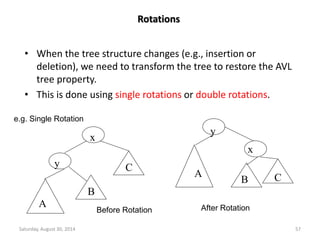
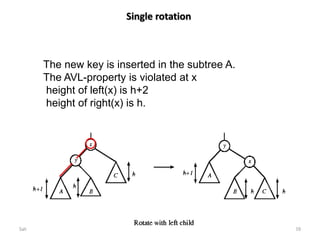
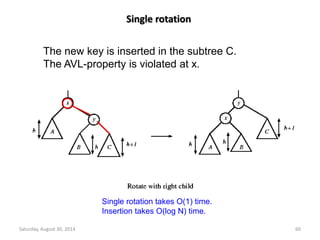
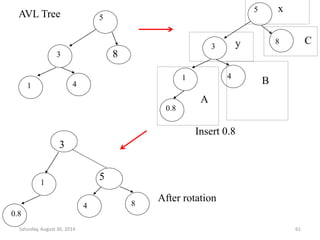
Downloaded 19 times

![ARRAYS
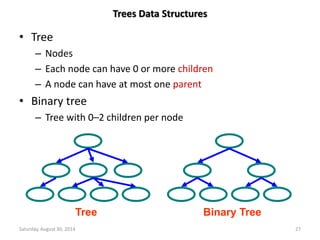
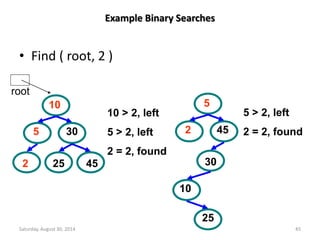
An array is a collection of homogeneous data elements described
by a single name. Each element is referenced by a subscripted
variable or value, called subscript or index enclosed in
parenthesis.
•If an element is referenced by a single subscript, then array is
known as 1-D or single array (linear array). --- Array[N]
•If two subscripts are required, the array is known as 2-D or
matrix array. ---- Array[M][N]
•An array referenced by two or more subscripts is known as
multidimensional array. ----- Array[X][Y][Z]
Sparse array is an application of arrays where nearly all the
elements have same values (usually zeros) and this value is
constant. 1-D sparse array is called sparse vector and 2-D sparse
array is called sparse matrix.
Saturday, August 30, 2014 4](https://image.slidesharecdn.com/elementarydatastructures-imp1-140830083049-phpapp02/85/ELEMENTARY-DATASTRUCTURES-4-320.jpg)













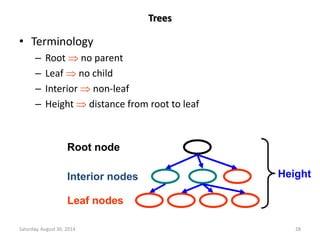















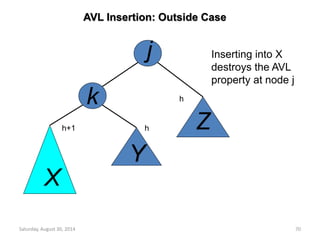





![14
[1]
[2] [3]
12 7
[5] [6]
10 8 6
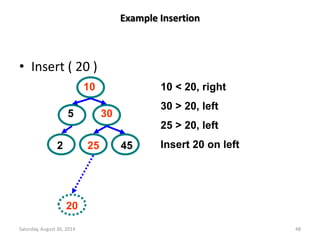
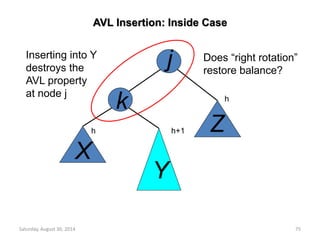
Max Heap
9
[1]
[2] [3]
6 3
5
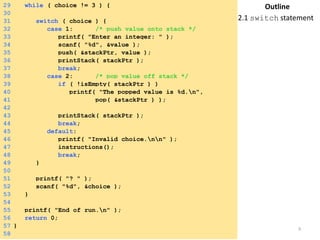
30
[1]
25
[4]
[2]
2
[1]
[2] [3]
7 4
[5] [6]
10 8 6
Min Heap
10
[1]
[2] [3]
20 83
50
11
[1]
21
[4]
[2]
[4]
Saturday, August 30, 2014 91](https://image.slidesharecdn.com/elementarydatastructures-imp1-140830083049-phpapp02/85/ELEMENTARY-DATASTRUCTURES-91-320.jpg)
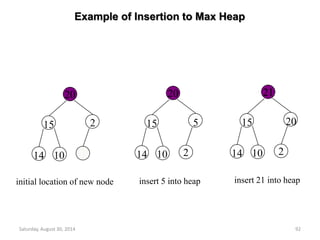
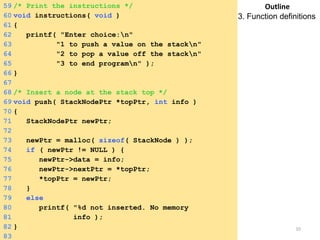
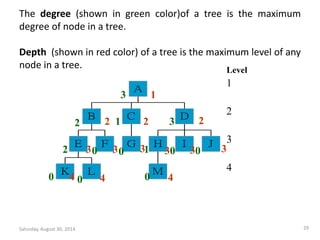
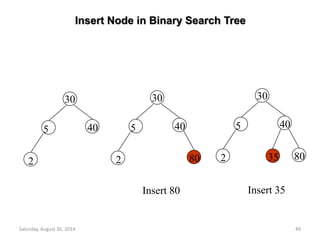
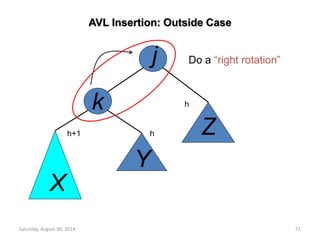
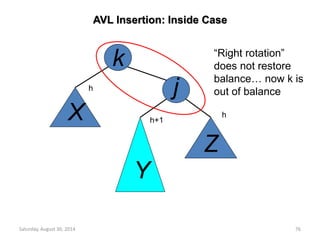
![Insertion into a Max Heap
void insert_max_heap(element item, int *n)
{
int i;
if (HEAP_FULL(*n)) {
fprintf(stderr, “the heap is full.n”);
exit(1);
}
i = ++(*n);
while ((i!=1)&&(item.key>heap[i/2].key)) {
heap[i] = heap[i/2];
i /= 2;
}
heap[i]= item;
Saturday, August 30, 2014 93
}
2k-1=n ==> k=log2(n+1)
O(log2n)](https://image.slidesharecdn.com/elementarydatastructures-imp1-140830083049-phpapp02/85/ELEMENTARY-DATASTRUCTURES-93-320.jpg)
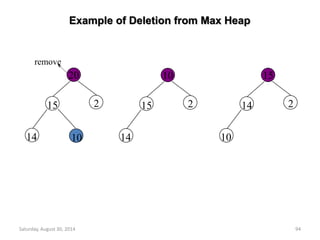
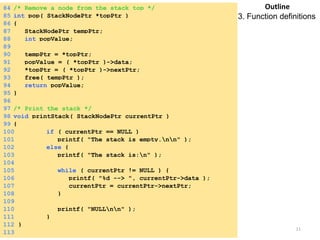
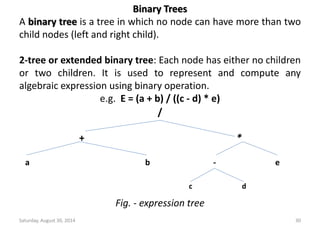
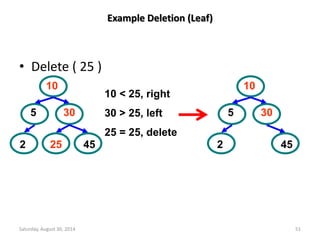
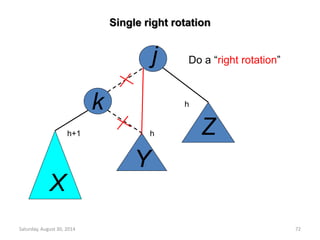
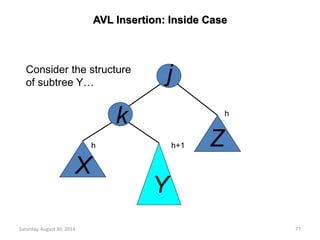
![Deletion from a Max Heap
element delete_max_heap(int *n)
{
int parent, child;
element item, temp;
if (HEAP_EMPTY(*n)) {
fprintf(stderr, “The heap is emptyn”);
exit(1);
}
/* save value of the element with the
highest key */
item = heap[1];
/* use last element in heap to adjust heap */
temp = heap[(*n)--];
parent = 1;
child = 2;
Saturday, August 30, 2014 95](https://image.slidesharecdn.com/elementarydatastructures-imp1-140830083049-phpapp02/85/ELEMENTARY-DATASTRUCTURES-95-320.jpg)
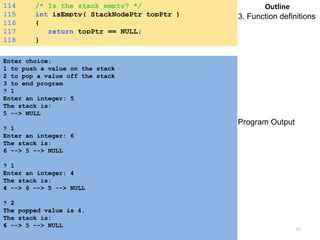
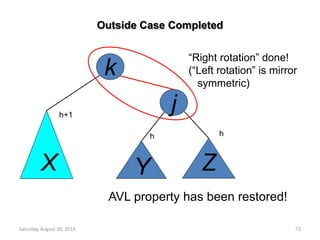
![while (child <= *n) {
/* find the larger child of the current
parent */
if ((child < *n)&&
(heap[child].key<heap[child+1].key))
child++;
if (temp.key >= heap[child].key) break;
/* move to the next lower level */
heap[parent] = heap[child];
child *= 2;
}
heap[parent] = temp;
return item;
}
Saturday, August 30, 2014 96](https://image.slidesharecdn.com/elementarydatastructures-imp1-140830083049-phpapp02/85/ELEMENTARY-DATASTRUCTURES-96-320.jpg)


This document discusses data structures and algorithms. It begins by defining a data structure as the organized representation of data elements and relationships. It then discusses various data structures like arrays, lists, stacks, and queues. For each, it provides definitions and examples. It also includes C code examples to demonstrate implementing and using stacks and queues. The document is intended to teach fundamental data structures and their applications in algorithms.



















![Data Structures - Lecture 6 [queues]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-6queues-150114114904-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



![Introduction to Pandas and Time Series Analysis [PyCon DE]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontopandasandtimeseriesanalysispyconde-170617163724-thumbnail.jpg?width=640&height=640&fit=bounds)





































































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)






