Download as PDF, PPTX


![Matrix graph duality
Graph algorithms in the language of linear algebra
∙ Adjacency matrix A is dual with the corresponding graph
∙ Vector matrix multiply is dual with breadth-first search
Image credit: [Kepner2011]
2 c○ 2016 IBM Corporation](https://image.slidesharecdn.com/smmm-graphhpc-2016-160303132710/85/Midpoint-Based-Parallel-Sparse-Matrix-Matrix-Multiplication-Algorithm-2-320.jpg)
![Sparse matrix-matrix multiplication motivation
Electronic structure theory
∙ Density matrix 𝐷 at zero
electronic temperature:
𝐷 = 𝜃[𝜇𝐼 − 𝐹]
𝜃(𝑥) — Heaviside step
function
𝜇 — chemical potential
𝐼 — identity matrix
𝐹 — Fockian
∙ Second-order spectral projection (SP2)
method
𝐷 = lim
𝑖→∞
𝑓𝑖[𝑓𝑖−1[. . . 𝑓0[𝑋0]]]
∙ Recursive polynomial
𝑓𝑖[𝑋𝑖] =
{︃
𝑋2
𝑖 Tr[𝑋𝑖] > 𝑁 𝑠
2𝑋𝑖 − 𝑋2
𝑖 otherwise
𝑁 𝑠 — number of occupied states
3 c○ 2016 IBM Corporation](https://image.slidesharecdn.com/smmm-graphhpc-2016-160303132710/85/Midpoint-Based-Parallel-Sparse-Matrix-Matrix-Multiplication-Algorithm-3-320.jpg)
![Scalability issues of the Cannon’s and SUMMA algorithms
∙ Weak scaling experiment
∙ ≈ 200 atoms per MPI task
∙ From 32 928 atoms on 144 cores
∙ To 1 022 208 atoms on 5184 cores
∙ Image legend:
Total CPU time per atom
Block matrix multiplications
Book-keeping overhead
Communication between processes
Dashed line: fit to the data using
𝑓(𝑁) = 𝑎 + 𝑏
√
𝑁
Image credit: [VandeVondele2012]
4 c○ 2016 IBM Corporation](https://image.slidesharecdn.com/smmm-graphhpc-2016-160303132710/85/Midpoint-Based-Parallel-Sparse-Matrix-Matrix-Multiplication-Algorithm-4-320.jpg)
![Midpoint method
∙ Particle interactions in molecular
dynamics [Bowers2006]
∙ The computational domain is
divided between processors
∙ Interaction between a pair — a
processor that holds a midpoint
Image credit: [Bowers2006]
5 c○ 2016 IBM Corporation](https://image.slidesharecdn.com/smmm-graphhpc-2016-160303132710/85/Midpoint-Based-Parallel-Sparse-Matrix-Matrix-Multiplication-Algorithm-5-320.jpg)
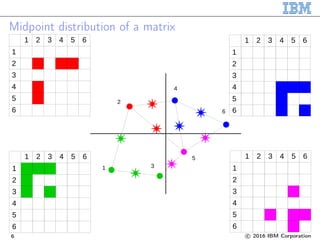
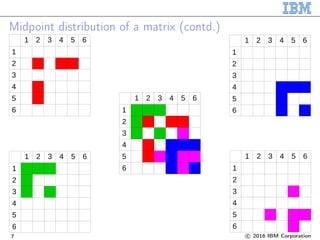
![Sparse matrix-matrix multiplication
∙ Exploit the locality
∙ 3D Cartesian topology
∙ Each matrix element lies at the
process that owns a midpoint:
midpoint(𝑖, 𝑘) ⇒ element 𝐴𝑖𝑘
midpoint(𝑘, 𝑗) ⇒ element 𝐵 𝑘𝑗
midpoint(𝑖, 𝑗) ⇒ element 𝐶𝑖𝑗
∙ Send 𝐴𝑖𝑘 and 𝐵 𝑘𝑗
∙ 𝐶𝑖𝑗 ← 𝐴𝑖𝑘 · 𝐵 𝑘𝑗 + 𝐶𝑖𝑗
i
j
k
Bkj
(-1,0) (0,0)
(0,-1)
Cij
Aik
Image credit: [Weber2015]
8 c○ 2016 IBM Corporation](https://image.slidesharecdn.com/smmm-graphhpc-2016-160303132710/85/Midpoint-Based-Parallel-Sparse-Matrix-Matrix-Multiplication-Algorithm-8-320.jpg)

![Weak scaling experiments
∙ Two occupations of the
density matrix (O1, O2)
∙ ≈ 19 water molecules
per MPI task
∙ 216 ÷ 59 319 MPI tasks
∙ MPSM3 vs. SUMMA
crossover point:
O1: ≈ 19 683 MPI
tasks (373 248 water
molecules)
O2: ≈ 9 261 MPI
tasks (175 616 water
molecules)
Image credit: [Weber2015]
10 c○ 2016 IBM Corporation](https://image.slidesharecdn.com/smmm-graphhpc-2016-160303132710/85/Midpoint-Based-Parallel-Sparse-Matrix-Matrix-Multiplication-Algorithm-10-320.jpg)
![Strong scaling experiments
∙ Water molecules:
S1: 110 592
S2: 373 248
S3: 1 124 864
∙ MPI tasks:
S1: 216 ÷ 59 319
S2: 1 728 ÷ 110 592
S3: 9 261 ÷ 185 193
∙ MPSM3 vs. SUMMA
crossover point — slightly
smaller than S2 Image credit: [Weber2015]
11 c○ 2016 IBM Corporation](https://image.slidesharecdn.com/smmm-graphhpc-2016-160303132710/85/Midpoint-Based-Parallel-Sparse-Matrix-Matrix-Multiplication-Algorithm-11-320.jpg)





Документ описывает алгоритм параллельного разреженного умножения матриц на основе средних значений. Основное внимание уделяется проблемам масштабируемости существующих алгоритмов и представлению нового метода, который использует принцип распределения по средним и обеспечивает линейную масштабируемость с учетом ресурсов. Указаны преимущества нового алгоритма, такие как снижение объема коммуникаций и более эффективное распределение нагрузки.















