libraries' and the other from 'disk view.' Additionally, it emphasizes the importance of using proper naming conventions and sharing practices when using files across different computers.