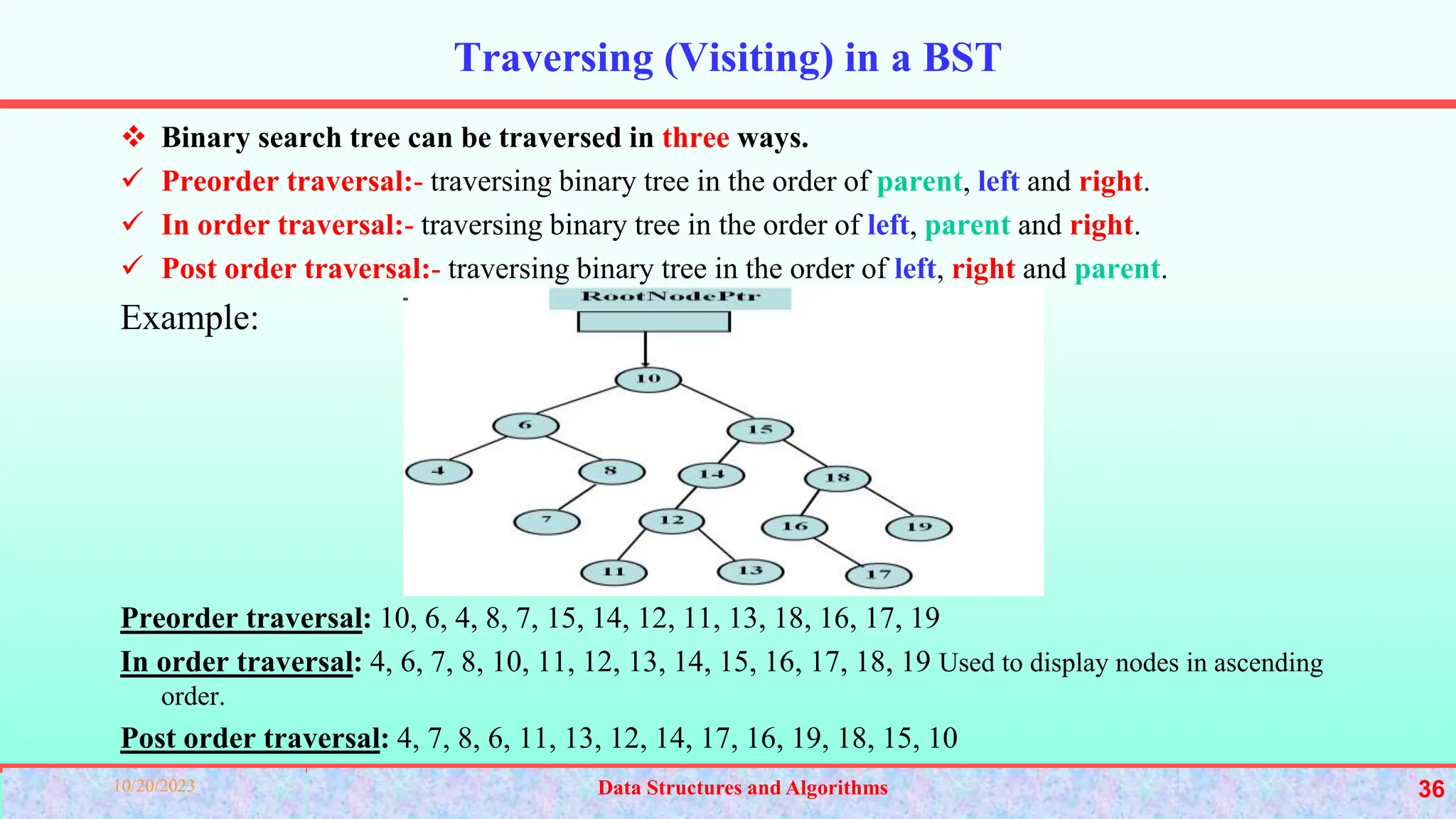
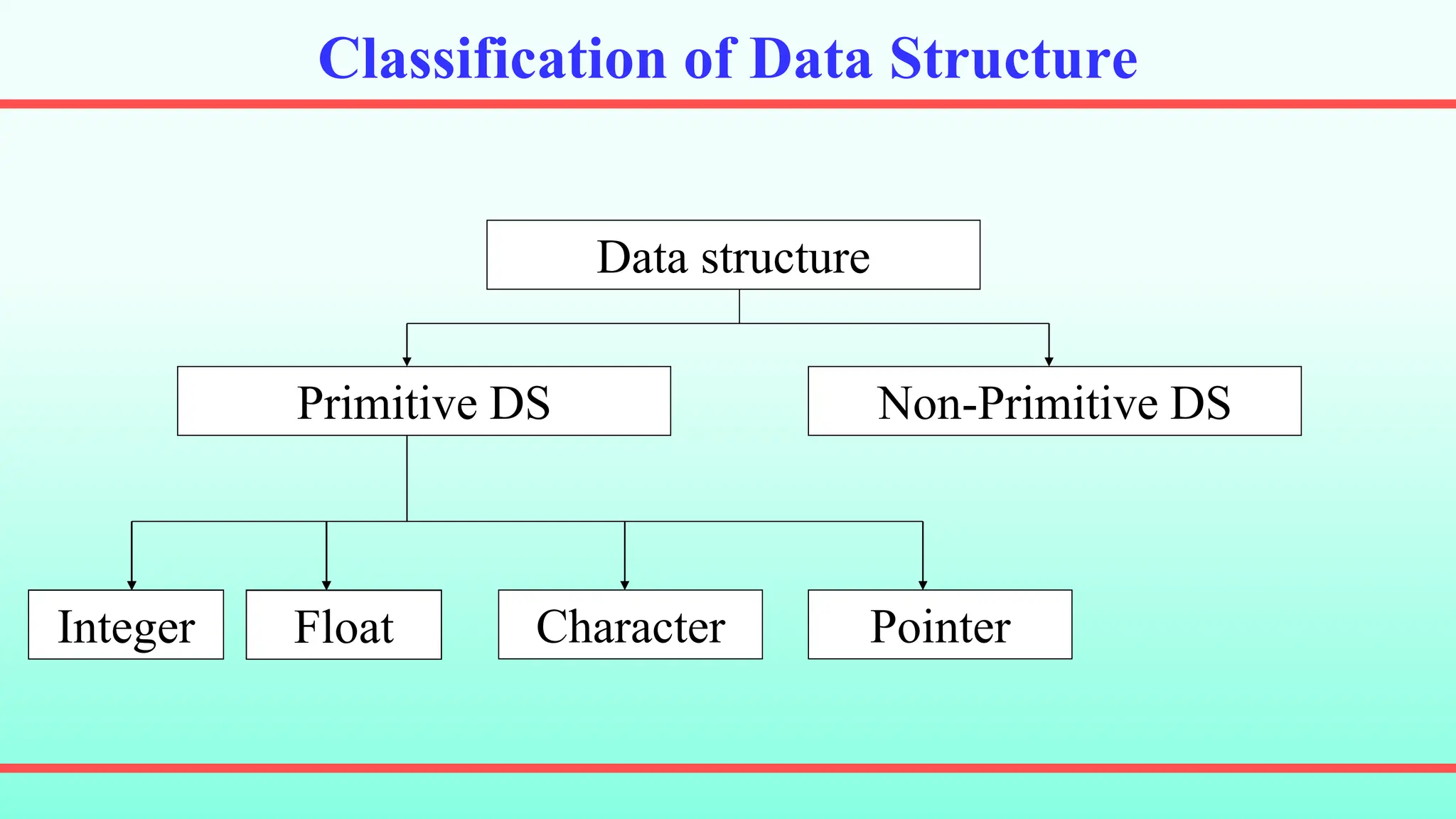
This chapter discusses different data structures and their applications. It begins with classifying data structures as primitive and non-primitive. Common linear data structures like stacks, queues, and linked lists are described. Stacks follow LIFO while queues follow FIFO. Linked lists use nodes connected by pointers. The chapter provides examples of implementing operations for these structures.







![Array
Why array????
An array is a linear data structure and it is a collection of items stored at contiguous memory
locations.
The idea is to store multiple items of the same type together in one place. It allows the processing
of a large amount of data in a relatively short period. The first element of the array is indexed by 0.
It cannot contain the elements of different types like integer with character. The commonly used
operation in an array is insertion, deletion, traversing, searching.
For example:
int a[6] = {1,2,3,4,5,6};
10/20/2023 9
Data Structures and Algorithms](https://image.slidesharecdn.com/chapterthreeppt-231020121710-89c52342/75/chapter-three-ppt-pptx-9-2048.jpg)







![Inserting on stack(push)
void push()
{
int val
if (top == n - 1)
cout << "Stack Overflow" << endl;
else
{
if (top == - 1)
top= 0;
cout << "Insert an element to push : " << endl;
cin>>val;
top++;
stack[top] = val;
}
}
10/20/2023 17
Data Structures and Algorithms](https://image.slidesharecdn.com/chapterthreeppt-231020121710-89c52342/75/chapter-three-ppt-pptx-17-2048.jpg)











![Implementation of queue
int f = - 1, r = - 1, n=3;
To enqueue an element
void enqueue()
{
int val;
if (r == n-1 )
cout <<"Queue Overflow"<<endl;
else
{
if (f == - 1)
f = 0;
cout <<"Insert the element in queue : "<<endl;
cin>>val;
r++;
q[r] = val;
}
}
10/20/2023 29
Data Structures and Algorithms](https://image.slidesharecdn.com/chapterthreeppt-231020121710-89c52342/75/chapter-three-ppt-pptx-29-2048.jpg)