Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
YM
Uploaded by
Yuto Mori
PDF, PPTX
17,003 views
One Class SVMを用いた異常値検知
Anomaly detection using One Class SVM
Technology
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 40
2
/ 40
3
/ 40
4
/ 40
5
/ 40
6
/ 40
7
/ 40
8
/ 40
9
/ 40
10
/ 40
11
/ 40
12
/ 40
Most read
13
/ 40
14
/ 40
15
/ 40
16
/ 40
17
/ 40
18
/ 40
19
/ 40
20
/ 40
21
/ 40
22
/ 40
Most read
23
/ 40
24
/ 40
25
/ 40
26
/ 40
27
/ 40
28
/ 40
29
/ 40
30
/ 40
31
/ 40
32
/ 40
33
/ 40
34
/ 40
35
/ 40
36
/ 40
37
/ 40
Most read
38
/ 40
39
/ 40
40
/ 40
More Related Content
PDF
Jubatus Casual Talks #2 異常検知入門
by
Shohei Hido
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
劣モジュラ最適化と機械学習1章
by
Hakky St
PDF
Transformerを用いたAutoEncoderの設計と実験
by
myxymyxomatosis
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
Jubatus Casual Talks #2 異常検知入門
by
Shohei Hido
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
機械学習モデルの判断根拠の説明
by
Satoshi Hara
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
劣モジュラ最適化と機械学習1章
by
Hakky St
Transformerを用いたAutoEncoderの設計と実験
by
myxymyxomatosis
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
What's hot
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
PDF
最適輸送の解き方
by
joisino
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
PDF
グラフニューラルネットワークとグラフ組合せ問題
by
joisino
PDF
“機械学習の説明”の信頼性
by
Satoshi Hara
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PPTX
[DL輪読会]When Does Label Smoothing Help?
by
Deep Learning JP
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
PDF
MICの解説
by
logics-of-blue
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PPTX
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
PDF
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
PDF
全力解説!Transformer
by
Arithmer Inc.
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
by
Shota Imai
最適輸送の解き方
by
joisino
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
グラフニューラルネットワークとグラフ組合せ問題
by
joisino
“機械学習の説明”の信頼性
by
Satoshi Hara
最適輸送の計算アルゴリズムの研究動向
by
ohken
[DL輪読会]When Does Label Smoothing Help?
by
Deep Learning JP
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
MICの解説
by
logics-of-blue
機械学習のためのベイズ最適化入門
by
hoxo_m
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
全力解説!Transformer
by
Arithmer Inc.
Similar to One Class SVMを用いた異常値検知
PPTX
DLLab 異常検知ナイト 資料 20180214
by
Kosuke Nakago
PPTX
異常検知と変化検知の1~3章をまとめてみた
by
Takahiro Yoshizawa
PDF
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011
by
Preferred Networks
PDF
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
Introduction to ensemble methods for beginners
by
Shinsaku Kono
PDF
R実践 機械学習による異常検知 02
by
akira_11
PPTX
Rで学ぶデータサイエンス第1章(判別能力の評価)
by
Daisuke Yoneoka
PDF
[DL輪読会]A Simple Unified Framework for Detecting Out-of-Distribution Samples a...
by
Deep Learning JP
PDF
コンピュータ先端ガイド2巻3章勉強会(SVM)
by
Masaya Kaneko
PDF
Anomaly detection survey
by
ぱんいち すみもと
PDF
【CVPR 2019】Striking the Right Balance with Uncertainty
by
cvpaper. challenge
PDF
bigdata2012ml okanohara
by
Preferred Networks
PDF
Dbda chapter15
by
Amarsanaa Agchbayar
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
Active learning with efficient feature weighting methods for improving data q...
by
Shunsuke Kozawa
PDF
異常検知
by
Yasuaki Sakamoto
PDF
Sakusaku svm
by
antibayesian 俺がS式だ
PDF
Infinite SVM - ICML 2011 読み会
by
Shuyo Nakatani
PDF
Rで学ぶロバスト推定
by
Shintaro Fukushima
DLLab 異常検知ナイト 資料 20180214
by
Kosuke Nakago
異常検知と変化検知の1~3章をまとめてみた
by
Takahiro Yoshizawa
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011
by
Preferred Networks
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
不均衡データのクラス分類
by
Shintaro Fukushima
Introduction to ensemble methods for beginners
by
Shinsaku Kono
R実践 機械学習による異常検知 02
by
akira_11
Rで学ぶデータサイエンス第1章(判別能力の評価)
by
Daisuke Yoneoka
[DL輪読会]A Simple Unified Framework for Detecting Out-of-Distribution Samples a...
by
Deep Learning JP
コンピュータ先端ガイド2巻3章勉強会(SVM)
by
Masaya Kaneko
Anomaly detection survey
by
ぱんいち すみもと
【CVPR 2019】Striking the Right Balance with Uncertainty
by
cvpaper. challenge
bigdata2012ml okanohara
by
Preferred Networks
Dbda chapter15
by
Amarsanaa Agchbayar
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
Active learning with efficient feature weighting methods for improving data q...
by
Shunsuke Kozawa
異常検知
by
Yasuaki Sakamoto
Sakusaku svm
by
antibayesian 俺がS式だ
Infinite SVM - ICML 2011 読み会
by
Shuyo Nakatani
Rで学ぶロバスト推定
by
Shintaro Fukushima
Recently uploaded
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
One Class SVMを用いた異常値検知
1.
One Class SVMを用いた 異常値検知 Anomaly
detection using One Class SVM 公立はこだて未来大学 森雄斗 1
2.
概要 教師なし学習により、データのパターンを学習させ、パター ンから外れたデータを異常値として検出する 検出方法は、One
Class SVMを利用する。 前回マハラノビス距離で行ったことを再度One Class SVMで 行う。 →https://www.slideshare.net/YutoMori2/ss-88160534 2
3.
One Class SVM
とは SVM(サポートベクトルマシン)の中の一種。 SVMは教師あり学習であるのに対して、OneClassSVMは教 師なし学習である。 One Class SVMは異常値検知によく用いられる。 3
4.
実験環境 Python 3.6.0 numpy,
pandas, mmatplotlib, sklearn, time, plotly 実際のデータ(全てが正常値) MachineA.csv → 22670個 × 3 (x軸, y軸, z軸) MachineB.csv → 18700個 × 3 (x軸, y軸, z軸) 4
5.
MachineBのデータに異常値を追加する マハラノビス距離が1.5794である異常値(-0.39, -0.73, 2.235)を追加する。 5 赤点が異常値
6.
Class sklearn.svm.OneClassSVM One class
SVMを適応するのは2行 clf = svm.OneClassSVM() clf.fit(データ) 課題はパラメータの調整(チューニング) 6
7.
パラメータについて デフォルトのパラメータ OneClassSVM(cache_size=200, coef0=0.0,
degree=3, gamma=‘auto’, kernel='rbf‘, max_iter=-1, nu=0.5, random_state=None, shrinking=True, tol=0.001, verbose=False) 今回重要なのは”gamma”と”nu”. gamma = ‘auto’ = 1 / n_features = 0.5 7 つまり、3変数でも出来るのでは….
8.
パラメータについて nu 異常データの割合….?(0~1) gamma RBFカーネルのパラメータ…? →値が大きいほど境界が複雑になる…? 8 正直あまりわかっていないので実際に数値を変えて検証する
9.
2変数分析 (XYの関係, XZの関係, YZの関係) 9
10.
2変数分析の説明10 dataXY = np.vstack([dataX,
dataY]).T dataXZ = np.vstack([dataX, dataZ]).T dataYZ = np.vstack([dataY, dataZ]).T clf.fit(dataXY) y_pred = clf.predict(dataXY) clf.fit(dataXZ) y_pred = clf.predict(dataXZ) clf.fit(dataYZ) y_pred = clf.predict(dataYZ) それぞれに対してSVMを用いる
11.
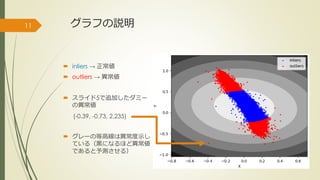
グラフの説明 inliers →
正常値 outliers → 異常値 スライド5で追加したダミー の異常値 (-0.39, -0.73, 2.235) グレーの等高線は異常度示し ている(黒になるほど異常値 であると予測させる) 11
12.
デフォルト(nu=0.5, gamma=0.5) XYの関係
MachineB 実行時間 =194.1s 12
13.
デフォルト(nu=0.5, gamma=0.5)13 XZの関係
MachineB 実行時間 =194.1s
14.
デフォルト(nu=0.5, gamma=0.5)14 YZの関係
MachineB 実行時間 =194.1s
15.
パラメータ調整15 nu = 0.5
→ nu = 0.1
16.
nu=0.1, gamma=0.516 XYの関係
MachineB 実行時間 =37.2s
17.
nu=0.1, gamma=0.517 XZの関係
MachineB 実行時間 =37.2s
18.
nu=0.1, gamma=0.518 YZの関係
MachineB 実行時間 =37.2s
19.
パラメータ調整19 この作業を繰り返す….
20.
パラメータ nu について20 gamma
= 0.5を固定 XYの関係 nu = 0.001 nu = 0.0001 0.001~0.0001の間に異常値を正常値と判断し、異常度等高線が大きく変化する
21.
パラメータ nu について21 (1)
nu = 0.001 ●nu = 0.002のOne Class SVMを適応したグラフ(2) 正常値: 18664, 異常値: 37, 計: 18701 18704 * 0.002 = 37.4 ≒ 37 (2) nu = 0.002 ○入力データ MachineB_dummy.csv 正常値: 18700, 異常値: 1, 計: 18701 ●nu = 0.001のOne Class SVMを適応したグラフ(1) 正常値: 18682, 異常値: 19, 計: 18701 18701 * 0.001 = 18.7 ≒ 19
22.
パラメータ nu のまとめ
パラメータ nu は入力データの異常値の割合であることが明らかである。 異常値の割合が0.0001のような小さい値をとると極度に異常であるデー タを正常値と判断してしまう可能性がある。 nuが小さくなればなるほど、異常度等高線が適切なものになる。 22
23.
パラメータ gamma について23 nu
= 0.001を固定 YZの関係 gamma = 0.5 gamma = 1.0 gamma値の大小で汎化能力が変化する (汎化能力: 規則性の当てはまり)
24.
パラメータ gamma について24 nu
= 0.001を固定 YZの関係 gamma = 3.0 gamma = 10.0 gamma値を上げすぎると過学習状態に...
25.
汎化能力と過学習25 汎化能力 (generalization) 過学習 (overfitting) 最適な学習モデルは、「過学習が起こらず、汎化性能に優れたもの」
26.
3変数分析 (XYZの関係) 26
27.
3変数分析の説明27 dataXYZ = np.vstack([dataX,
dataY, dataZ]).T clf.fit(dataXYZ) y_pred = clf.predict(dataXYZ) dataXYZ [[ 0.068 0.228 1.484] [-0.18 0.816 1.344] [-0.108 0.392 0.932] ..., [-0.132 0.692 1.572] [-0.168 0.564 1.076] [-0.39 -0.73 2.235]] y_pred [ 1 1 1 ..., 1 1 -1] python print 1: 正常値 -1: 異常値
28.
plotlyによる描写28 パラメータ: Nu = 0.001,
gamma = 1 URL : https://www.youtube.com/watch?v=Tu3wEj0Inc0
29.
matplotlibによる描写29 3変数で分析したものを 2変数に変換したもの
30.
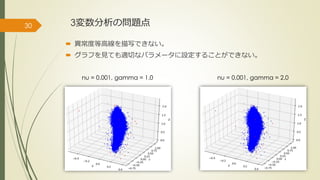
3変数分析の問題点30 nu = 0.001,
gamma = 1.0 nu = 0.001, gamma = 2.0 異常度等高線を描写できない。 グラフを見ても適切なパラメータに設定することができない。
31.
分類器の性能評価(分割表)31 分割表 正常値(inliers) 異常値(outliers) 正常値(inliers) True Positive(TP) False Negative(FN) 異常値(outliers) False Positive(FP) True Negative(TN) 実際 予測
32.
分類器の性能評価(Weighted F-measure)32 重み付きF値(Weighted
F-measure) とは ラベル間のデータ数が大きく異なる場合によく使われる指標 今回は偽陽性(本当は異常値であるのに検査結果で正常と出ること)を低く 抑えたいので, 適合率に重さを付ける(1 < β) 適合率(Precision) = 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 + 𝑓𝑎𝑙𝑠𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 再現率(Recall) = 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 +𝐹𝑎𝑙𝑠𝑒 𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒 重み付きF値(Weighted F-measure) = 1+ 𝛽2 ∙𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 ∙ 𝑅𝑒𝑐𝑎𝑙𝑙 𝛽2 ∙ 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑅𝑒𝑐𝑎𝑙𝑙 https://www.quora.com/What-is-meant-by-F-measure-Weighted-F-Measure-and-Average-F-Measure-in-NLP-Evaluation
33.
偽陽性率と真陽性率33 False Positive
Rate(偽陽性率) = 𝐹𝑎𝑙𝑠𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝐹𝑎𝑙𝑠𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 + 𝑇𝑟𝑢𝑒 𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒 異常値であるものを間違って正常と予測した割合 True Positive Rate(真陽性率) = 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒+𝐹𝑎𝑙𝑠𝑒 𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒 正常値であるものを正しく正常と予測した割合
34.
3変数分析のダミーを設定(Y軸, Z軸のみ)34 右図に該当しない候補 (x,
y, z) = (?, -0.75, 1.9), ( ?, 0.00, 2.0), (?, 0.65, 2.1), (?, 1.7, 1.00), (?, 1.88, 0.65), (?, 0.75, 0.2), (?, -1.2, 0.25), (?, -0.50, -1.2), 実際のデータのみ
35.
3変数分析のダミーを設定(X軸, y軸, Z軸)35
右図に該当しないように設定 (x, y, z)= (-0.45, -0.75, 1.9), (0.9, -0.75, 1.9), (-0.7, 0.00, 2.0), (0.81, 0.00, 2.0), (-0.8, 0.65, 2.1), (0.45, 0.65, 2.1), (-0.3, 1.7, 1.00), (0.02, 1.7, 1.00), (-0.4, 1.88, 0.65), (-0.22, 1.88, 0.65), (-0.91, 0.75, 0.2), (0.53, 0.75, 0.2), (-0.21, -1.2, 0.25), (0.54, -1.2, 0.25), (-0.71, -0.50, -1.2), (0.87, -0.50, -1.2) 実際のデータのみ
36.
性能評価によるパラメータ設定36 環境 データの数:
18716, nu = 0.00085 → 約16個選ばれる 今回入れた異常値は16個
37.
性能評価によるパラメータ設定37 gamma 0.00001 0.00005
0.0001 0.001 0.01 0.1 True Positive 3690 18699 18698 18698 18699 18699 False Negative 15010 1 2 2 1 1 False Positive 0 4 1 2 1 2 True Negative 16 12 15 14 15 14 False Positive Rate(%) 0 25 6.25 12.5 6.25 12.5 True Positive Rate(%) 19.7326 99.973 99.989 99.9893 99.994 99.99465
38.
性能評価によるパラメータ設定38 gamma 0.33(auto) 0.5
1.0 2.0 3.5 5.0 True Positive 18699 18700 18697 18693 18689 18683 False Negative 1 0 3 7 11 17 False Positive 1 2 2 6 9 6 True Negative 15 14 14 10 7 10 False Positive Rate(%) 6.25 12.5 12.5 37.5 56.25 37.5 True Positive Rate(%) 99.99465 100.0 99.9839 99.9626 99.9412 99.9091
39.
性能評価によるパラメータ設定39 0.01 <
gamma < 0.5 が適切なパラメータ 右図が全ての異常値を正しく判断したgamma値(0.37) gamma 0.37 True Positive 18700 False Negative 0 False Positive 0 True Negative 16 False Positive Rate(%) 0.0 True Positive Rate(%) 100.0 URL : https://www.youtube.com/watch?v=6oACtaVSZ2A
40.
まとめ One Class
SVM で教師なし学習を行った。 2変数分析と3変数分析に分けて機械学習を行った。 2変数分析ではパラメータの特徴を理解し、3変数分析ではより正確な異常値検知を行う ことができた。 性能評価を行い、適切なパラメータを見つけた。 40
Download









![2変数分析の説明10
dataXY = np.vstack([dataX, dataY]).T
dataXZ = np.vstack([dataX, dataZ]).T
dataYZ = np.vstack([dataY, dataZ]).T
clf.fit(dataXY)
y_pred = clf.predict(dataXY)
clf.fit(dataXZ)
y_pred = clf.predict(dataXZ)
clf.fit(dataYZ)
y_pred = clf.predict(dataYZ)
それぞれに対してSVMを用いる](https://image.slidesharecdn.com/oneclasssvm-180320081857/85/One-Class-SVM-10-320.jpg)















![3変数分析の説明27
dataXYZ = np.vstack([dataX, dataY, dataZ]).T
clf.fit(dataXYZ)
y_pred = clf.predict(dataXYZ)
dataXYZ
[[ 0.068 0.228 1.484]
[-0.18 0.816 1.344]
[-0.108 0.392 0.932]
...,
[-0.132 0.692 1.572]
[-0.168 0.564 1.076]
[-0.39 -0.73 2.235]]
y_pred
[ 1 1 1 ..., 1 1 -1]
python print
1: 正常値
-1: 異常値](https://image.slidesharecdn.com/oneclasssvm-180320081857/85/One-Class-SVM-27-320.jpg)



















![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)













![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]A Simple Unified Framework for Detecting Out-of-Distribution Samples a...](https://cdn.slidesharecdn.com/ss_thumbnails/20181005misono2-181009052706-thumbnail.jpg?width=640&height=640&fit=bounds)























