Download as PDF, PPTX



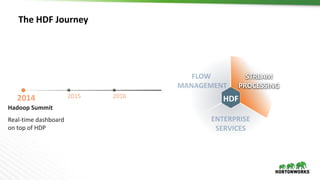
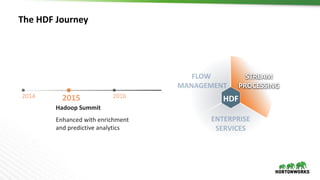
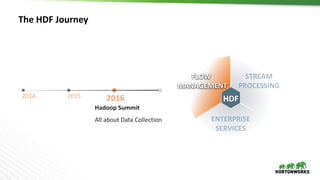
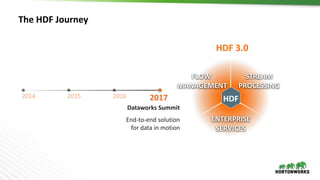

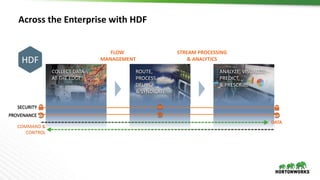



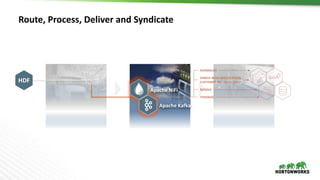
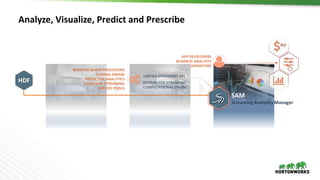

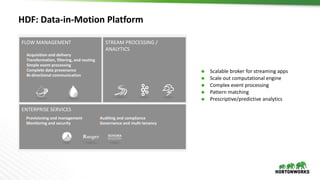



The document discusses Hortonworks DataFlow (HDF), which is a platform for data in motion. HDF allows users to collect data at the edge, route and process streaming data with Apache NiFi and Kafka, and analyze, visualize, predict and prescribe outcomes from the data using HDF platform services. The HDF platform provides scalable stream processing, security, data provenance, and management capabilities for data in motion applications across the enterprise.































































![[Hortonworks] Future Of Data: Madrid - HDF & Data in motion](https://cdn.slidesharecdn.com/ss_thumbnails/fodmadrid-introtohdf-171123091047-thumbnail.jpg?width=640&height=640&fit=bounds)








































