Download to read offline





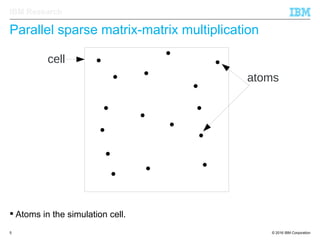
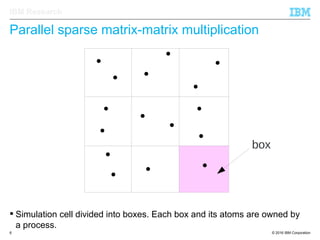
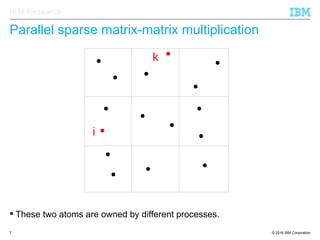

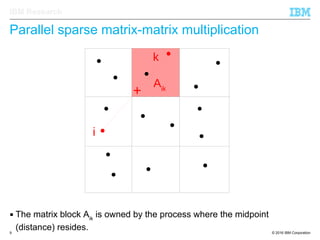
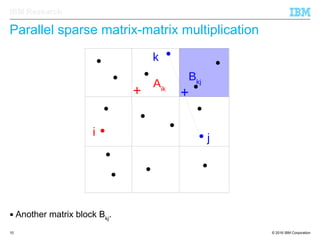
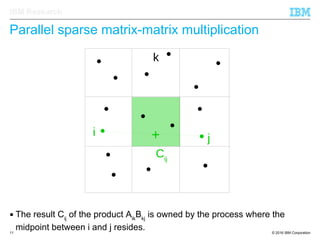
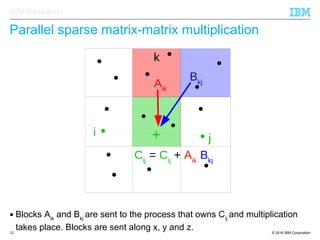

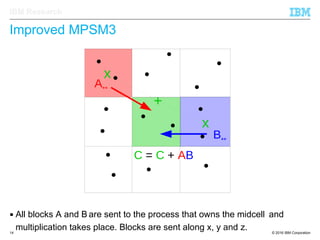
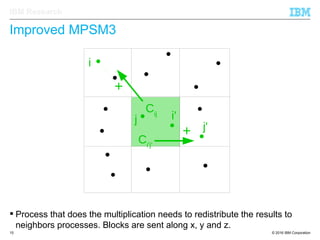
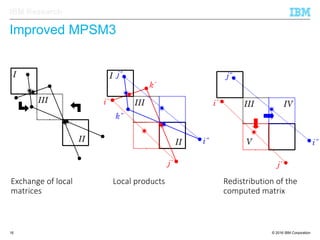
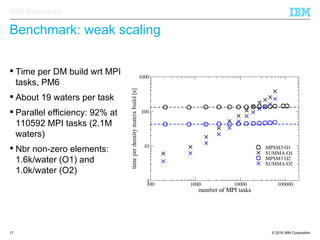
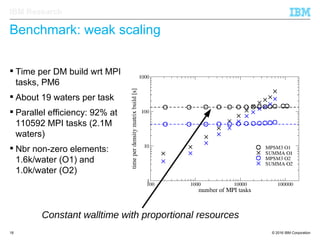
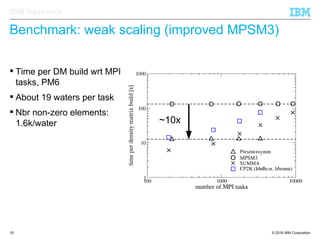
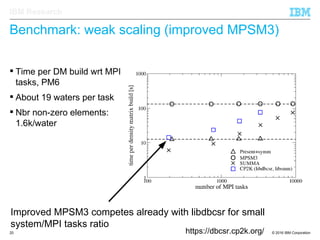
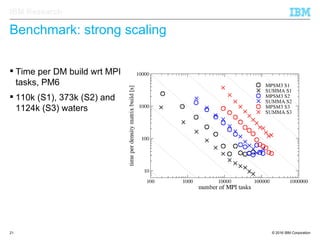
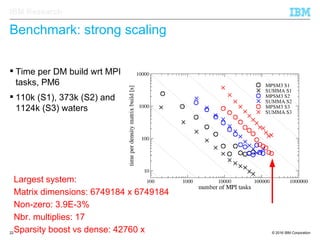
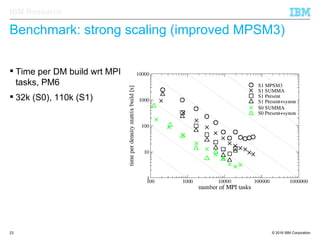
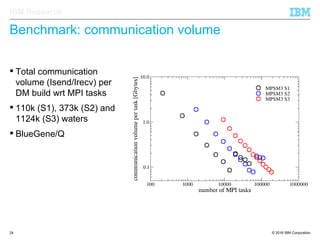

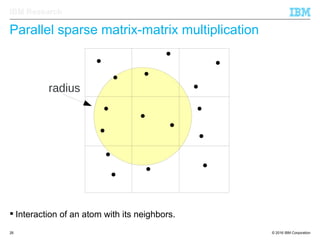


The document discusses the development of enhanced methods for parallel sparse matrix-matrix multiplication (MPSM3) aimed at applying quantum Hamiltonians to biological systems with over 30,000 atoms. It highlights significant advancements in weak and strong scaling efficiencies and reduced communication volumes during computations. The improved MPSM3 algorithm shows promise in facilitating molecular dynamics simulations more efficiently, allowing timely molecular dynamics steps regardless of system size.




































































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)



