Downloaded 56 times



































![Italian Virtual Chapter – 19.10.2016
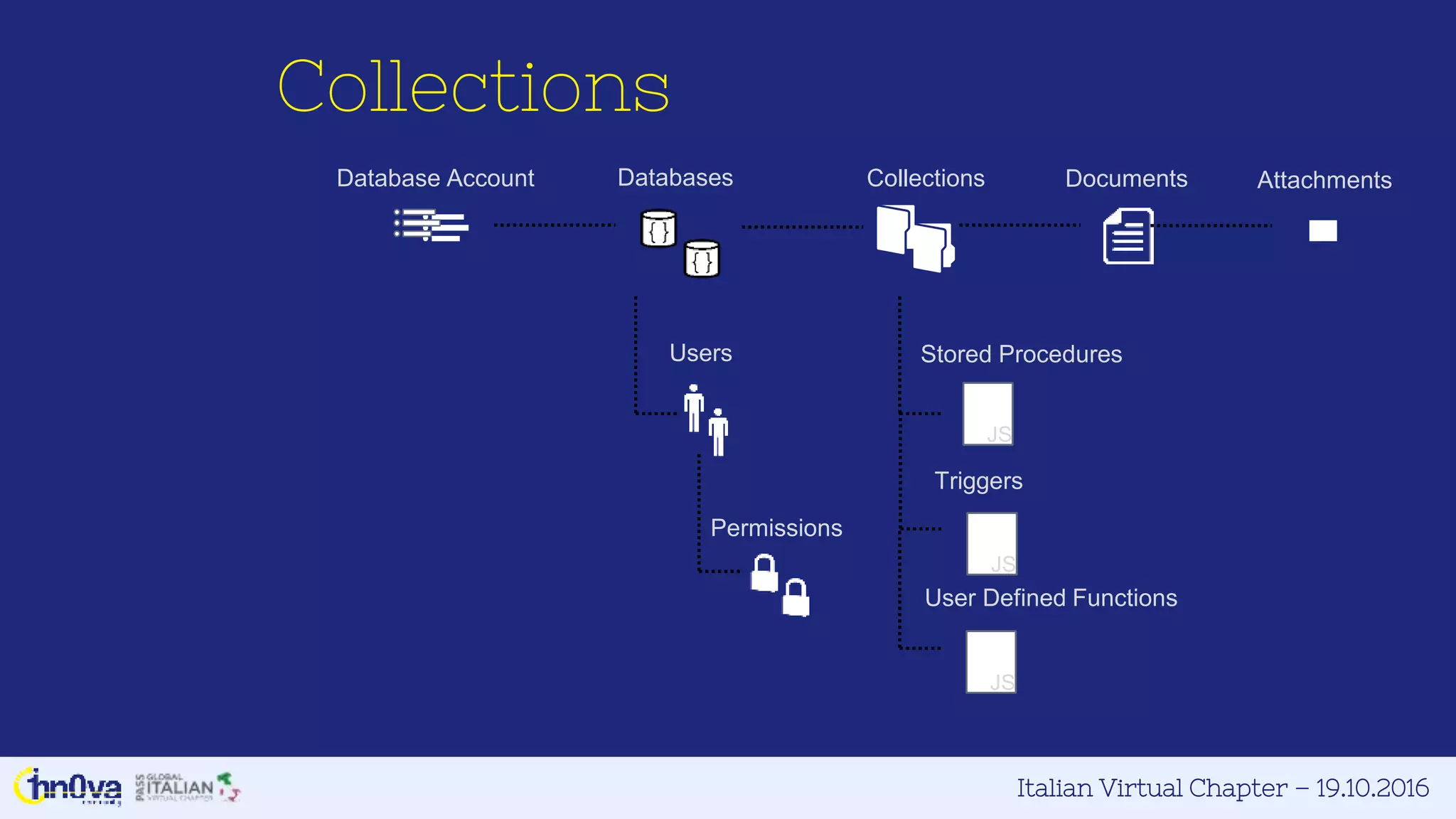
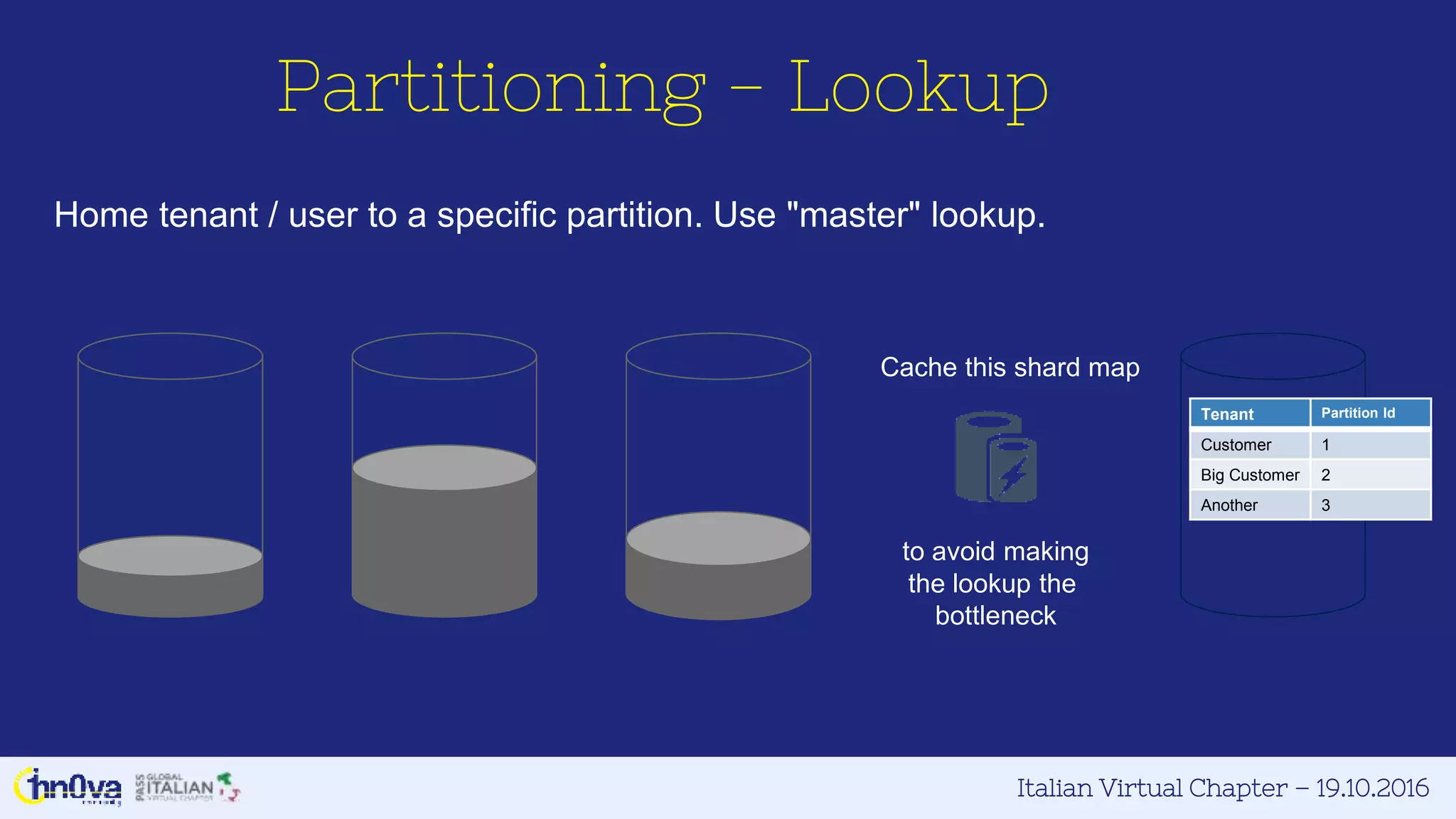
Index policies
◇customize index management
including storage
◇overhead, throughput and query
consistency
■range, hash and spatial indexes
■included and excluded paths
■indexing mode; consistent or lazy
■index precision
■online, in-place index transformations
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*",
"indexes": [
{
"kind": "Range",
"dataType": "Number",
"precision": -1
},
{
"kind": "Hash",
"dataType": "String",
"precision": 3
},
{
"kind": "Spatial",
"dataType": "Point"
}
]
}
],
"excludedPaths": []
}](https://image.slidesharecdn.com/2016-161020083819/75/Azure-DocumentDb-41-2048.jpg)




![Italian Virtual Chapter – 19.10.2016
Query
◇Query over heterogeneous documents
without defining schema or managing indexes
◇Query arbitrary paths, properties and values
without specifying secondary indexes or
indexing hints
◇Execute queries with consistent results
◇Supported SQL features; predicates,
iterations (arrays), sub-queries, logical
operators, UDFs, intra-document JOINs, JSON
transforms
◇In general, more predicates result in a larger
request charge.
◇Additional predicates can help if they result
in narrowing the overall result set.
from book in client.CreateDocumentQuery<Book>(collectionSelfLink)
where book.Title == "War and Peace"
select book;
from book in client.CreateDocumentQuery<Book>(collectionSelfLink)
where book.Author.Name == "Leo Tolstoy"
select book.Author;
-- Nested lookup against index
SELECT B.Author
FROM Books B
WHERE B.Author.Name = "Leo Tolstoy"
-- Transformation, Filters, Array access
SELECT { Name: B.Title, Author: B.Author.Name }
FROM Books B
WHERE B.Price > 10 AND B.Language[0] = "English"
-- Joins, User Defined Functions (UDF)
SELECT udf.CalculateRegionalTax(B.Price, "USA", "WA")
FROM Books B
JOIN L IN B.Languages
WHERE L.Language = "Russian"
LINQ Query
SQL Query Grammar](https://image.slidesharecdn.com/2016-161020083819/75/Azure-DocumentDb-46-2048.jpg)










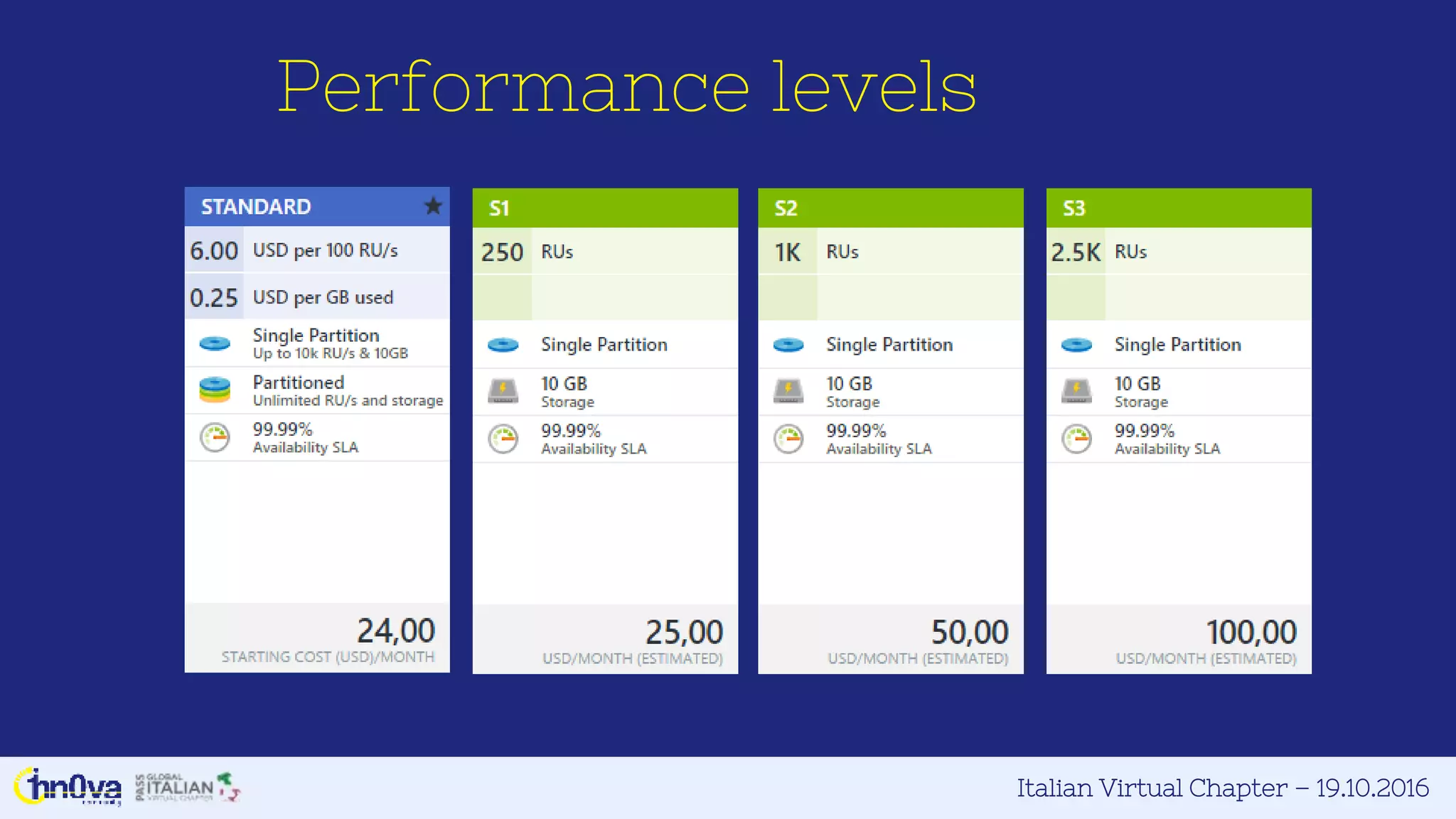
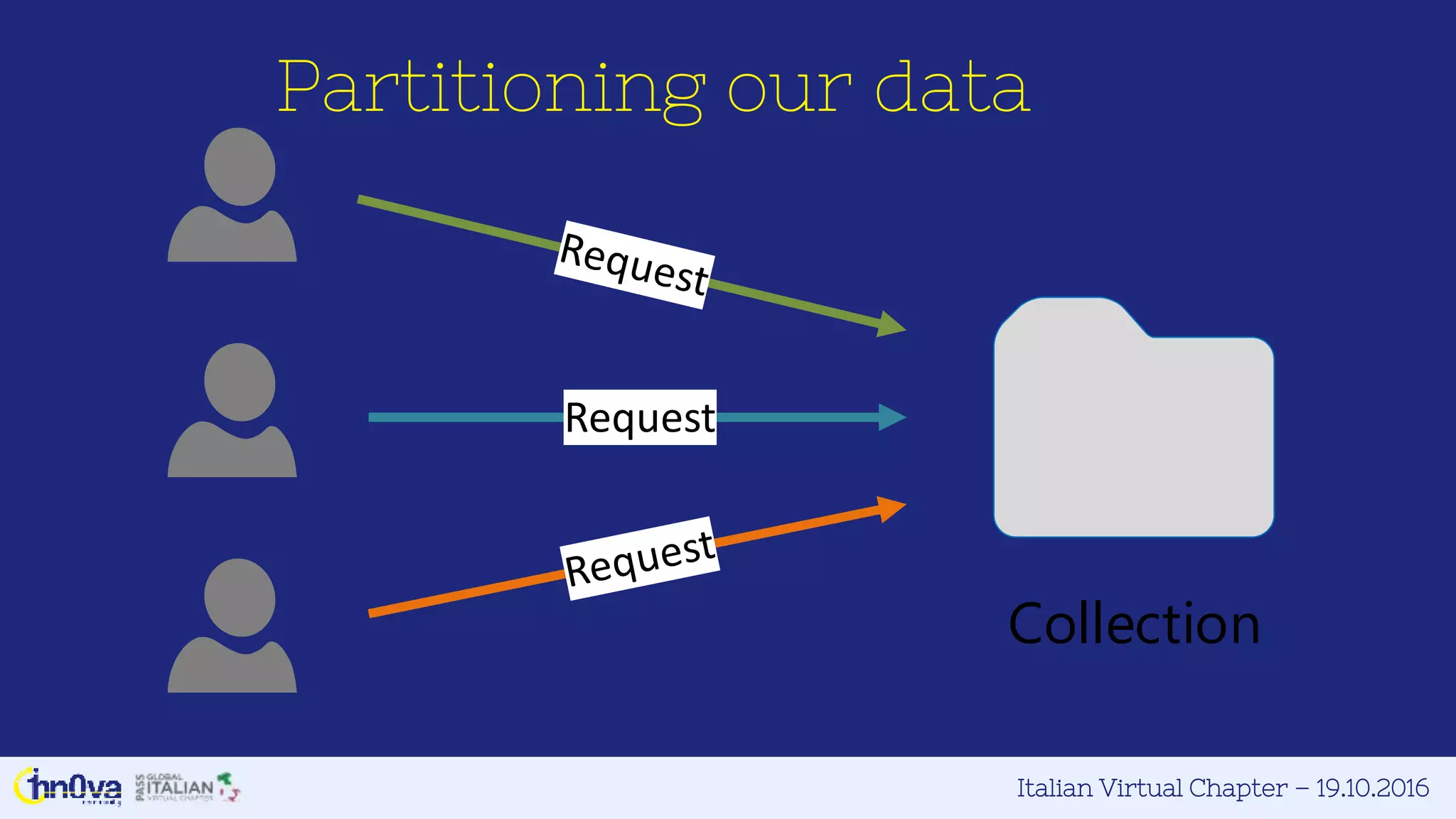
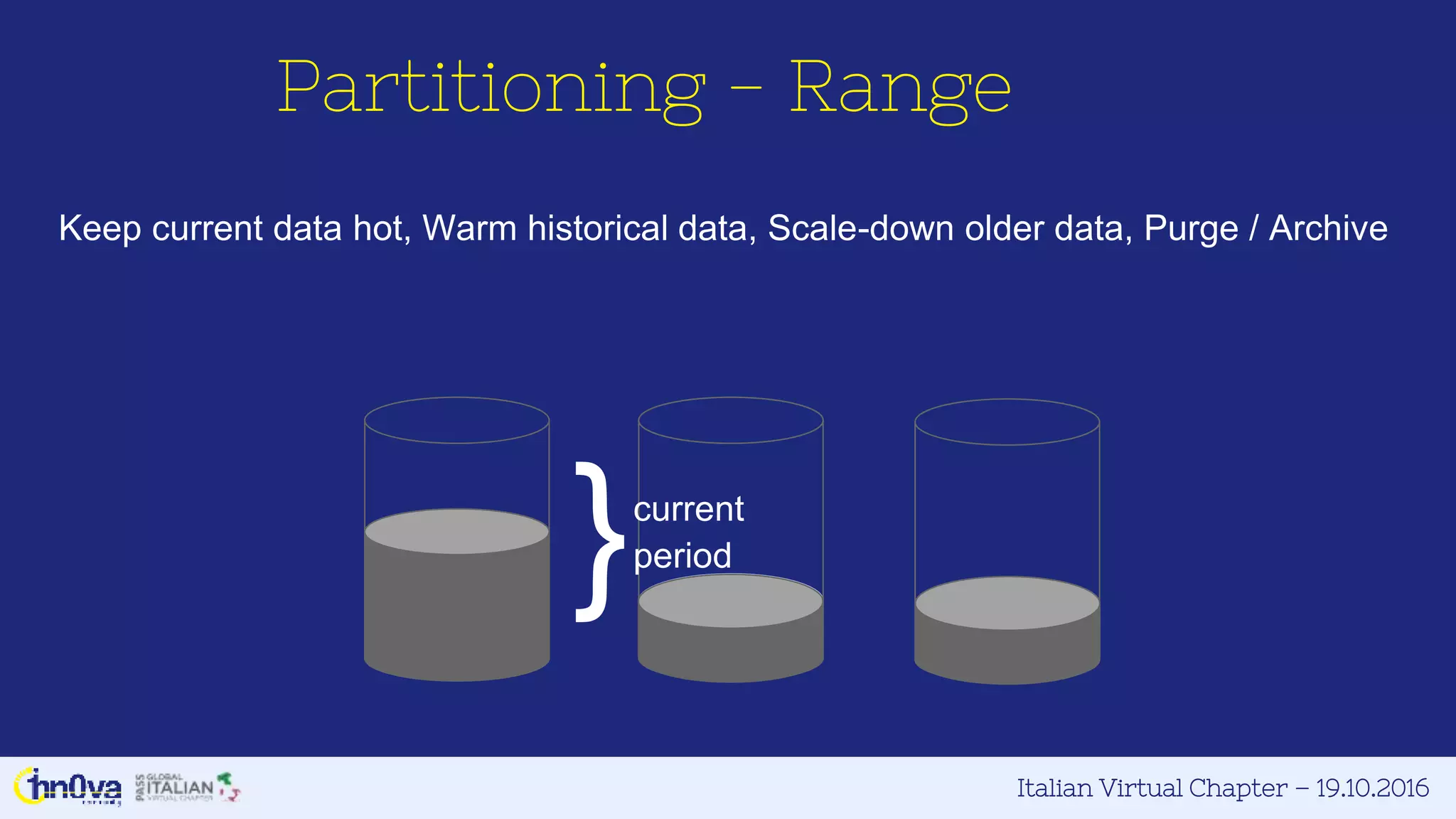
This document provides an overview of Azure DocumentDB presented by Marco Parenzan. Key points include: - DocumentDB is a fully managed NoSQL database that is schema-agnostic and scalable. - It allows for tunable consistency levels and indexing policies. Queries use a familiar SQL syntax. - Documents are stored in JSON format across collections within databases. - DocumentDB has appeal for developers as documents map directly to JSON and objects, requiring no ORM. - The document discusses strategies like using view models and data normalization versus embedding versus referencing. - It also covers the resource model, performance, partitioning, indexing, querying, and programmability features of DocumentDB































![[PASS Summit 2016] Azure DocumentDB: A Deep Dive into Advanced Features](https://cdn.slidesharecdn.com/ss_thumbnails/passdocdbadvfeatures-161029023827-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PASS Summit 2016] Blazing Fast, Planet-Scale Customer Scenarios with Azure D...](https://cdn.slidesharecdn.com/ss_thumbnails/passdocdbscenarios-161027221948-thumbnail.jpg?width=640&height=640&fit=bounds)










































































