












![Add the Managed Disk Resource:
{
"apiVersion": "2017-03-30",
"type": "Microsoft.Compute/disks",
"name": "myManagedDataDisk",
"location": "[resourceGroup().location]",
"zones": ["1"],
"properties":
{
"creationData":
{
"createOption": "Empty"
},
"accountType
:"[parameters('storageAccountType')]",
"diskSizeGB": 128
}
}
Add the Compute Resource:
{
"apiVersion": "2017-03-30",
"type": "Microsoft.Compute/virtualMachines",
"name": "[variables('vmName')]",
"location": "[resourceGroup().location]",
"zones": ["1"],
"dependsOn": [
...
],
"properties": {
"hardwareProfile": {
"vmSize": "[parameters('vmSize')]"
},
"osProfile": {
...
},
}
}
Add the VIP Resource:
{
"apiVersion": "2017-08-01",
"type":
"Microsoft.Network/publicIPAddresses",
"name":
"[variables('publicIPAddressName')]",
"location":
"[resourceGroup().location]",
"sku": {
"name": "Standard"
},
"properties": {
"publicIPAllocationMethod":
“Dynamic",
"dnsSettings": {
"domainNameLabel":
"[parameters('dnsLabelPrefix')]"
}
}
}](https://image.slidesharecdn.com/highavailabilityinazure-190125072706/75/High-Availability-in-Microsoft-Azure-30-2048.jpg)
![Zone-redundant LB:
{
"apiVersion": "2017-08-01",
{
"type": "Microsoft.Network/loadBalancers",
"name": "[variables('loadBalancerName')]",
"location": "[resourceGroup().location]",
"sku": {
"name": "Standard"
},
}
Zone-redundant VMSS:
{
"apiVersion": "2017-03-30",
"type":
"Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmssName')]",
"zones" : ["1","2","3"],
"location": "[resourceGroup().location]",
"dependsOn": [
...
],
"sku": {
...
},
"properties": {
...
},
}
Zone-redundant SQLDB:
{
"apiVersion": "2014-04-01 “,
"type":"Microsoft.Sql/servers",
"name": "[variables('sqlServerName')]",
"location":
"[resourceGroup().location]",
“zoneRedundant”: “true”,
"properties": {
...
}
}
}](https://image.slidesharecdn.com/highavailabilityinazure-190125072706/75/High-Availability-in-Microsoft-Azure-31-2048.jpg)




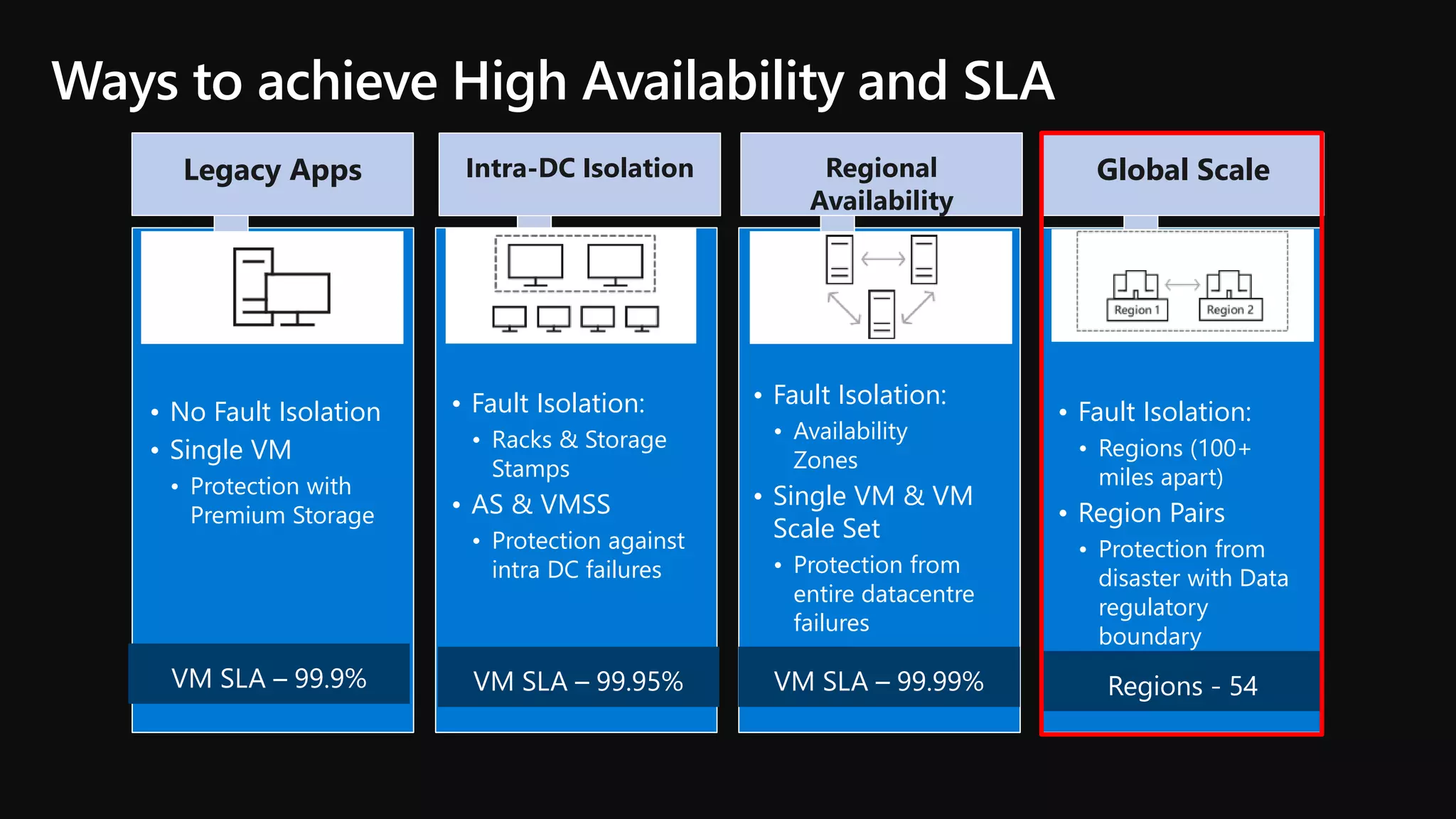
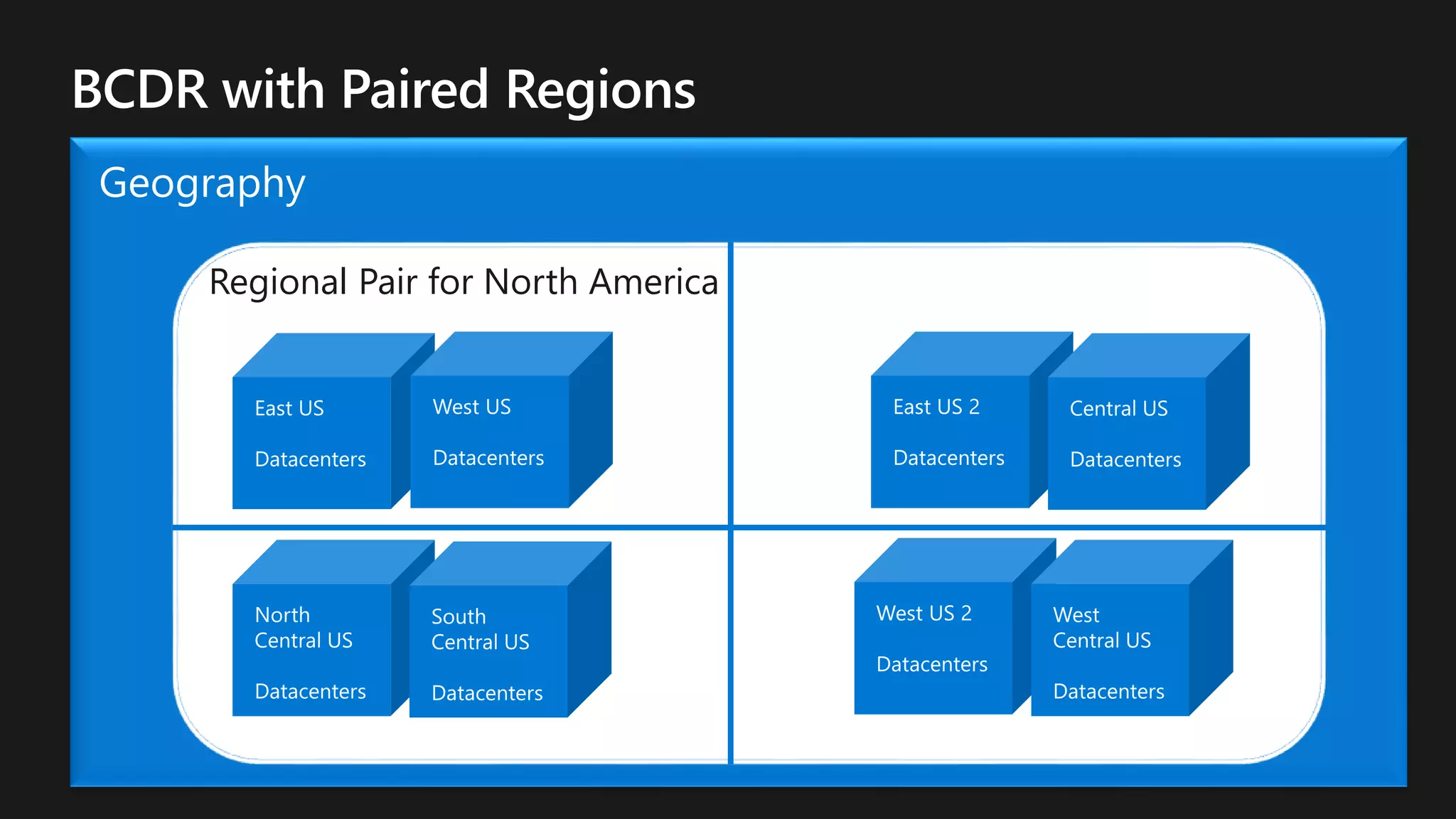


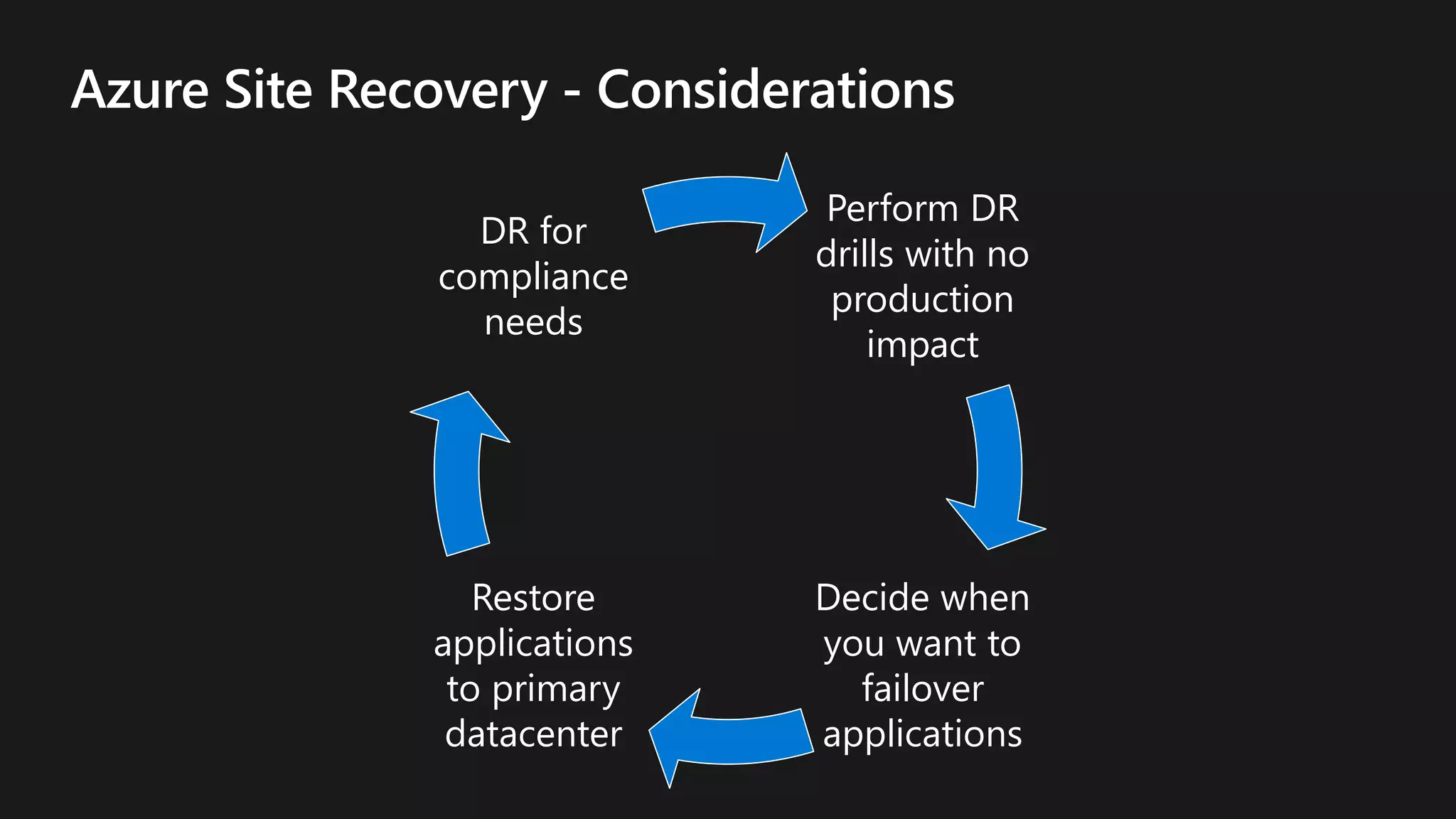




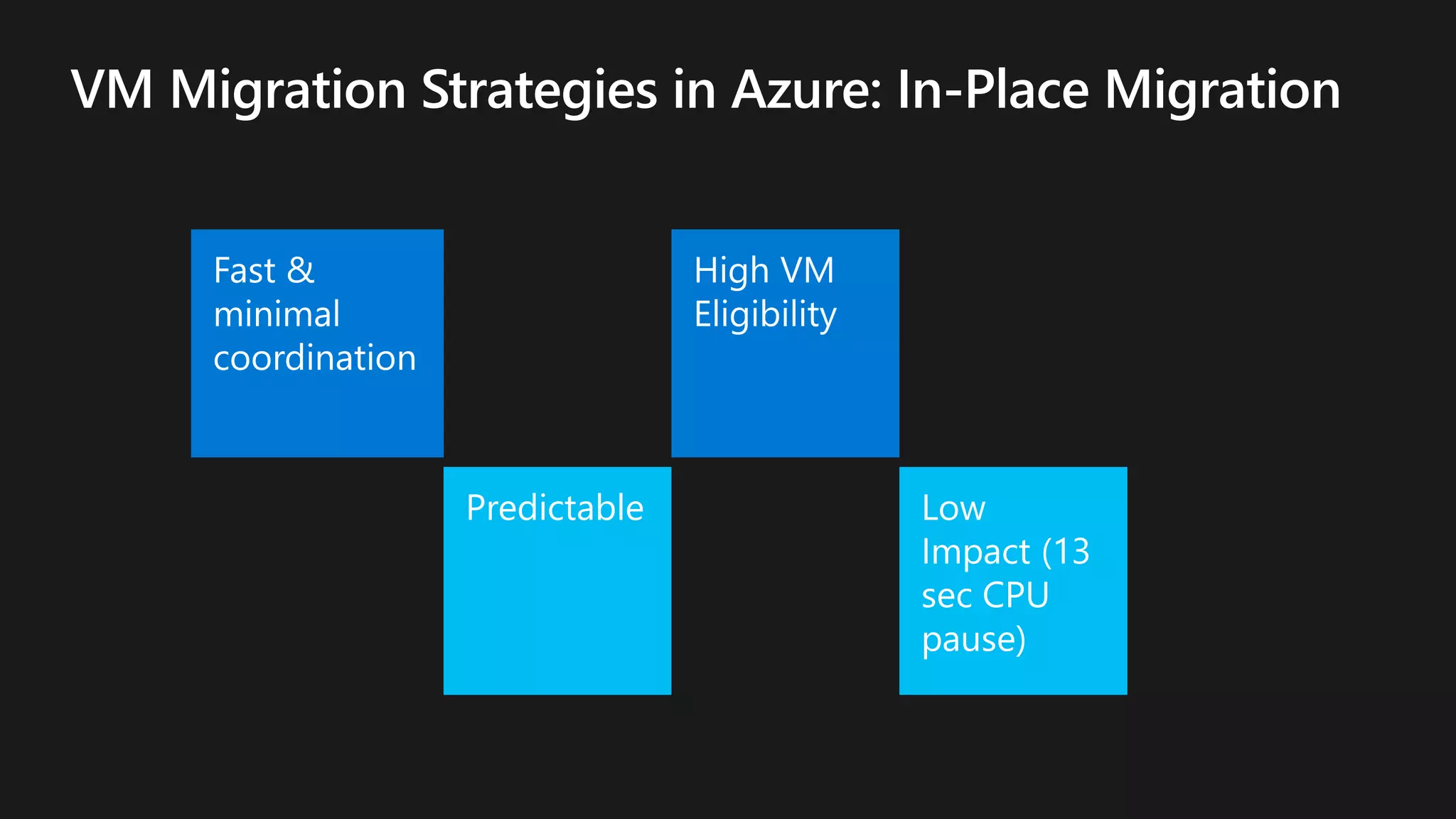
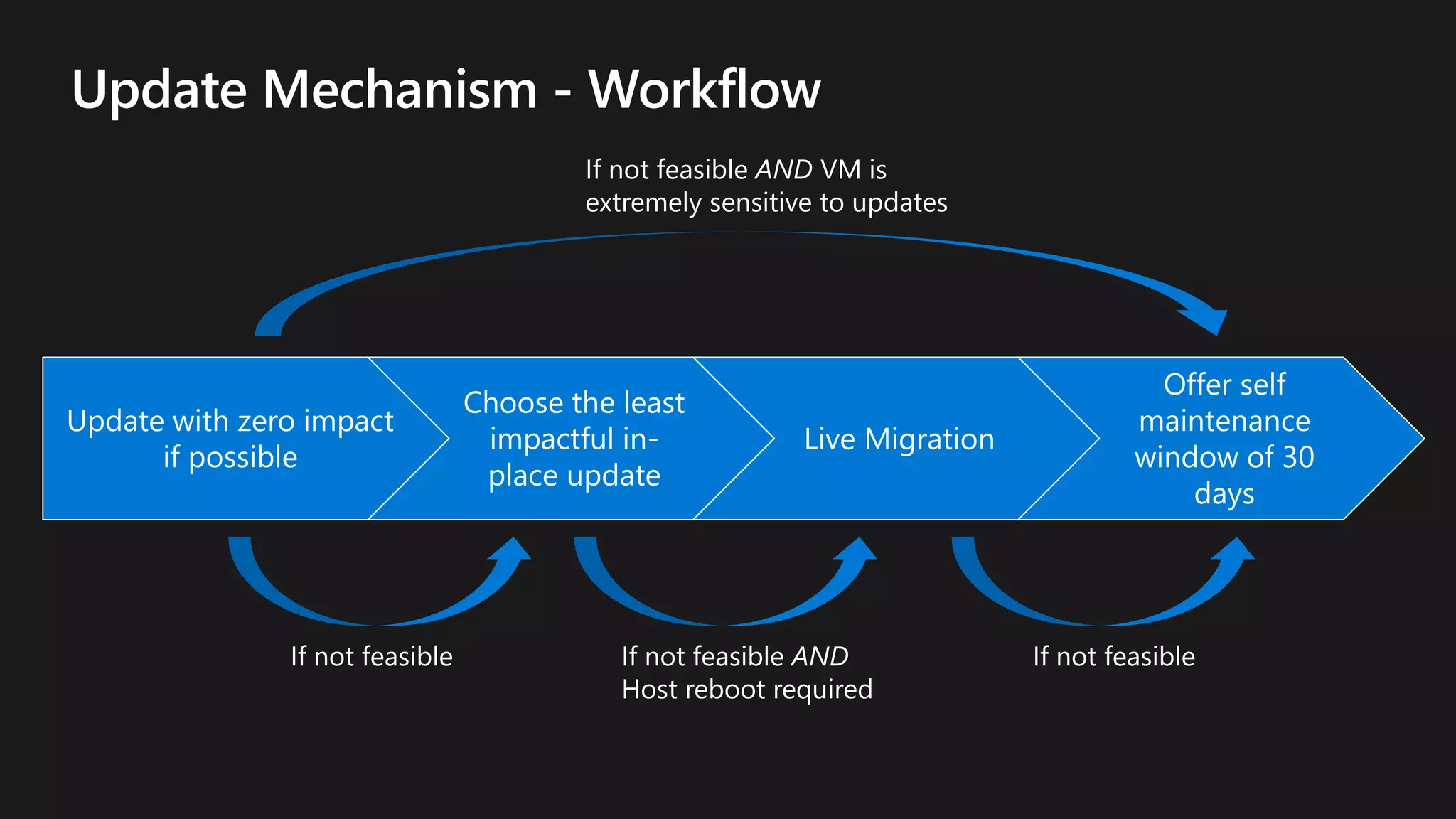
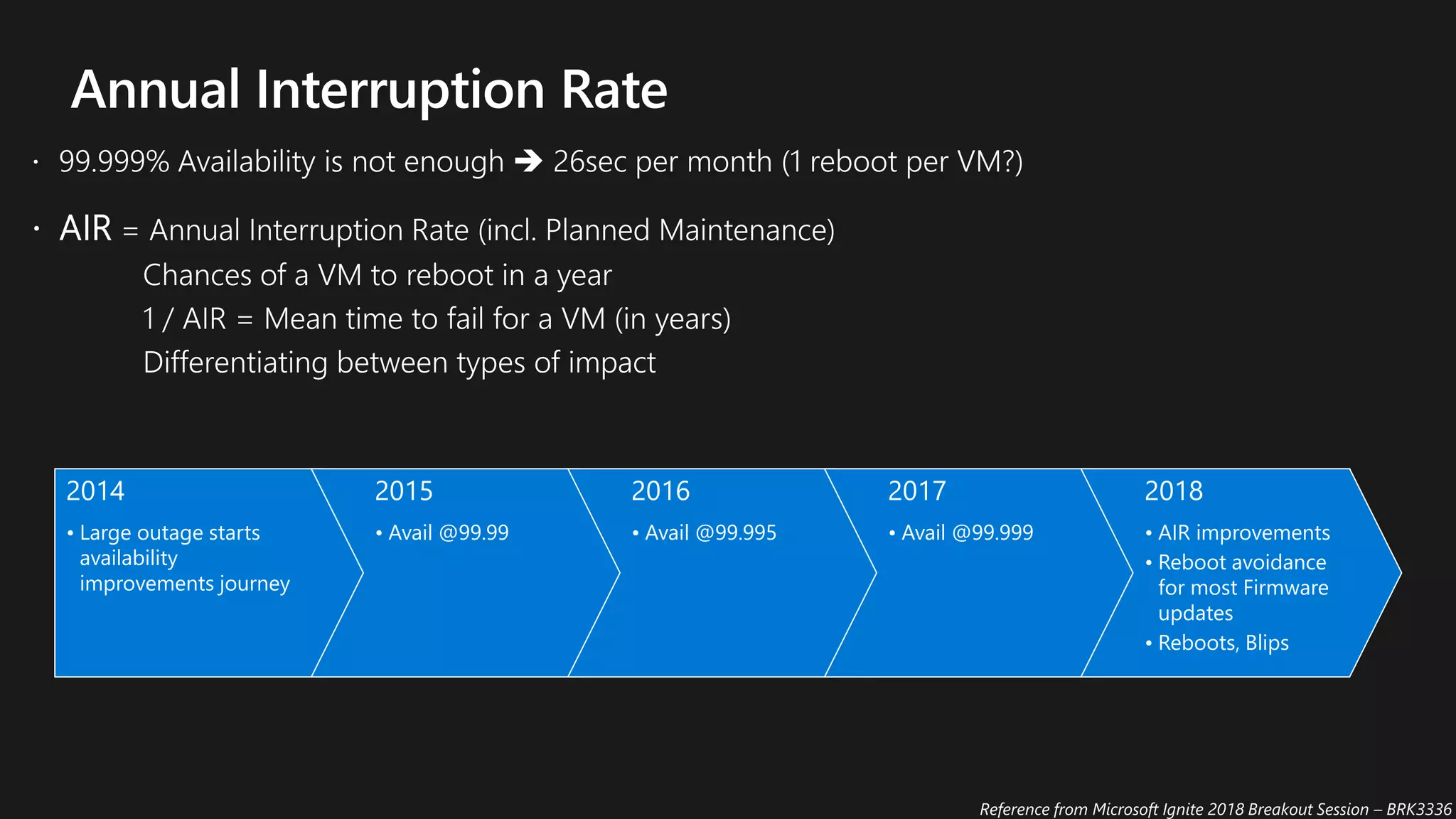
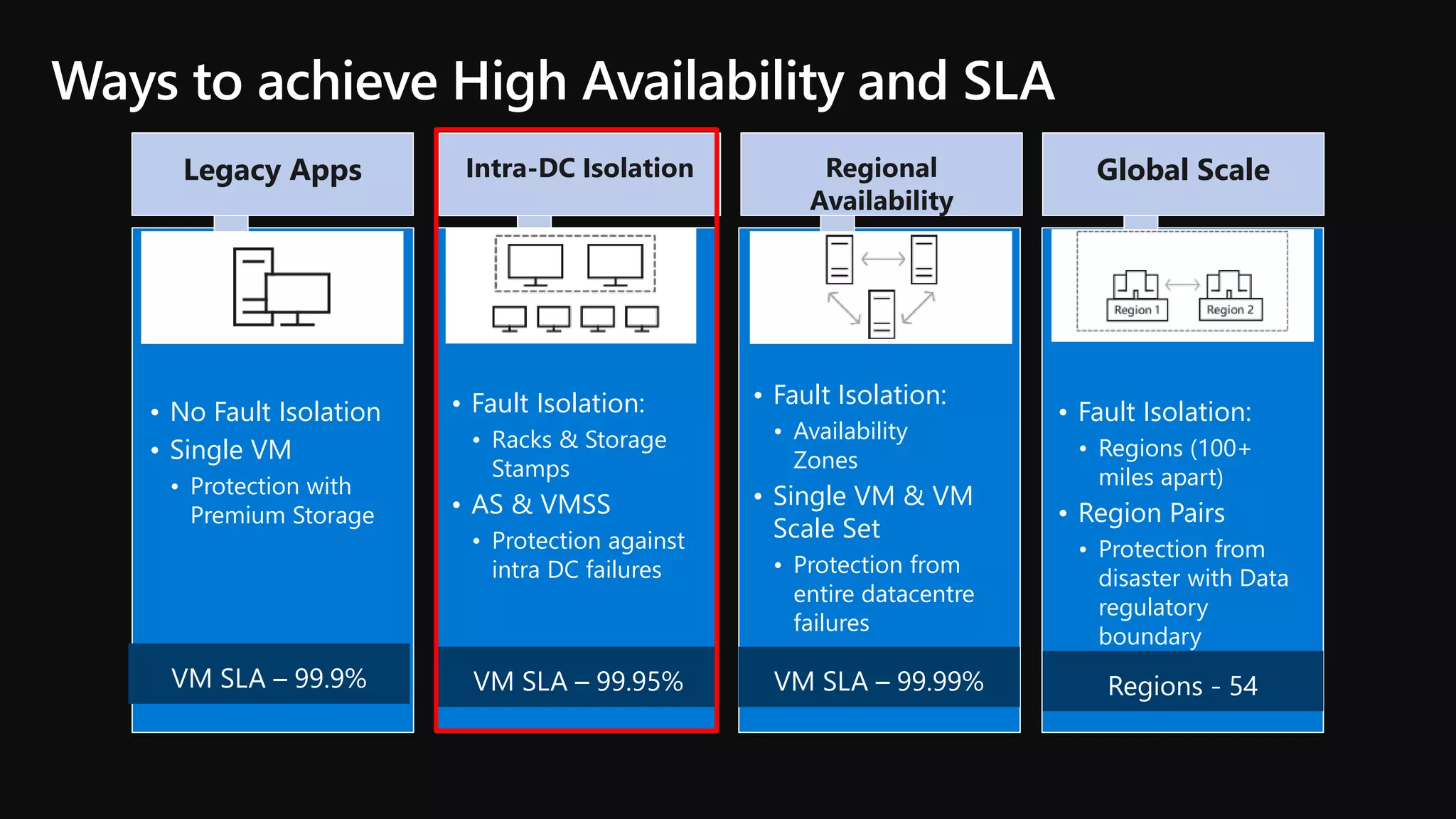
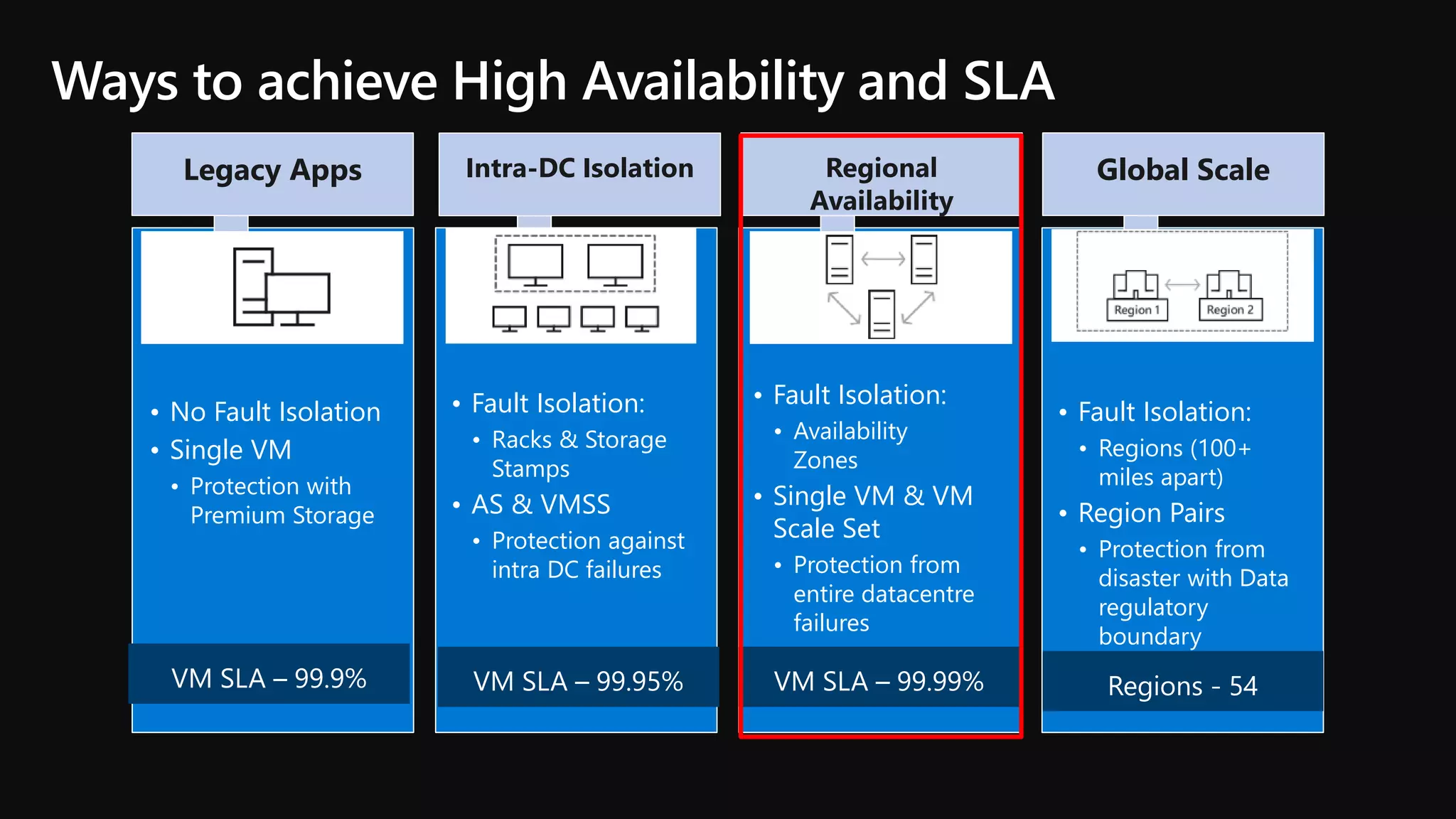
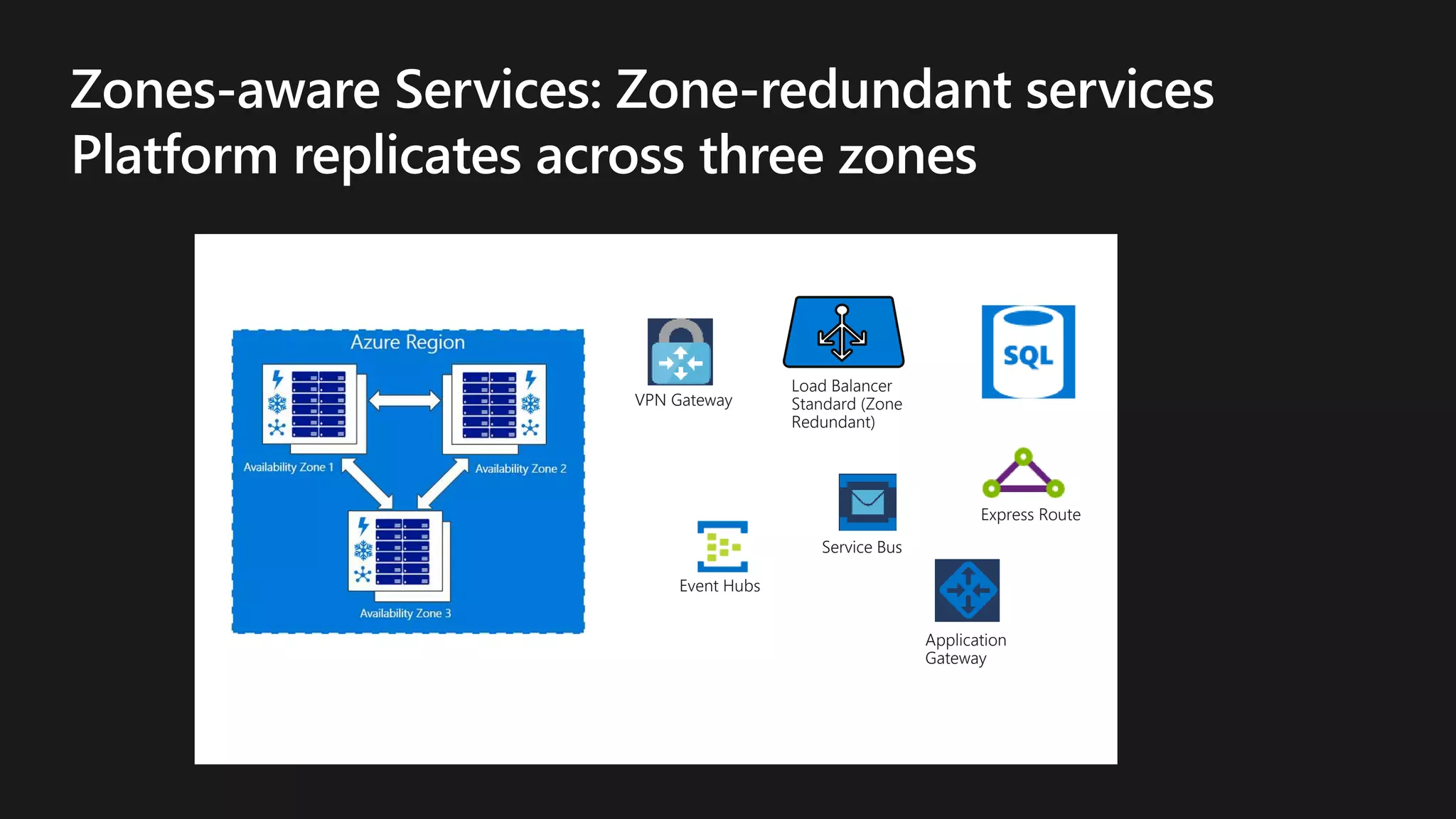
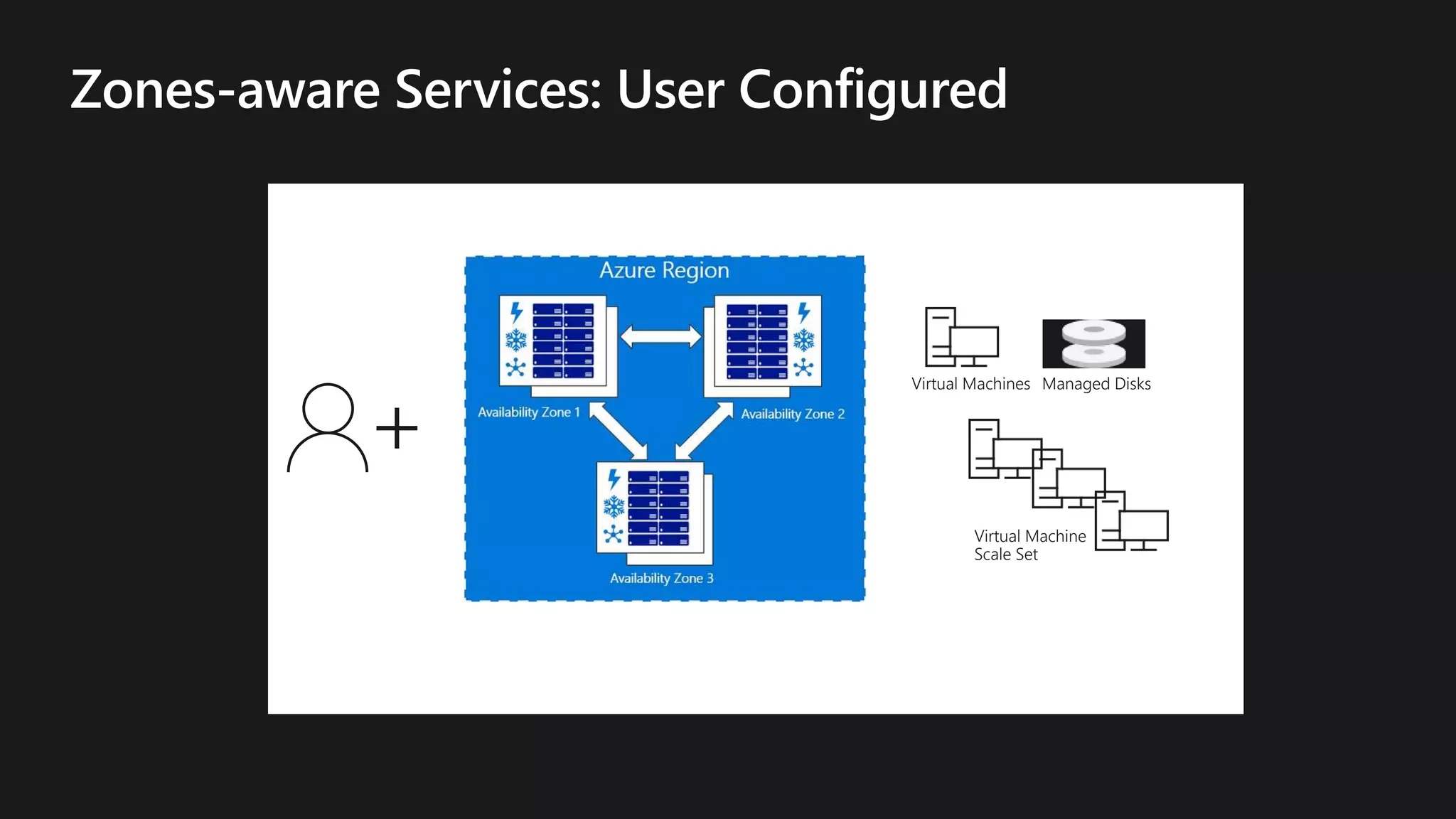
The document outlines various strategies for achieving high availability and service level agreements (SLA) in cloud infrastructure, including fault isolation techniques such as using premium storage, racks, availability zones, and region pairs. It discusses the importance of disaster recovery planning, online prediction for potential failures, and the utilization of machine learning to enhance system resilience. Key highlights include the evolution of availability goals from 99.99% to 99.999% over time, emphasizing proactive measures for failure mitigation.


























![[Azure Governance] Lesson 4 : Azure Policy](https://cdn.slidesharecdn.com/ss_thumbnails/azuregovernance-lesson4-azurepolicy-190519183014-thumbnail.jpg?width=640&height=640&fit=bounds)