Download as PDF, PPTX


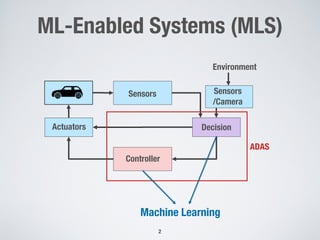







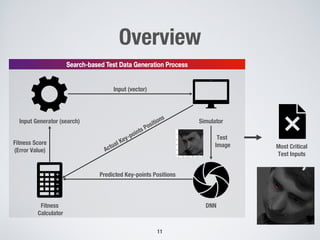



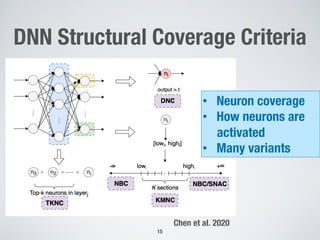




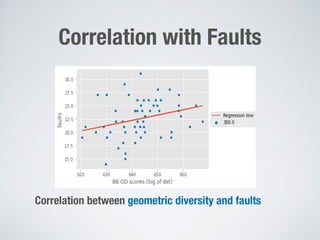





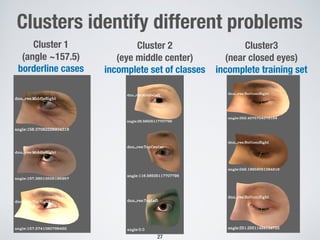
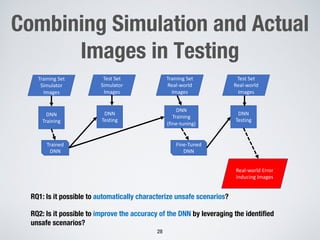
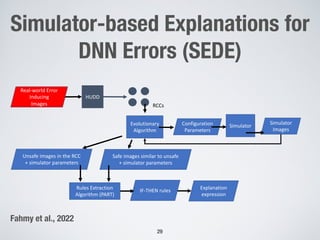

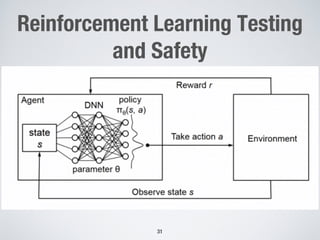


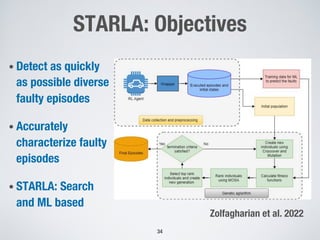

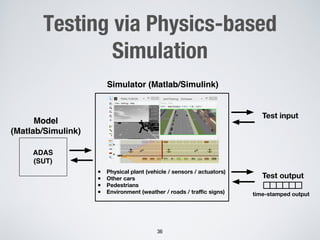


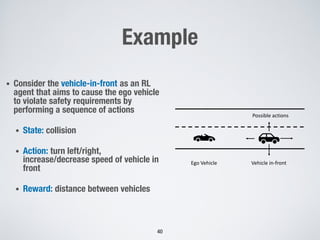
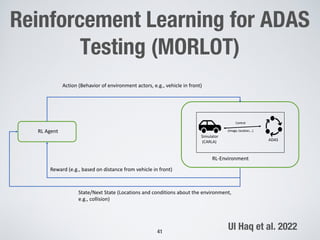
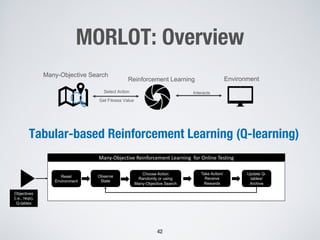


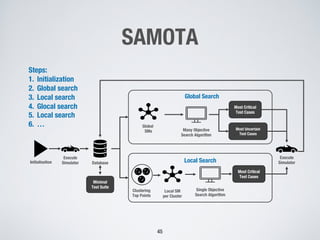








This document discusses search-based approaches for testing artificial intelligence systems. It covers testing at different levels, from model-level testing of individual machine learning components to system-level testing of AI-enabled systems. At the model level, search-based techniques are used to generate test inputs that target weaknesses in deep learning models. At the system level, simulations and reinforcement learning are used to test AI components integrated into complex systems. The document outlines many open challenges in AI testing and argues that search-based approaches are well-suited to address challenges due to the complex, non-linear behaviors of AI systems.