Downloaded 45 times



















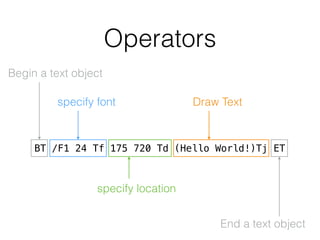







![CMap example
%!PS-Adobe-3.0 Resource-CMap
%%Version: 1
/CIDInit /ProcSet findresource begin
12 dict begin
begincmap
/CIDSystemInfo 3 dict dup begin
/Registry (Adobe) def
/Ordering (Japan1) def
/Supplement 0 def
end def
/CMapName /83pv-RKSJ-H def
/CMapVersion 1 def
/CMapType 0 def
/UIDOffset 0 def
/XUID [1 10 25324] def
/WMode 0 def
4 begincodespacerange
<00> <80>
<8140> <9ffc>
<a0> <df>
<e040> <fbfc>
endcodespacerange
1 beginnotdefrange
<00> <1f> 1
endnotdefrange
100 begincidrange
<9780> <97fc> 3914
<9840> <9872> 4039
<989f> <98fc> 4090
<9940> <997e> 4184
<9980> <99fc> 4247
<< 90 ranges missing >>
<ed83> <ed83> 7934
<ed84> <ed84> 992
<ed85> <ed85> 7935
<ed86> <ed86> 994
<ed87> <ed87> 7936
endcidrange
17 begincidrange
<ed88> <ed8d> 996
<ed8e> <ed8e> 7937
<< 13 ranges missing >>
<ee9a> <ee9a> 768
<ee9b> <ee9c> 7631
endcidrange
endcmap
CMapName currentdict /CMap defineresource pop
end
end
%%EndResource
%%EOF
←Adobe Japan 1-0
←Horizontal/Vertical
←CID Range
←CID Range](https://image.slidesharecdn.com/parsingpdf-160507164027/85/Extracting-text-from-PDF-iOS-30-320.jpg)
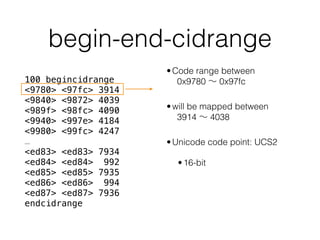



![Adobe Japan 1-6
%!PS-Adobe-3.0 Resource-CMap
/CIDInit /ProcSet findresource begin
12 dict begin
begincmap
/CIDSystemInfo 3 dict dup begin
/Registry (Adobe) def
/Ordering (Japan1) def
/Supplement 6 def
end def
/CMapName /Adobe-Japan1-6 def
/CMapVersion 1.005 def
/CMapType 1 def
/XUID [1 10 25614] def
/WMode 0 def
/CIDCount 23058 def
1 begincodespacerange
<0000> <5AFF>
endcodespacerange
91 begincidrange
<0000> <00ff> 0
<0100> <01ff> 256
<0200> <02ff> 512
<0300> <03ff> 768
<0400> <04ff> 1024
<0500> <05ff> 1280
<0600> <06ff> 1536
<0700> <07ff> 1792
<0800> <08ff> 2048
<0900> <09ff> 2304
…
<5300> <53ff> 21248
<5400> <54ff> 21504
<5500> <55ff> 21760
<5600> <56ff> 22016
<5700> <57ff> 22272
<5800> <58ff> 22528
<5900> <59ff> 22784
<5a00> <5a11> 23040
endcidrange
endcmap
CMapName currentdict /CMap defineresource
pop
end
end
https://github.com/adobe-type-tools/cmap-resources/blob/master/cmapresources_japan1-6/CMap/Adobe-Japan1-6
Be careful, character code may not be Unicode.](https://image.slidesharecdn.com/parsingpdf-160507164027/85/Extracting-text-from-PDF-iOS-35-320.jpg)












This document discusses extracting text from PDF files. It begins by acknowledging that extracting text from PDFs is often considered difficult. It then provides an overview of PDF structure, including pages, fonts, text rendering, and encoding. Various font types like Type 1, TrueType, and CID fonts are described. The challenges of text extraction like multiple encodings and complex documentation are noted. Code examples are provided to demonstrate parsing PDF contents and text. The document concludes by affirming that PDF parsing is indeed a challenging task.