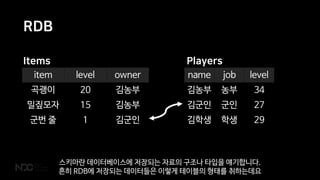
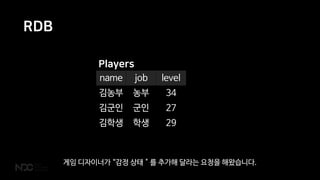
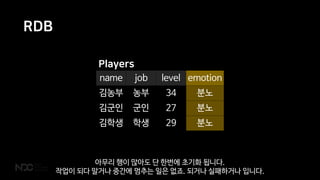
RDB
name job level
김농부농부 34
김군인 군인 27
김학생 학생 29
item level owner
곡괭이 20 김농부
밀짚모자 15 김농부
군번 줄 1 김군인
PlayersItems
스키마란 데이터베이스에 저장되는 자료의 구조나 타입을 얘기합니다.
흔히 RDB에 저장되는 데이터들은 이렇게 테이블의 형태를 취하는데요
15.
Couchbase
{
name: 김농부
job: 농부
level:34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
{
name: 김군인
job: 군인
level: 27
items: [
{item:군번줄,
level:1}
]
}
{
name: 김학생
job: 학생
level: 29
items: []
}
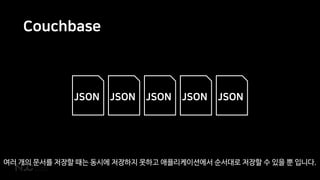
반면 Couchbase는 JSON 기반의 document 데이터베이스이기 때문에
연관된 데이터를 묶어 하나의 문서에 같이 보관하는 경우가 많습니다.
16.
Couchbase
{
name: 김농부
job: 농부
level:34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
1
2
3
4
5
6
7
8
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
JSON으로 저장할 때의 가장 큰 특징은 로직의 데이터 구조와 유사하다는 점 입니다.
JSON이기 때문에 데이터베이스 사용자가 임의로 구조를 정할 수 있기 때문이죠.
17.
Couchbase
{
name: 김농부
job: 농부
level:34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
1
2
3
4
5
6
7
8
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
때문에 RDB와 다르게 메모리 상의 데이터와 DB상의 데이터의 구조를 일치시킬 수 있어
게임 플레이 로직 개발이 굉장히 수월합니다.
RDB
name job levelemotion
김농부 농부 34 분노
김군인 군인 27 분노
김학생 학생 29 분노
Players
아무리 행이 많아도 단 한번에 초기화 됩니다.
작업이 되다 말거나 중간에 멈추는 일은 없죠. 되거나 실패하거나 입니다.
26.
Couchbase
{
name: 김농부
job: 농부
level:34
emotion: 분노
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
Couchbase에서도 하나의 문서를 변경할 땐 ACID 트랜잭션이라고 할 수 있습니다.
읽고, 쓰고, 저장하면 되니까요. 문서 단위로 동작하기 때문에 문서가 저장이 되다가 말거나 하는 일은 없습니다.
Couchbase
{
name: 김농부
job: 농부
level:34
emotion: 분노
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
{
name: 김군인
job: 군인
level: 27
emotion: 분노
items: [
{item:군번줄,
level:1}
]
}
{
name: 김학생
job: 학생
level: 29
items: []
}
때문에 여러 개의 문서를 저장하다 보면 몇 개는 실패할 수도 있죠.
32.
Couchbase
{
name: 김농부
job: 농부
level:34
emotion: 분노
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
JSON 수억개
더군다나 문서가 수억개 쯤 된다면 실패한 것들을 재시도해서 저장하는 것도 쉽지 않은 일이 됩니다.
on-demand migration
1
2
3
4
5
6
7
8
9
10
class Item:
item= declare(unicode)
level = declare(int)
class Entity:
__version__ = 1
job = declare(unicode)
level = declare(int)
emotion = declare(unicode)
items = declare(list(Item))
이렇게 Entity의 버전을 0에서 1로 올리고
37.
on-demand migration
1
2
3
4
5
6
7
8
9
10
@migrate(Entity, 0,1)
def migration(document):
document[‘emotion’] = ‘분노’
def load(cls, key):
doc = db.load(key)
if doc[‘version’] != cls.version:
doc = migrate(doc[‘version’], cls.version, doc)
db.update(key, doc)
return unpack(doc)
버전이 0에서 1로 올라갈 때 문서의 마이그레이션을 어떻게 할지 함수로 만들어 둡니다.
그리고 문서를 애플리케이션에서 읽을 때 저장된 버전이 현재와 다르면 해당 함수를 실행시킵니다.
38.
on-demand migration
{
version: 0
name:김농부
job: 농부
level: 34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
{
version: 1
name: 김군인
job: 군인
level: 27
emotion: 분노
items: [
{item:군번줄,
level:1}
]
}
{
version: 1
name: 김학생
job: 학생
level: 29
emotion: 분노
items: []
}
이렇게 되면 다른 버전의 데이터가 공존할 수 있지만, 어차피 읽어서 쓸 때는 버전이 맞춰지니 괜찮습니다.
on-demand migration
분산된 마이그레이션수행
부담이 적은 점검
점검이 끝나고 버그 발견
하지만 점검이 끝나야 실제 마이그레이션이 산발적으로 진행되기 때문에 버그가 있을 경우 뒷수습이 힘듭니다.
그래서 저희는 마이그레이션 작업이 있을 경우 빼먹지 않도록 관련된 테스트 프로세스를 따로 운영중입니다.
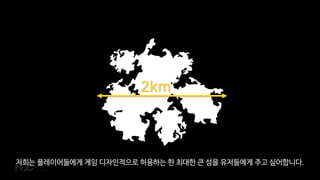
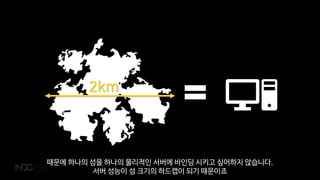
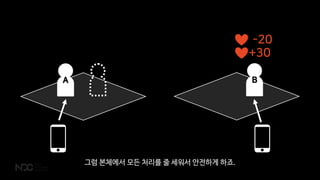
때문에 하나의 섬을하나의 물리적인 서버에 바인딩 시키고 싶어하지 않습니다.
서버 성능이 섬 크기의 하드캡이 되기 때문이죠
44.
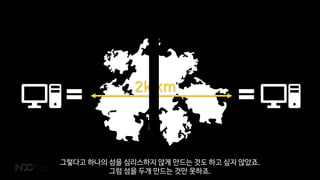
그렇다고 하나의 섬을심리스하지 않게 만드는 것도 하고 싶지 않았죠.
그럼 섬을 두개 만드는 것만 못하죠.
45.
A BA B
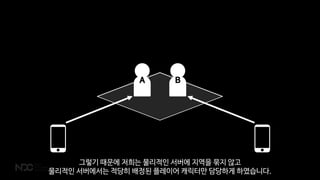
그렇기때문에 저희는 물리적인 서버에 지역을 묶지 않고
물리적인 서버에서는 적당히 배정된 플레이어 캐릭터만 담당하게 하였습니다.
46.
A BA B
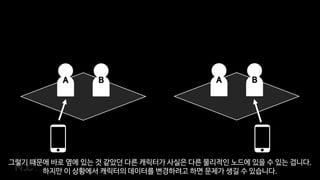
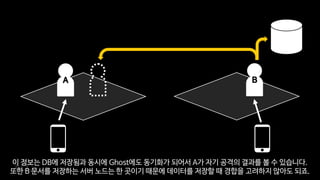
그렇기때문에 바로 옆에 있는 것 같았던 다른 캐릭터가 사실은 다른 물리적인 노드에 있을 수 있는 겁니다.
하지만 이 상황에서 캐릭터의 데이터를 변경하려고 하면 문제가 생길 수 있습니다.
47.
A BA B
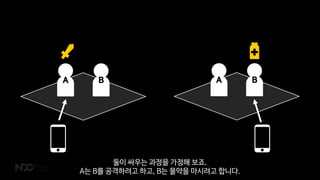
둘이싸우는 과정을 가정해 보죠.
A는 B를 공격하려고 하고, B는 물약을 마시려고 합니다.
48.
A BA B
-20+30
두가지 액션은 다른 캐릭터가 다른 서버에서 진행했지만
결과는 하나의 문서에 반영되어야 합니다.
49.
-20 +30
{
name: B
job:방어자
life: 50
}
{
name: B
job: 방어자
life: 50
}
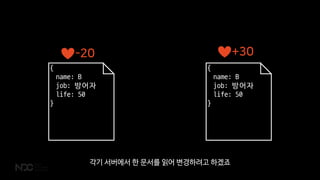
각기 서버에서 한 문서를 읽어 변경하려고 하겠죠
50.
{
name: B
job: 방어자
life:80
}
{
name: B
job: 방어자
life: 30
}
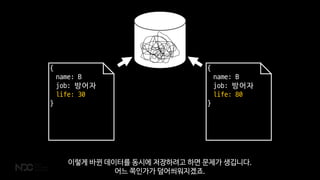
이렇게 바뀐 데이터를 동시에 저장하려고 하면 문제가 생깁니다.
어느 쪽인가가 덮어씌워지겠죠.
51.
CAS
이런 일을 방지하기위해서 Couchbase는 CAS 시스템을 제공합니다.
Check And Set 또는 Compare And Swap이라고 하죠.
52.
{
name: B
job: 방어자
life:50
}
1111
{
name: B
job: 방어자
life: 50
}
1111
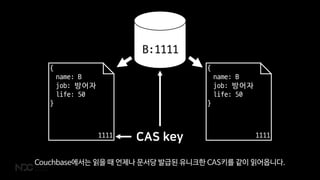
B:1111
CAS key
Couchbase에서는 읽을 때 언제나 문서당 발급된 유니크한 CAS키를 같이 읽어옵니다.
53.
{
name: B
job: 방어자
life:30
}
1111
{
name: B
job: 방어자
life: 80
}
1111
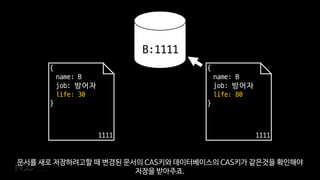
B:1111
문서를 새로 저장하려고할 때 변경된 문서의 CAS키와 데이터베이스의 CAS키가 같은것을 확인해야
저장을 받아주죠.
54.
{
name: B
job: 방어자
life:30
}
1111
{
name: B
job: 방어자
life: 80
}
2222
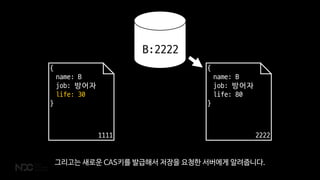
B:2222
그리고는 새로운 CAS키를 발급해서 저장을 요청한 서버에게 알려줍니다.
55.
{
name: B
job: 방어자
life:30
}
1111
{
name: B
job: 방어자
life: 80
}
2222
B:2222
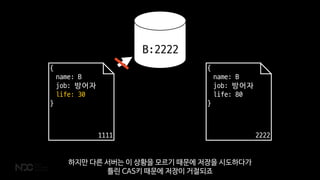
하지만 다른 서버는 이 상황을 모르기 때문에 저장을 시도하다가
틀린 CAS키 때문에 저장이 거절되죠
56.
{
name: B
job: 방어자
life:80
}
2222
{
name: B
job: 방어자
life: 80
}
2222
B:2222
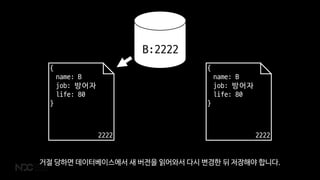
거절 당하면 데이터베이스에서 새 버전을 읽어와서 다시 변경한 뒤 저장해야 합니다.
57.
낙관적 동시성 제어
이런방식을 낙관적 동시성 제어라고 부릅니다. 아마 성공할 것이라고 낙관하고 일단 저장을 시도하는 거죠.
물론 실패할 수도 있지만 그건 나중에 생각합니다.
58.
낙관적 동시성 제어루프의 함정
• 경합이 잦은 곳에서는 급격하게 퍼포먼스가 나빠진다
• 루프 안에서는 사이드 이펙트가 없어야 한다
하지만 일단 저장하고 실패하면 다시 읽어와서 변경한 뒤 저장을 시도하는 방식은 단점이 있습니다.
경합이 잦은 곳에서의 문제도 문제지만, 데이터를 변경하는 곳이 참조 투명성을 갖춰야 한다는 점이죠.
59.
낙관적 동시성 제어루프의 함정
• 경합이 잦은 곳에서는 급격하게 퍼포먼스가 나빠진다
• 루프 안에서는 사이드 이펙트가 없어야 한다
1
2
3
4
def eat_medicine(self, item):
for doc in self.saving():
doc.life += item.life
broad_cast(‘I ate medicine’)
아마도 개발자는 물약을 먹었을 때 주변에 나 먹었다고 알리고 싶었을 뿐 입니다.
하지만 부주의하게 낙관적 동시성 제어 루프 안에 넣는 바람에 저장을 재시도할 때마다 날리게 되었죠
60.
낙관적 동시성 제어
이런특징 때문에 캐릭터 간 인터랙션 같은 복잡한 로직에서
낙관적 동시성 제어를 믿고 프로그래밍 하는 것은 매우 어려운 일입니다.
61.
서버 노드가 문서의소유권을 독점하기
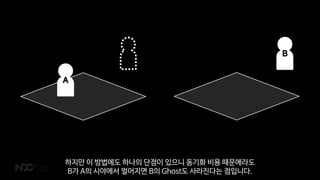
그래서 저희는 좀 다른 방식을 사용하고 있습니다.
어떤 문서의 소유권을 명확히 하는 방식이죠.
62.
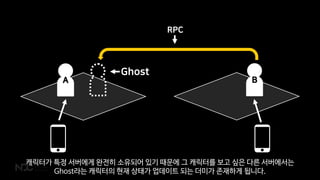
BA
Ghost
RPC
캐릭터가 특정 서버에게완전히 소유되어 있기 때문에 그 캐릭터를 보고 싶은 다른 서버에서는
Ghost라는 캐릭터의 현재 상태가 업데이트 되는 더미가 존재하게 됩니다.
63.
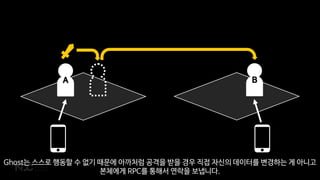
BA
Ghost는 스스로 행동할수 없기 때문에 아까처럼 공격을 받을 경우 직접 자신의 데이터를 변경하는 게 아니고
본체에게 RPC를 통해서 연락을 보냅니다.
1. 이동 명세문서 생성
{
name: 가방
items: []
}
{
name: 상자
items: [
가죽 장화
]
}
{
id: transfer_001
source: 상자
destination: 가방
state: pending
items: [
가죽 장화
]
}
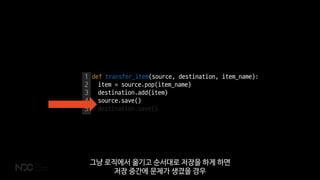
아이템을 옮기려고 하면 일단 아이템 이동 자체에 대한 명세 문서를 만들어 DB에 저장합니다.
출발지와 목적지, 아이템 그리고 이동에 대한 현재 상태도 넣어둬야겠죠.
86.
2. 상자와 명세문서를 연결하기
{
name: 가방
items: []
}
{
name: 상자
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: 상자
destination: 가방
state: pending
items: [
가죽 장화
]
}
그 다음엔 먼저 출발지에서 아이템을 빼고 명세 문서와의 연결 고리를 만듭니다.
혹시 실패한다면 이 명세를 참고해서 원래 상태로 복원할 수도 있고, 다시 이동을 이어서 진행할 수도 있습니다.
87.
3. 가방과 명세문서를 연결하기
{
name: 가방
items: []
transferring:
transfer_001
}
{
name: 상자
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: 상자
destination: 가방
state: pending
items: [
가죽 장화
]
}
도착지에도 이동을 반영합니다. 아이템 부터 넣으면 아직 프로세스가 끝나지 않았는데도
아이템을 사용해 버리는 일이 있을 수 있으니 명세 문서만 링크로 걸어 둡니다.
88.
4. 명세 상태변경
{
name: 가방
items: []
transferring:
transfer_001
}
{
name: 상자
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: 상자
destination: 가방
state: committed
items: [
가죽 장화
]
}
양쪽 인벤토리에 명세 문서가 다 링크 된 것을 확인하면 상태를 committed로 바꿉니다.
사실상 이동이 완료된 것이기 때문이죠.
89.
5. 아이템 이동완료
{
name: 가방
items: [
가죽 장화
]
}
{
name: 상자
items: []
}
{
id: transfer_001
source: 상자
destination: 가방
state: committed
items: [
가죽 장화
]
}
명세 문서에 committed가 기록되었으니 각 인벤토리는 이동 명세를 참고해서
결과를 스스로 반영할 수 있습니다.
90.
아이템 이동의 핵심
•하나의 단계에선 하나의 문서만 변경
• 아이템 이동에 대한 명세를 문서화 하여
어느 단계에서 멈춰도 다시 아이템 이동을 재개할 수 있음
각 단계에선 ACID 트랜잭션을 보장하는 하나의 문서에 대해서만 동작하기 때문에 아토믹함이 보장되고
명세 문서를 통해서 관리하기 때문에 언제 진행이 멈춰도 다시 진행할 수 있다는 점이 핵심입니다.
BA
S
E
아이템 이동이 진행되는중에도
상자와 가방은 정상 동작함
아이템 이동에 대한 상태가
확정되지 않은 순간이 존재함
순간적으로 아이템이 양쪽에서 사라진 것처럼
보일 수 있지만, 언젠가는 이동이 완료됨
BASE 트랜잭션은 ACID 트랜잭션을 지원하지 않을 때에 애플리케이션 레벨에서
ACID와 비슷한 동작을 위해서 만족해야 하는 특성들을 모아둔 것이라 하겠습니다.
1
2
3
4
5
{
estates: [
[3, 2]:김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
( )
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김서민 [1, 1]
F
하나의 문서를 F에 넣으면 오늘쪽 처럼 데이터가 나오겠네요.
108.
F
{
estates: [
[3, 2]:김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
map( , )
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김서민 [1, 1]
map을 여기서 사용하면 되겠어요.
여러 개의 데이터를 F와 함께 map에 넣으면 각기 데이터를 병렬 처리해서 작은 테이블들을 주겠네요.
109.
이름 위치
김부자 [3,2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김서민 [1, 1]
reduce(add, )
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김서민 [1, 1]
… …
이렇게 받은 여러 개의 테이블은 reduce를 이용해서 모으기만 하면 되겠네요.
(다양한 함수를 이용하면 이 단계에서 더 많은 가공을 할 수 있지만 지금의 예시는 단순히 합치는 데만 씁니다)
110.
이름 위치
김부자 [3,2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김평범 [1, 1]
… …
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김평범 [1, 1]
… …
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김평범 [1, 1]
… …
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김평범 [1, 1]
… …
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김서민 [1, 1]
… …
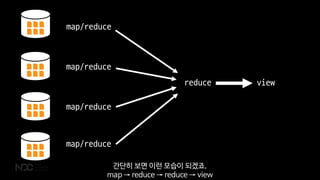
Couchbase는 분산 구조를 택하고 있기 때문에 각 데이터서비스에서 MapReduce를 통해 수집한 데이터를
한번 더 모으면 우리가 원하는 결과가 나옵니다.
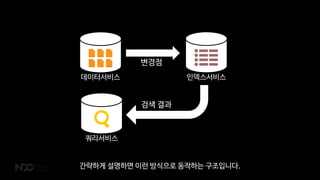
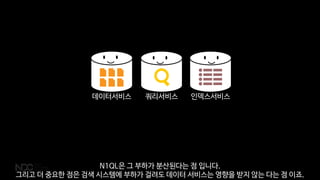
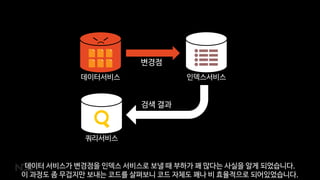
데이터서비스 인덱스서비스
쿼리서비스
변경점
검색 결과
데이터서비스가 변경점을 인덱스 서비스로 보낼 때 부하가 꽤 많다는 사실을 알게 되었습니다.
이 과정도 좀 무겁지만 보내는 코드를 살펴보니 코드 자체도 꽤나 비 효율적으로 되어있었습니다.
122.
데이터서비스
• 저장이 빈번할수록
• 저장한 문서 크기가 클 수록
• N1QL 인덱스가 많을 수록
다양한 실험과 연구를 통해서 이런 특징들을 알아내고
123.
데이터서비스
• 라이브에 필요없는 인덱스 분리
• 문서의 크기 줄이기
내부적인 튜닝을 거쳐서 어느 정도 감당이 가능한 정도로 부하를 줄일 수있었습니다.
124.
관성의 함정
• Couchbase는Key-Value Store
• Views, N1QL은 부가 기능
• RDB를 사용하던 느낌 그대로 로직을 디자인함
하지만 그와 별개로 저희는 쿼리 서비스에 의존하지 않아야 한다는 결론을 내리고
우리가 너무 RDB 스러운 DB 사용법에 익숙해져 있는 것은 아닌가에 대한 반성을 했습니다.
125.
{
estates: [
[3, 2]:김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
그래서 쿼리를 사용하지 않는 방식으로 재 구현하기로 결정하였습니다.
Grid와 별개로 사유지 하나 별로 땅문서를 만드는 방식이었습니다.
126.
{
estates: [
[3, 2]:김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
이전에도 땅문서에 주인이 링크되어 있는 것은 같았지만 새 시스템의 가장 중요한 차이점은
데이터의 근원이 땅이 아니라 땅문서라는 점 이었습니다.
127.
{
estates: [
[3, 2]:김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
예전엔 Grid에 이 땅의 주인이 누구인지 적혀있으면 그것을 믿었지만
이제는 땅문서를 확인해서 그 땅이 기록되어 있지 않다면
128.
{
estates: [
[3, 2]:김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
그 땅은 Grid를 믿지 않고 주인이 없는 땅으로 간주하는 것입니다.
129.
{
estates: [
[3, 2]:김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
이 방식은 Grid는 단순히 땅문서를 확인하기 위한 연결에 불과하기 때문에
모든 땅에서 이 땅의 주인을 확인하려면 지속적으로 땅문서를 읽어야 한다는 점이 부담이 됩니다.
130.
하지만 Couchbase는 자신의장점을 십분 발휘하여 Key-Value 읽기는 캐시급 성능으로
충분히 극복하였습니다. 저흰 DB의 최고 장점을 두고 불완전한 부가기능으로 열심히 씨름하고 있던 셈이었죠.
NoSQL
• RDB가 달성할수 없다고 생각되는 목표를 위해
잘 다져진 환경을 버리고 나온 것들
• 아직도 발전하고 있고 계속해서 바뀌고 있음
• 그래서 분명히 단단하지 못한 부분들이 존재함
• 단단하지 못한 부분을 애플리케이션에서
커버하고 있는 느낌을 받음
• 시간이 흐르면 RDB처럼 될까?
133.
게임 플레이 프로그래머로써
•RDB를 사용하던 시절에는 모든걸 DBA와 상담함
• 하지만 Couchbase를 사용하니 게임 플레이 로직과
데이터베이스가 적응하기 힘들 정도로 급격하게 가까워짐
• 데이터베이스를 깊게 이해 해야지만
게임 플레이 로직을 구현할 수 있었다.
134.
앞으로
• 여러가지의 데이터베이스를필요에 의해서
조합해서 사용하는 시대
• 앞으로도 NoSQL을 계속 사용해야 할 것 같은데
DBA와 게임 플레이 프로그래머의 중간 어디쯤 있는 역할이
새롭게 필요해진 것은 아닌가 하는 생각














![Couchbase
{
name: 김농부
job: 농부
level: 34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
{
name: 김군인
job: 군인
level: 27
items: [
{item:군번줄,
level:1}
]
}
{
name: 김학생
job: 학생
level: 29
items: []
}
반면 Couchbase는 JSON 기반의 document 데이터베이스이기 때문에
연관된 데이터를 묶어 하나의 문서에 같이 보관하는 경우가 많습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-15-320.jpg)
![Couchbase
{
name: 김농부
job: 농부
level: 34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
1
2
3
4
5
6
7
8
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
JSON으로 저장할 때의 가장 큰 특징은 로직의 데이터 구조와 유사하다는 점 입니다.
JSON이기 때문에 데이터베이스 사용자가 임의로 구조를 정할 수 있기 때문이죠.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-16-320.jpg)
![Couchbase
{
name: 김농부
job: 농부
level: 34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
1
2
3
4
5
6
7
8
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
때문에 RDB와 다르게 메모리 상의 데이터와 DB상의 데이터의 구조를 일치시킬 수 있어
게임 플레이 로직 개발이 굉장히 수월합니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-17-320.jpg)






![Couchbase
{
name: 김농부
job: 농부
level: 34
emotion: 분노
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
Couchbase에서도 하나의 문서를 변경할 땐 ACID 트랜잭션이라고 할 수 있습니다.
읽고, 쓰고, 저장하면 되니까요. 문서 단위로 동작하기 때문에 문서가 저장이 되다가 말거나 하는 일은 없습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-26-320.jpg)

![Couchbase
{
name: 김농부
job: 농부
level: 34
emotion: 분노
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-30-320.jpg)
![Couchbase
{
name: 김농부
job: 농부
level: 34
emotion: 분노
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
{
name: 김군인
job: 군인
level: 27
emotion: 분노
items: [
{item:군번줄,
level:1}
]
}
{
name: 김학생
job: 학생
level: 29
items: []
}
때문에 여러 개의 문서를 저장하다 보면 몇 개는 실패할 수도 있죠.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-31-320.jpg)
![Couchbase
{
name: 김농부
job: 농부
level: 34
emotion: 분노
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
JSON 수억개
더군다나 문서가 수억개 쯤 된다면 실패한 것들을 재시도해서 저장하는 것도 쉽지 않은 일이 됩니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-32-320.jpg)

![on-demand migration
{
version: 0
name: 김농부
job: 농부
level: 34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
1
2
3
4
5
6
7
8
9
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
__version__ = 0
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
on-demand migratio은 문서의 데이터와 메모리 상의 데이터가 동일하다는 부분에서 출발합니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-34-320.jpg)
![on-demand migration
{
version: 0
name: 김농부
job: 농부
level: 34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
1
2
3
4
5
6
7
8
9
class Item:
item = declare(unicode)
level = declare(int)
class Entity:
__version__ = 0
job = declare(unicode)
level = declare(int)
items = declare(list(Item))
저장된 데이터와 애플리케이션에서 선언한 스키마에 버전을 부여하고
둘이 같아지도록 애플리케이션에서 관리하는 겁니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-35-320.jpg)

![on-demand migration
1
2
3
4
5
6
7
8
9
10
@migrate(Entity, 0, 1)
def migration(document):
document[‘emotion’] = ‘분노’
def load(cls, key):
doc = db.load(key)
if doc[‘version’] != cls.version:
doc = migrate(doc[‘version’], cls.version, doc)
db.update(key, doc)
return unpack(doc)
버전이 0에서 1로 올라갈 때 문서의 마이그레이션을 어떻게 할지 함수로 만들어 둡니다.
그리고 문서를 애플리케이션에서 읽을 때 저장된 버전이 현재와 다르면 해당 함수를 실행시킵니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-37-320.jpg)
![on-demand migration
{
version: 0
name: 김농부
job: 농부
level: 34
items: [
{item:곡괭이,
level:20},
{item:밀짚모자,
level:15}
]
}
{
version: 1
name: 김군인
job: 군인
level: 27
emotion: 분노
items: [
{item:군번줄,
level:1}
]
}
{
version: 1
name: 김학생
job: 학생
level: 29
emotion: 분노
items: []
}
이렇게 되면 다른 버전의 데이터가 공존할 수 있지만, 어차피 읽어서 쓸 때는 버전이 맞춰지니 괜찮습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-38-320.jpg)















![{
name: B
job: 방랑자
exp: 50
}
{
promises: [
(add_exp, 30)
(add_exp, 20)
(add_exp, 40)
]
}
하나의 캐릭터에게는 언제나 하나의 promise 큐를 만들어 두고
시야에 없는 캐릭터에게는 약속만 걸어두면](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-72-320.jpg)
![{
name: B
job: 방랑자
exp: 140
}
{
promises: []
}
해당 캐릭터가 접속했을 때 알아서 해당 큐의 작업들을 수행하는 방식이죠.
이미 접속 중이었다면 바로 실행할 것 입니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-73-320.jpg)



![{
name: 가방
items: []
}
{
name: 상자
items: [
가죽 장화
]
}
하지만 두개의 문서를 동시에 저장할 일은 필요하기 마련입니다.
상자에서 가방으로 아이템을 옮기는 것이 대표적인 예이죠.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-77-320.jpg)
![{
name: 가방
items: [
가죽 장화
]
}
{
name: 상자
items: []
}
이렇게 뿅 하고 옮겨지면 좋겠지만, Couchbase에서는 이 과정이 쉽지 않습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-78-320.jpg)
![{
name: 가방
items: []
}
{
name: 상자
items: []
}
아이템이 소실되는 문제가 생깁니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-80-320.jpg)
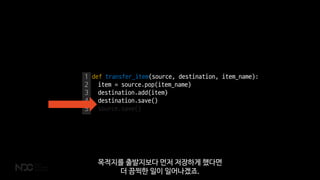
![{
name: 가방
items: [
가죽 장화
]
}
{
name: 상자
items: [
가죽 장화
]
}
아이템 복사가 일어나죠.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-82-320.jpg)

![{
name: 가방
items: []
}
{
name: 상자
items: [
가죽 장화
]
}
BASE 트랜잭션의 용어를 일일히 먼저 이해하는 것 보다 예시를 보고 용어를 다시 보면
이해가 쉬울 것 같습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-84-320.jpg)
![1. 이동 명세 문서 생성
{
name: 가방
items: []
}
{
name: 상자
items: [
가죽 장화
]
}
{
id: transfer_001
source: 상자
destination: 가방
state: pending
items: [
가죽 장화
]
}
아이템을 옮기려고 하면 일단 아이템 이동 자체에 대한 명세 문서를 만들어 DB에 저장합니다.
출발지와 목적지, 아이템 그리고 이동에 대한 현재 상태도 넣어둬야겠죠.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-85-320.jpg)
![2. 상자와 명세 문서를 연결하기
{
name: 가방
items: []
}
{
name: 상자
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: 상자
destination: 가방
state: pending
items: [
가죽 장화
]
}
그 다음엔 먼저 출발지에서 아이템을 빼고 명세 문서와의 연결 고리를 만듭니다.
혹시 실패한다면 이 명세를 참고해서 원래 상태로 복원할 수도 있고, 다시 이동을 이어서 진행할 수도 있습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-86-320.jpg)
![3. 가방과 명세 문서를 연결하기
{
name: 가방
items: []
transferring:
transfer_001
}
{
name: 상자
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: 상자
destination: 가방
state: pending
items: [
가죽 장화
]
}
도착지에도 이동을 반영합니다. 아이템 부터 넣으면 아직 프로세스가 끝나지 않았는데도
아이템을 사용해 버리는 일이 있을 수 있으니 명세 문서만 링크로 걸어 둡니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-87-320.jpg)
![4. 명세 상태 변경
{
name: 가방
items: []
transferring:
transfer_001
}
{
name: 상자
items: []
transferring:
transfer_001
}
{
id: transfer_001
source: 상자
destination: 가방
state: committed
items: [
가죽 장화
]
}
양쪽 인벤토리에 명세 문서가 다 링크 된 것을 확인하면 상태를 committed로 바꿉니다.
사실상 이동이 완료된 것이기 때문이죠.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-88-320.jpg)
![5. 아이템 이동 완료
{
name: 가방
items: [
가죽 장화
]
}
{
name: 상자
items: []
}
{
id: transfer_001
source: 상자
destination: 가방
state: committed
items: [
가죽 장화
]
}
명세 문서에 committed가 기록되었으니 각 인벤토리는 이동 명세를 참고해서
결과를 스스로 반영할 수 있습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-89-320.jpg)






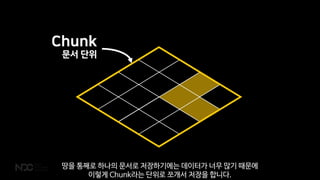

![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
Grid 문서를 살펴보면 대충 이와 같은 모습을 하고 있습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-98-320.jpg)
![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
이런 것이 여러 개 모여 하나의 땅 즉 Grid를 이루죠.
더 크게 보면 섬 여러 개로 이루어진 듀랑고는 결국 이 Chunk 단위 문서들의 모음이라고 하겠습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-99-320.jpg)

![MapReduce
map(f, [i1, i2, i3, ...]) = [f(i1), f(i2), f(i3) ...]
reduce(g, [i1, i2, i3, ...]) = g(i1, g(i2, g(i3, ...)))
map과 reduce는 여러분이 아시는 그것이 맞습니다.
이걸 어떻게 활용한다는 것일까요?](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-103-320.jpg)
![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김서민 [1, 1]
… …
우리는 이런 여러 개의 문서로부터 오른쪽 같은 테이블을 얻기를 원하죠](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-104-320.jpg)
![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
우선 하나의 문서만 대상으로 놓고 해볼까요?](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-105-320.jpg)
![1
2
3
4
5
6
function(doc)
for (var cell in doc[‘estates’]) {
var owner = doc[‘estates’][cell]
emit(owner, cell)
}
}
이런 함수면 충분할 것 같네요! 편의상 요 함수를 F라고 표기하겠습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-106-320.jpg)
![1
2
3
4
5
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
( )
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김서민 [1, 1]
F
하나의 문서를 F에 넣으면 오늘쪽 처럼 데이터가 나오겠네요.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-107-320.jpg)
![F
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
[1, 1]: 김서민
]
}
map( , )
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김서민 [1, 1]
map을 여기서 사용하면 되겠어요.
여러 개의 데이터를 F와 함께 map에 넣으면 각기 데이터를 병렬 처리해서 작은 테이블들을 주겠네요.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-108-320.jpg)
![이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김평범 [1, 1]
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김서민 [1, 1]
reduce(add, )
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김서민 [1, 1]
… …
이렇게 받은 여러 개의 테이블은 reduce를 이용해서 모으기만 하면 되겠네요.
(다양한 함수를 이용하면 이 단계에서 더 많은 가공을 할 수 있지만 지금의 예시는 단순히 합치는 데만 씁니다)](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-109-320.jpg)
![이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김평범 [1, 1]
… …
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김평범 [1, 1]
… …
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김평범 [1, 1]
… …
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김평범 [1, 1]
… …
이름 위치
김부자 [3, 2]
김부자 [2, 1]
김부자 [2, 2]
김부자 [3, 3]
김부자 [1, 2]
김서민 [1, 1]
… …
Couchbase는 분산 구조를 택하고 있기 때문에 각 데이터서비스에서 MapReduce를 통해 수집한 데이터를
한번 더 모으면 우리가 원하는 결과가 나옵니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-110-320.jpg)










![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
그래서 쿼리를 사용하지 않는 방식으로 재 구현하기로 결정하였습니다.
Grid와 별개로 사유지 하나 별로 땅문서를 만드는 방식이었습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-125-320.jpg)
![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
이전에도 땅문서에 주인이 링크되어 있는 것은 같았지만 새 시스템의 가장 중요한 차이점은
데이터의 근원이 땅이 아니라 땅문서라는 점 이었습니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-126-320.jpg)
![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
예전엔 Grid에 이 땅의 주인이 누구인지 적혀있으면 그것을 믿었지만
이제는 땅문서를 확인해서 그 땅이 기록되어 있지 않다면](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-127-320.jpg)
![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
그 땅은 Grid를 믿지 않고 주인이 없는 땅으로 간주하는 것입니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-128-320.jpg)
![{
estates: [
[3, 2]: 김부자
[2, 1]: 김부자
[2, 2]: 김부자
]
}
이 방식은 Grid는 단순히 땅문서를 확인하기 위한 연결에 불과하기 때문에
모든 땅에서 이 땅의 주인을 확인하려면 지속적으로 땅문서를 읽어야 한다는 점이 부담이 됩니다.](https://image.slidesharecdn.com/2018ndcv3-180428061110/85/NoSQL-MMORPG-129-320.jpg)







![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[야생의 땅: 듀랑고] 서버 아키텍처 Vol. 2 (자막)](https://cdn.slidesharecdn.com/ss_thumbnails/vol2-160427160825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC2016] TERA 서버의 Modern C++ 활용기](https://cdn.slidesharecdn.com/ss_thumbnails/v09teramodernc20160425-160427044156-thumbnail.jpg?width=640&height=640&fit=bounds)












![[NDC2017 : 박준철] Python 게임 서버 안녕하십니까 - 몬스터 슈퍼리그 게임 서버](https://cdn.slidesharecdn.com/ss_thumbnails/ndc17python-0425v08-170426123108-thumbnail.jpg?width=640&height=640&fit=bounds)






![오딘: 발할라 라이징 MMORPG의 성능 최적화 사례 공유 [카카오게임즈 - 레벨 300] - 발표자: 김문권, 팀장, 라이온하트 스튜디오...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s1-221108101729-c6b32f4f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2D7]레기온즈로 살펴보는 확장 가능한 게임서버의 구현](https://cdn.slidesharecdn.com/ss_thumbnails/2d7-140930023650-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[110730/아꿈사발표자료] mongo db 완벽 가이드 : 7장 '고급기능'](https://cdn.slidesharecdn.com/ss_thumbnails/110730mongodb7-110729214130-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![[스마트스터디]모바일 애플리케이션 서비스에서의 로그 수집과 분석](https://cdn.slidesharecdn.com/ss_thumbnails/redismongodbmysql-171107063045-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)




