
























![| © Copyright 2015 Hitachi Consulting47
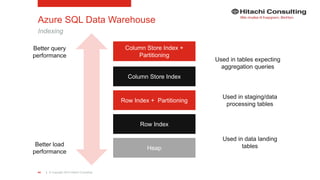
Azure SQL Data Warehouse
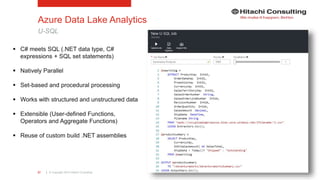
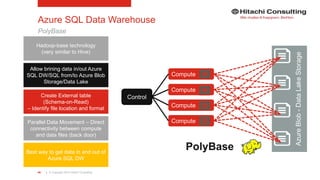
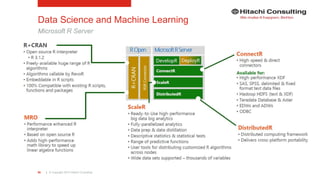
PolyBase
CREATE EXTERNAL DATA SOURCE MyAzureDataSource
WITH
(TYPE = HADOOP
,LOCATION =
'wasbs://[container]@accountname.blob.core.windows.net/path'
);
CREATE EXTERNAL FILE FORMAT MyTextFileFormat
WITH
( FORMAT_TYPE = DELIMITEDTEXT
,FORMAT_OPTIONS
(
FIELD_TERMINATOR = '|',
STRING_DELIMITER = ',',
DATE_FORMAT= 'yyyy-MM-dd',
USE_TYPE_DEFAULT= TRUE
)
,DATA_COMPRESSION =
| 'org.apache.hadoop.io.compress.GzipCodec'
);
CREATE EXTERNAL TABLE [asb].[FactOnlineSales]
([ProductKey] int NOT NULL
,[StoreKey] int NOT NULL
,[DateKey] int NOT NULL
,[CustomerKey] int NOT NULL
,[PromotionKey] int NOT NULL
,[SalesQuantity] int NOT NULL
,[UnitPrice] money NOT NULL
,[SalesAmount] money NOT NULL
)
WITH
(LOCATION='wasbs://filepath_or_directory'
,DATA_SOURCE = MyAzureDataSource
,FILE_FORMAT = MyTextFileFormat
,REJECT_TYPE = VALUE
,REJECT_VALUE = 0
,REJECT_SAMPLE_VALUE = 1000
);](https://image.slidesharecdn.com/ks06-dataplatformsonmsazure-160722151604/85/Enterprise-Cloud-Data-Platforms-with-Microsoft-Azure-47-320.jpg)







![| © Copyright 2015 Hitachi Consulting60
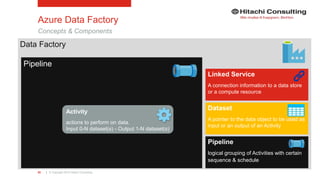
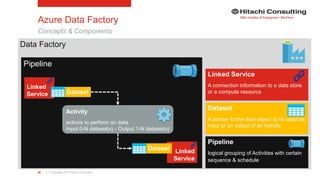
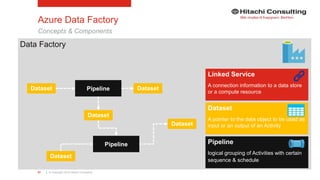
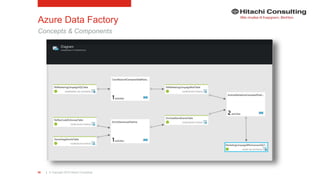
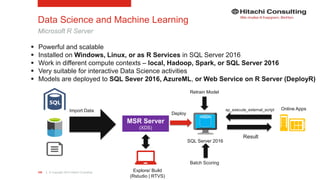
Azure Data Factory
Example {
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService1",
"typeProperties": {
"fileName": "input.log",
"folderPath": "adfgetstarted/inputdata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
},
"external": true, "policy": {}
}
}
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService1",
"typeProperties": {
"folderPath": "adfgetstarted/partitioneddata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
}
}
}
{
"name": "MyFirstPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService1",
"defines": {
"inputtable": <storageaccounturl>",
"partitionedtable": ,<folderurl>"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Month",
"interval": 1
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
],
"start": "2016-04-01T00:00:00Z",
"end": "2016-04-02T00:00:00Z",
"isPaused": false
}
}
{
"name": "HDInsightOnDemandLinkedService",
"properties": {
"type": "HDInsightOnDemand",
"typeProperties": {
"version": "3.2",
"clusterSize": 1,
"timeToLive": "00:30:00",
"linkedServiceName": "AzureStorageLinkedService1"
}
}
}
Input Dataset
Linked Service
Output Dataset
Pipeline](https://image.slidesharecdn.com/ks06-dataplatformsonmsazure-160722151604/85/Enterprise-Cloud-Data-Platforms-with-Microsoft-Azure-60-320.jpg)




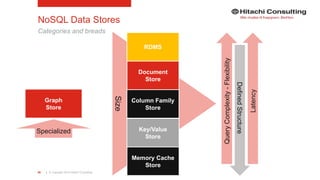
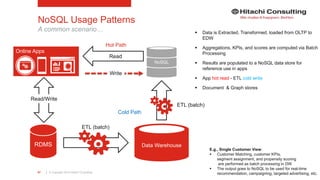

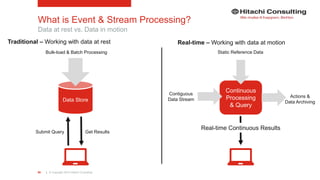
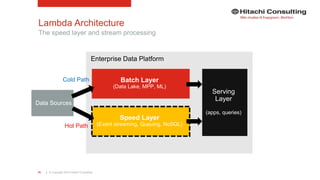

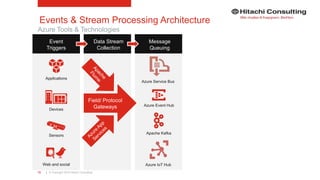
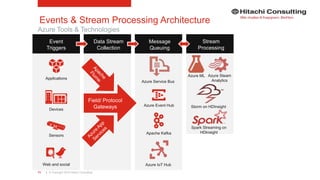
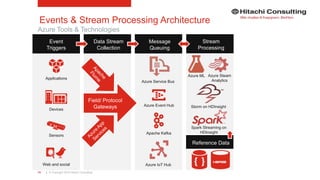
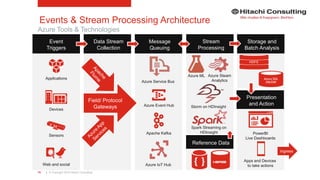

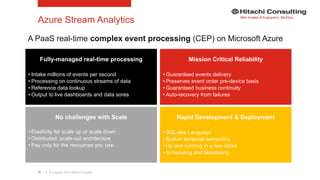
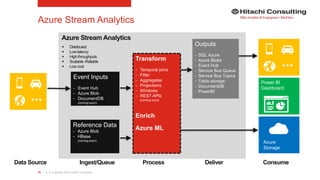
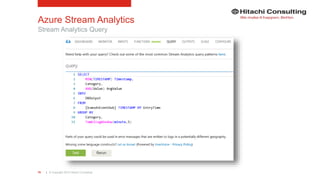



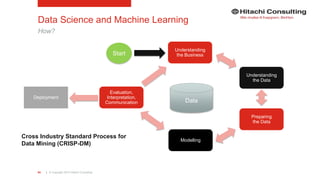
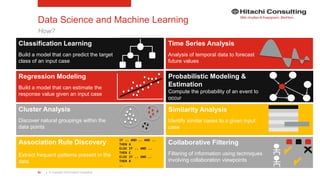

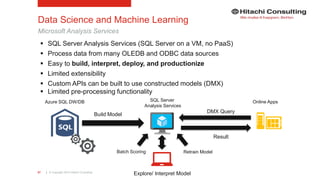
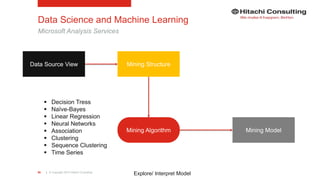


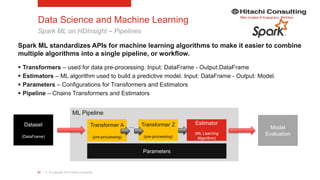

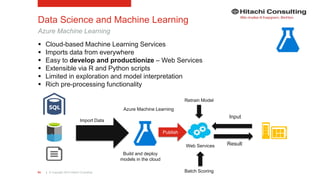
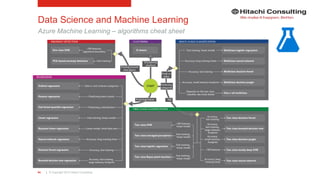













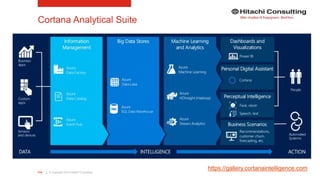



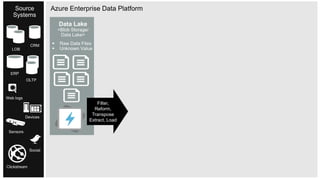
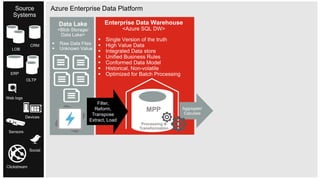
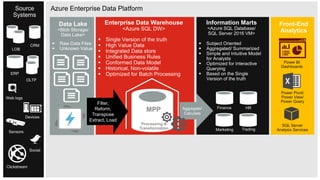
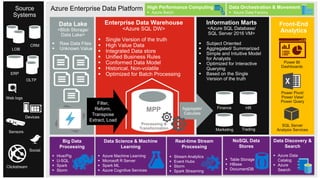
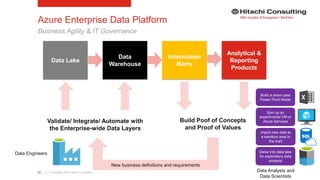
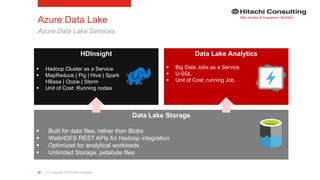
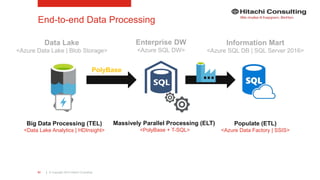
The document discusses the integration of enterprise data platforms using Microsoft Azure and the Cortana Analytical Suite, focusing on topics such as cloud computing, data storage, big data processing, and data management services. It highlights the architecture of Azure, including the data lake and data warehouse, as well as the importance of data orchestration through Azure Data Factory. The document emphasizes the benefits of agility, scalability, and cost-effectiveness in utilizing Azure's cloud services for data analytics and management.































![[JSS2015] Azure SQL Data Warehouse - Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sqldwh-adl-151211085004-thumbnail.jpg?width=640&height=640&fit=bounds)










































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)












![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)