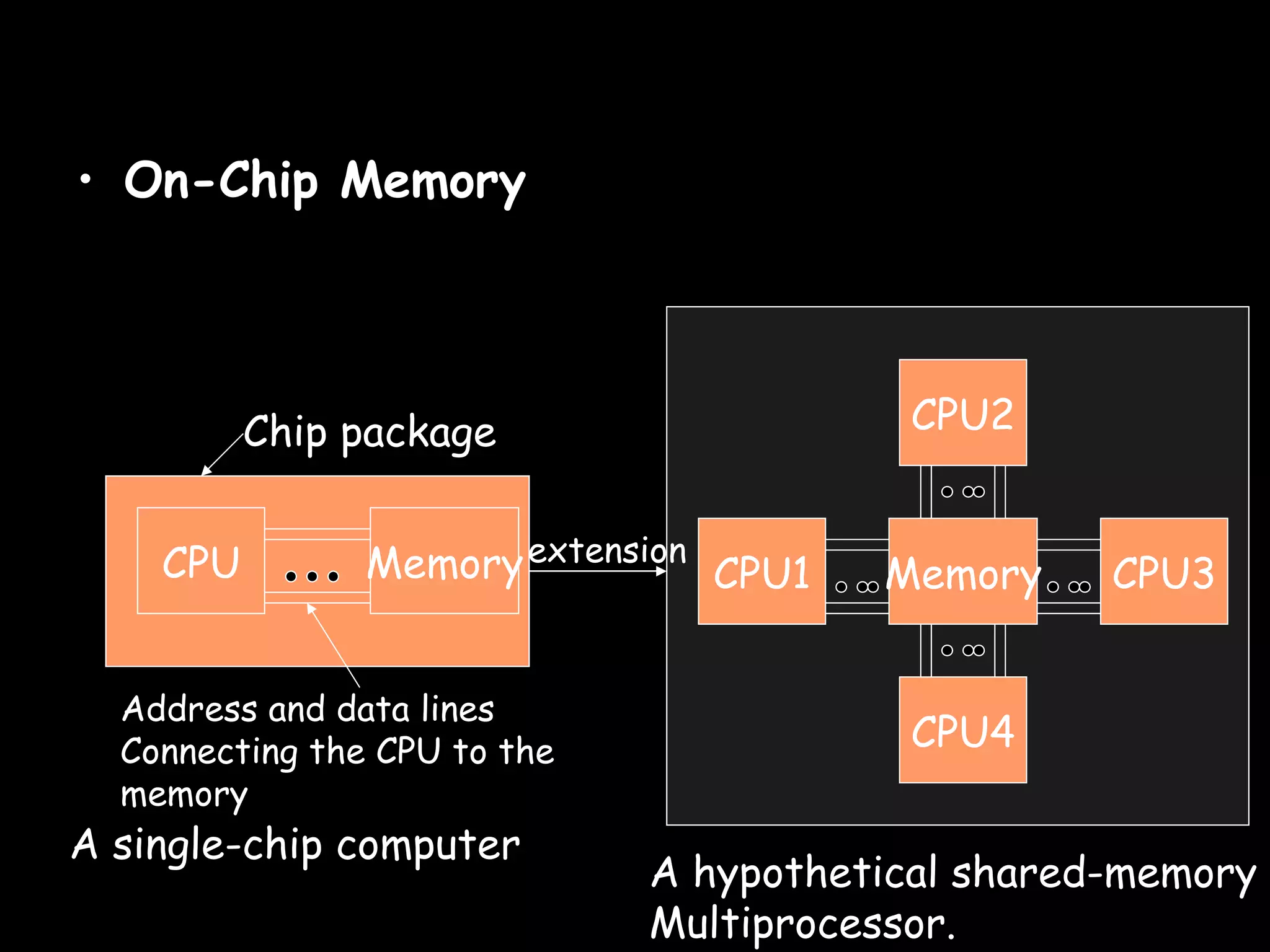
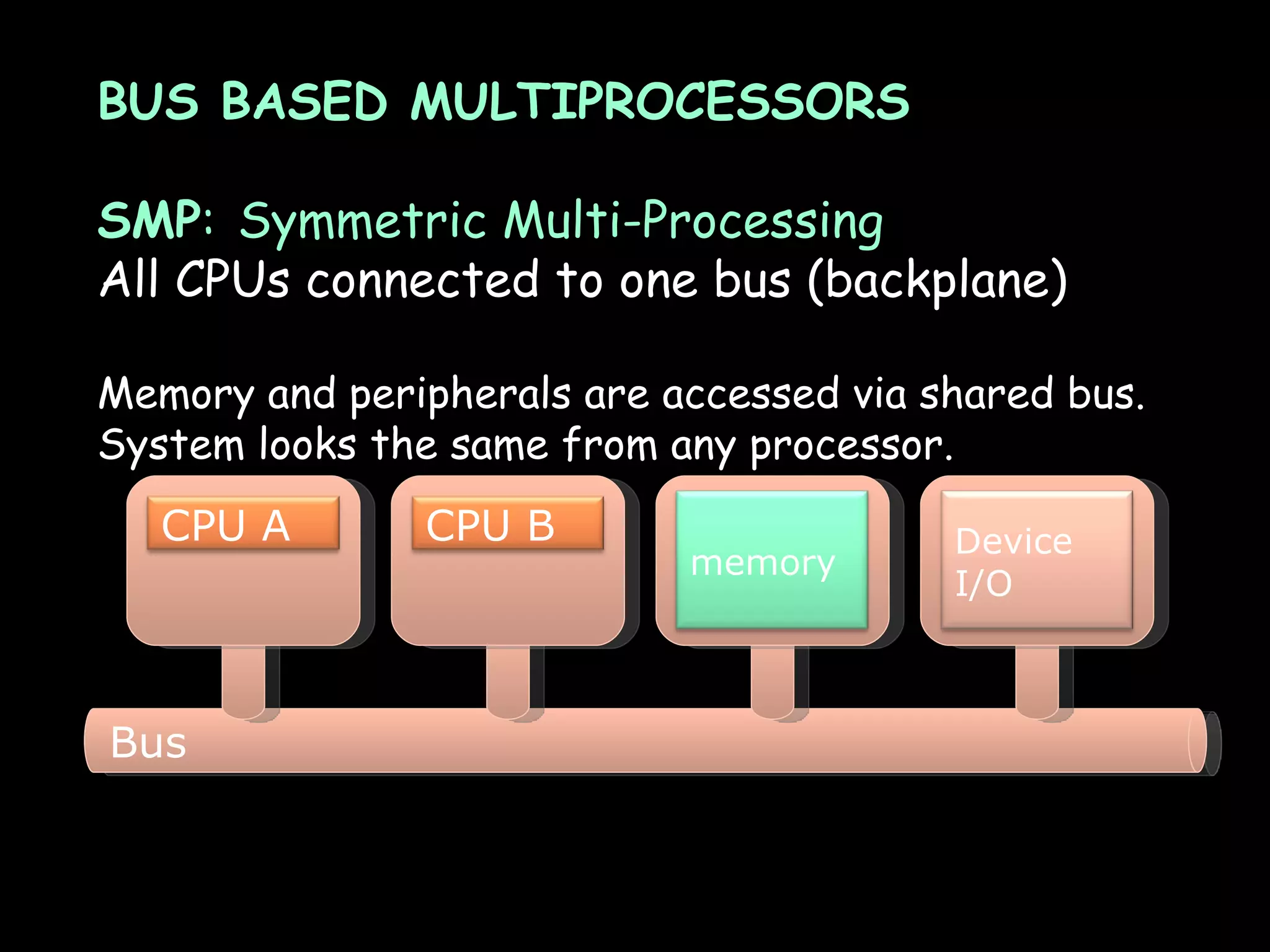
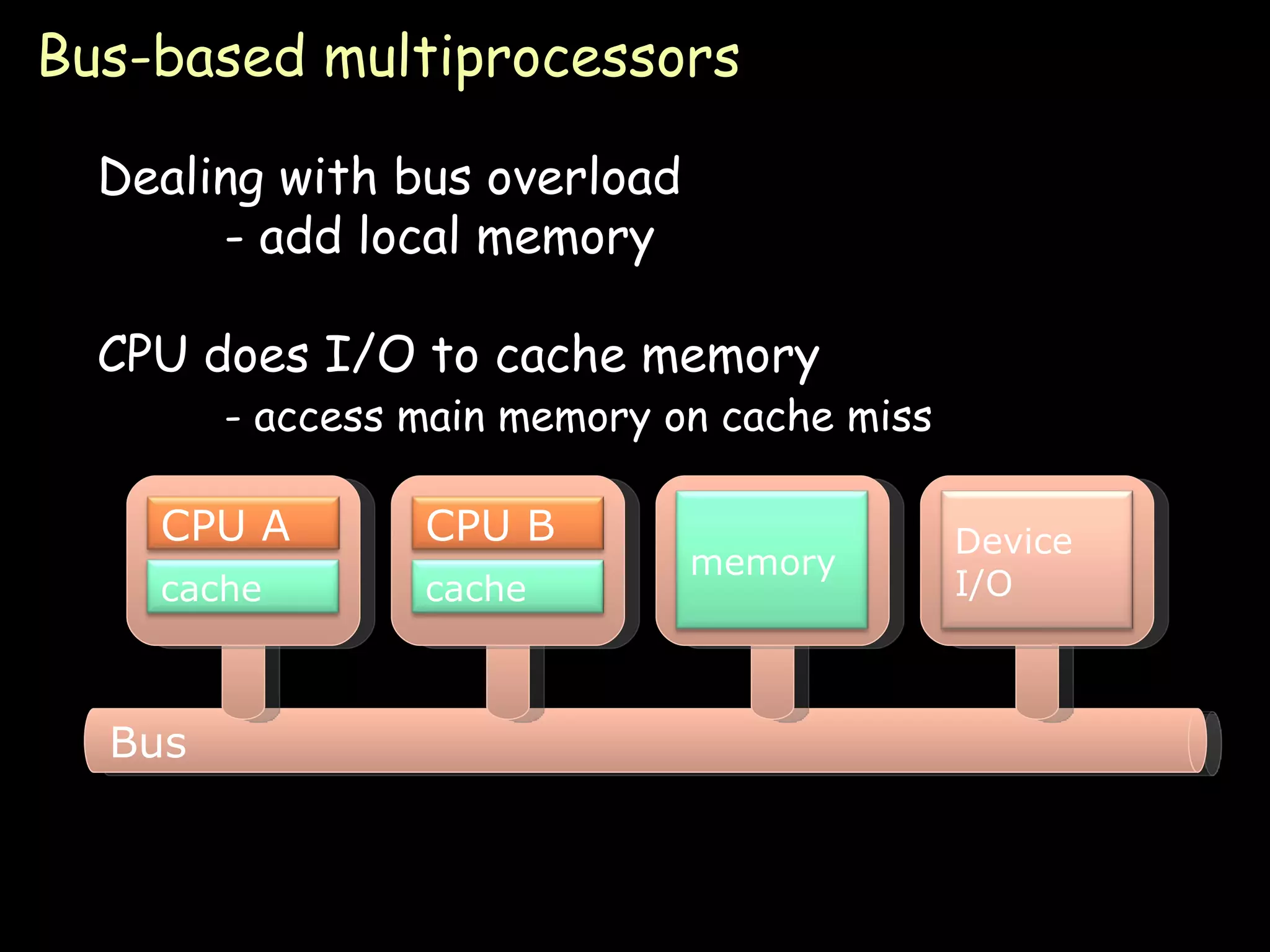
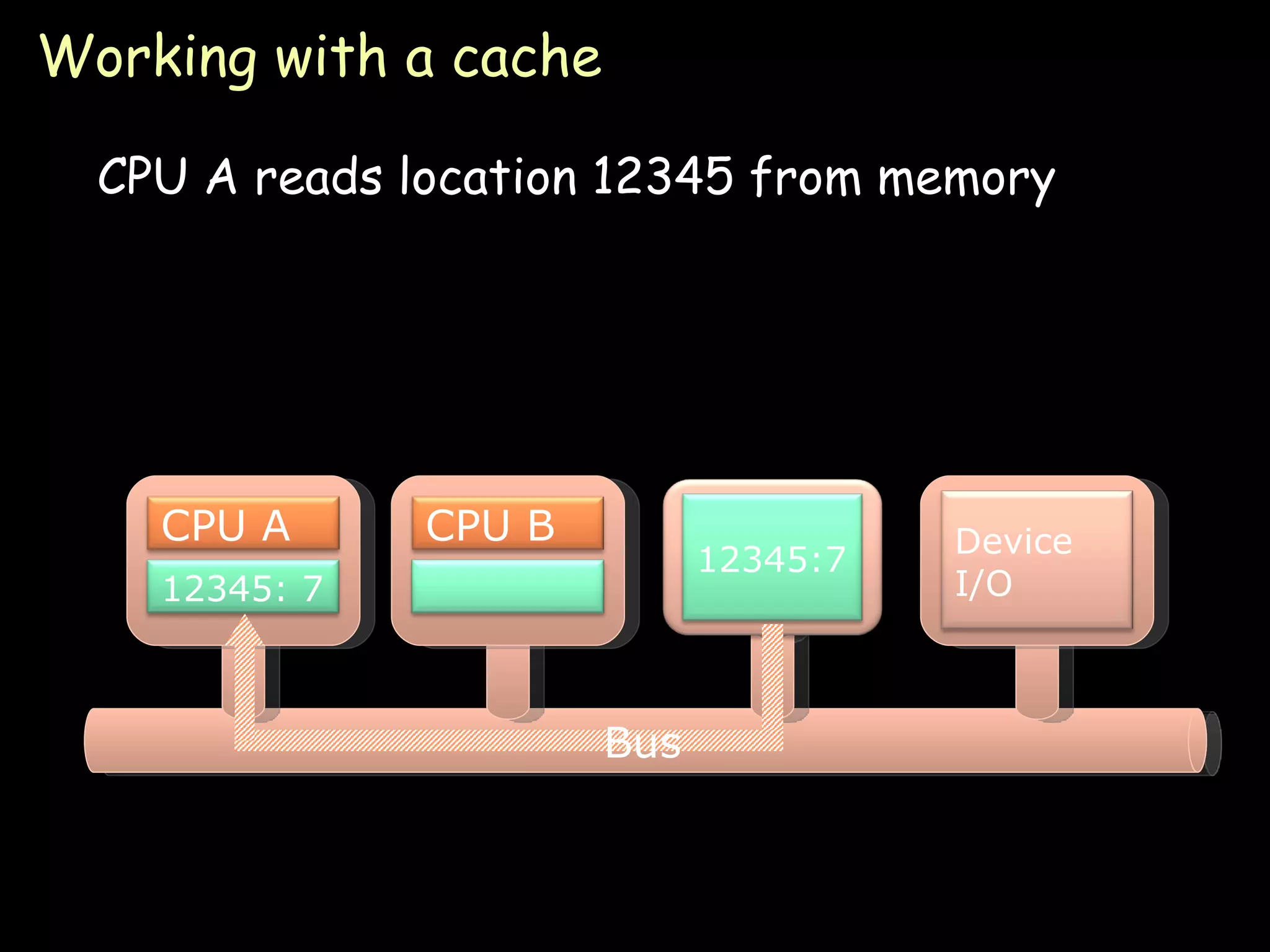
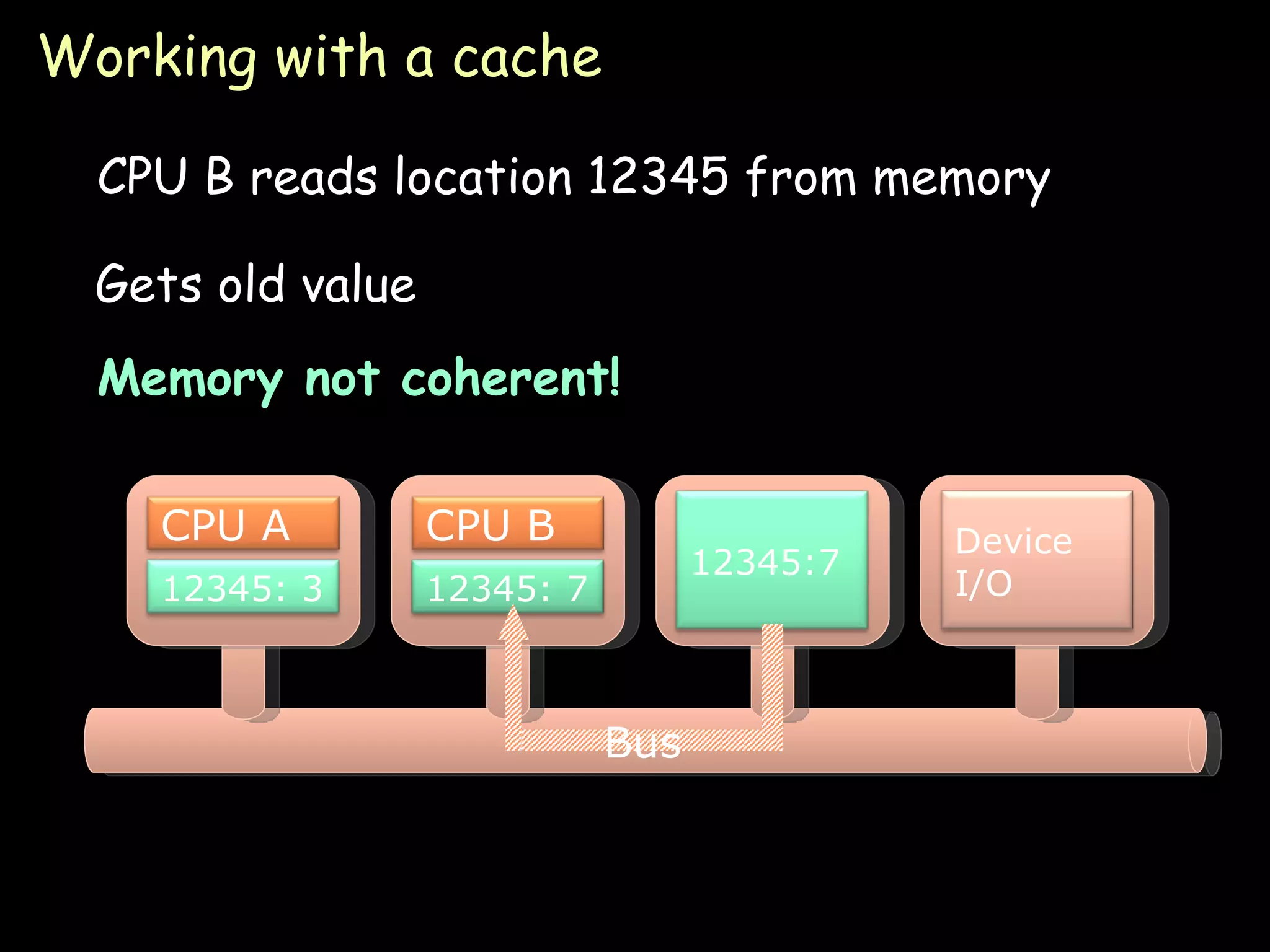
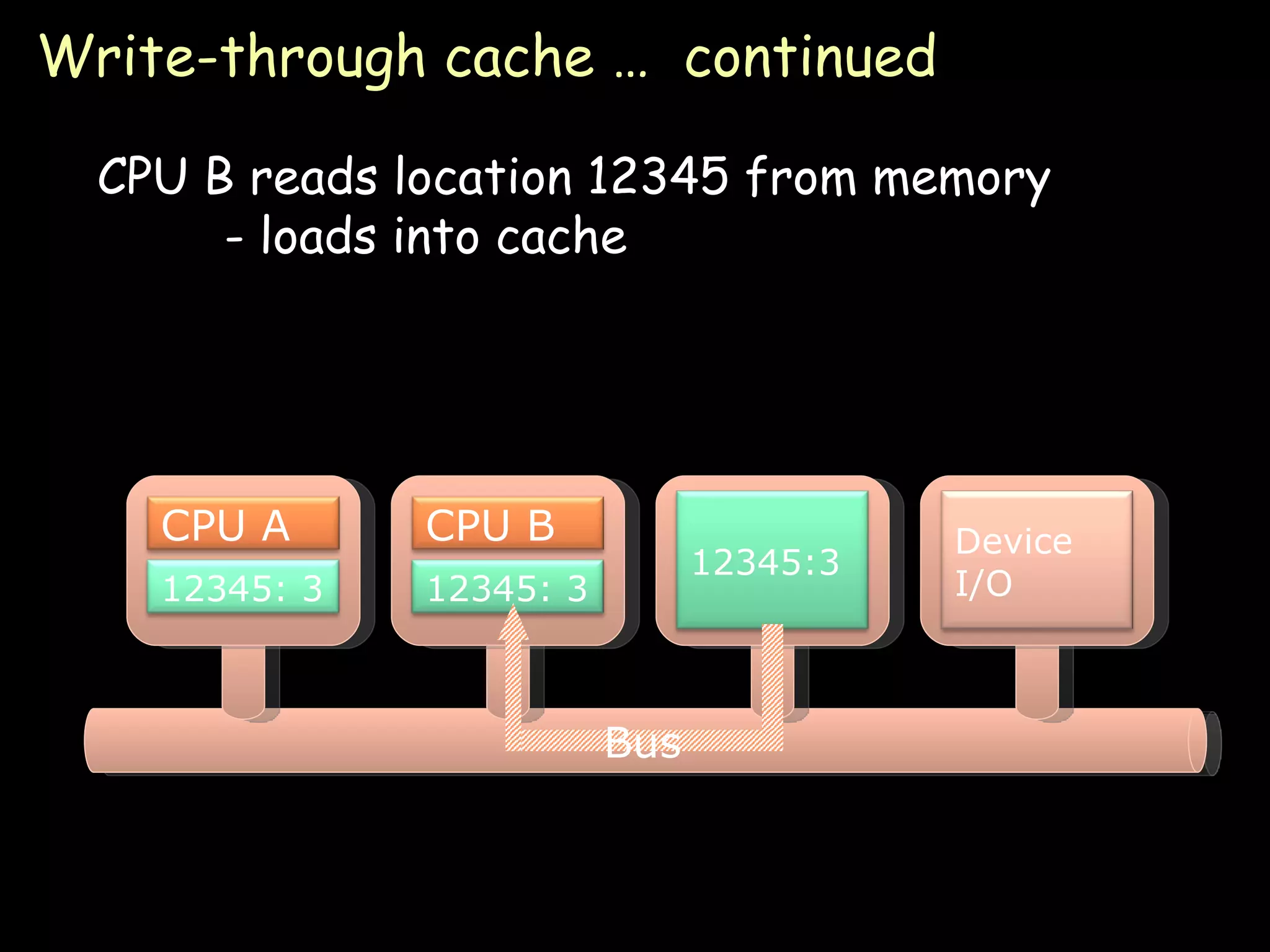
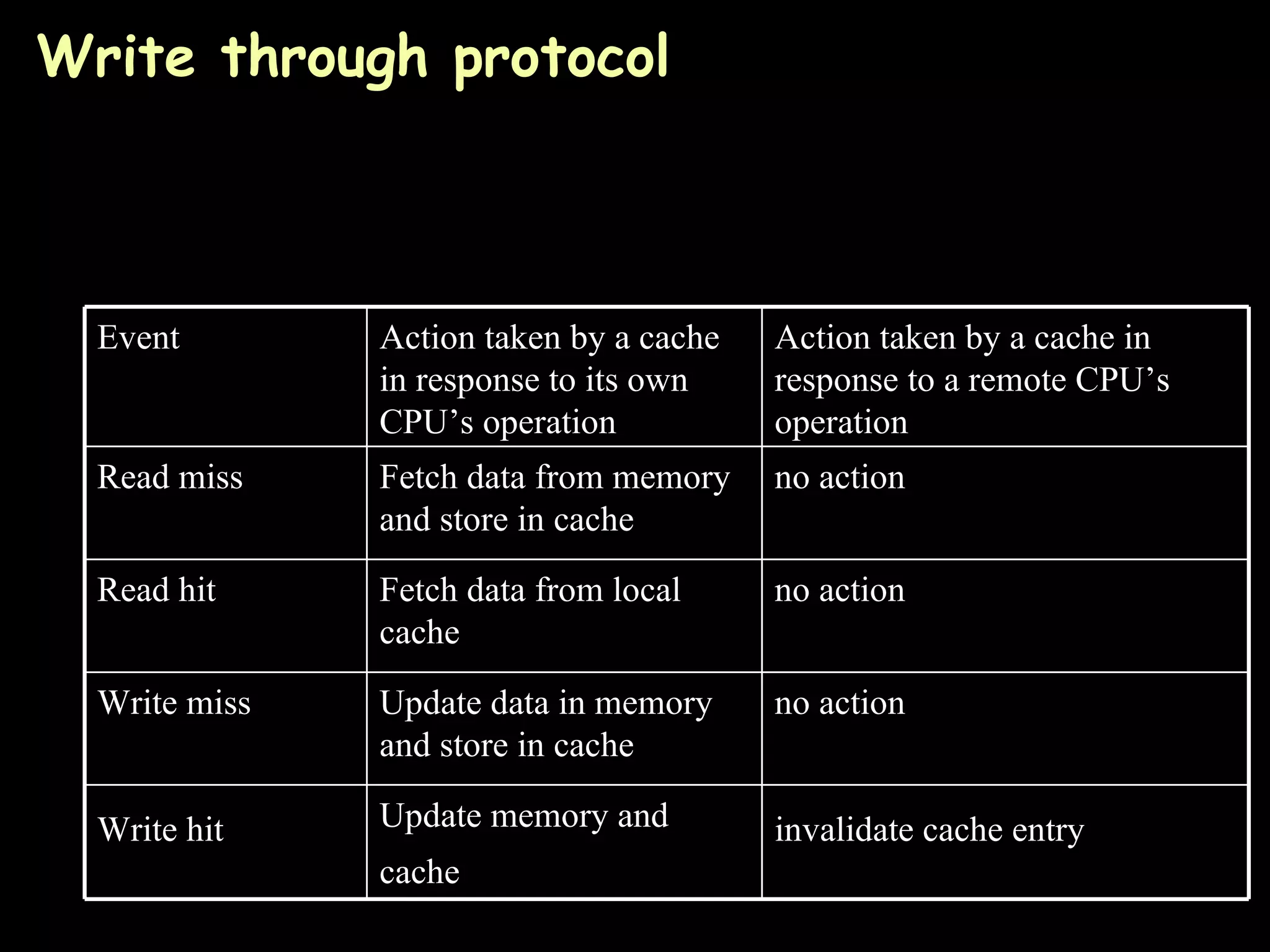
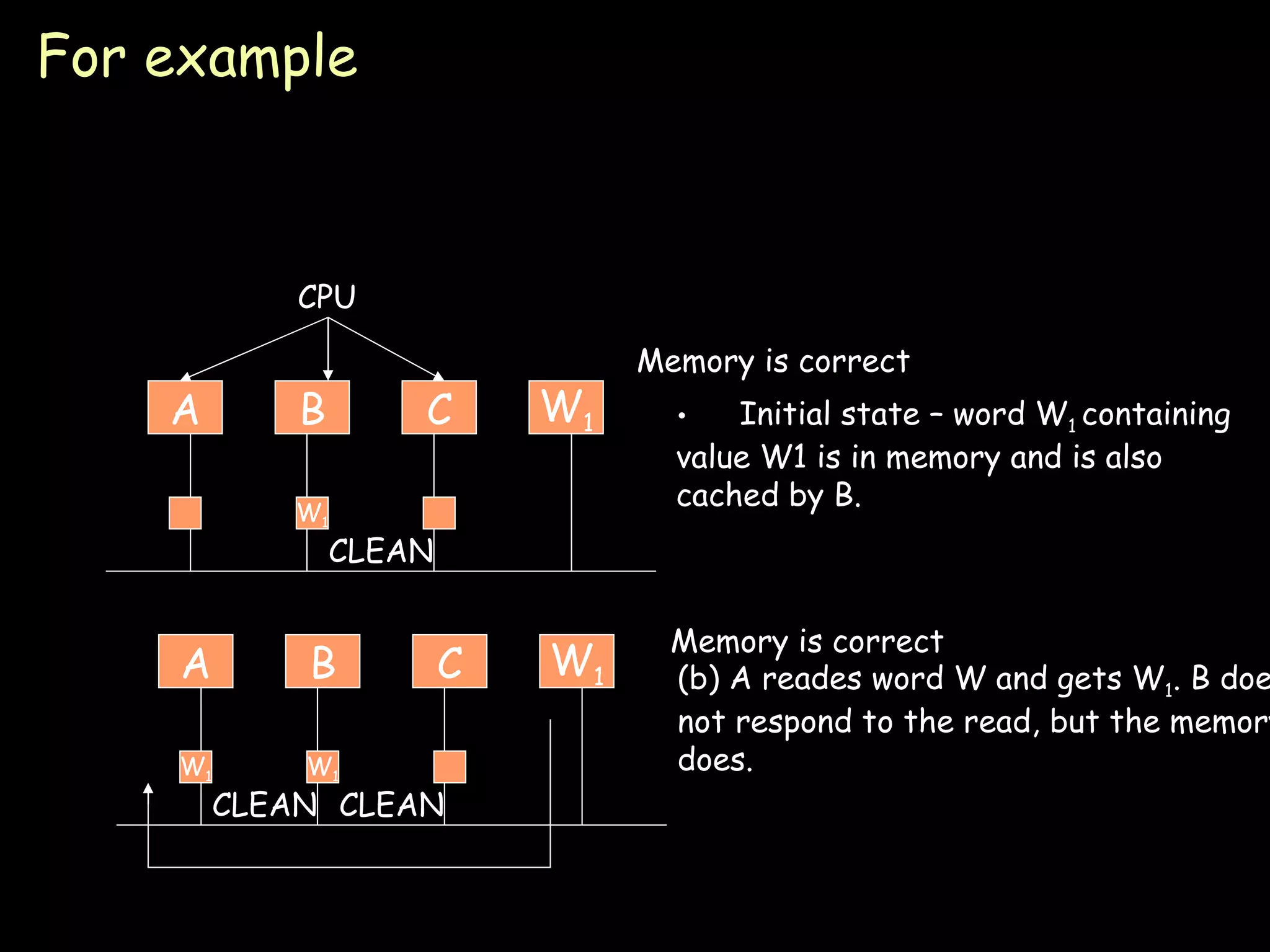
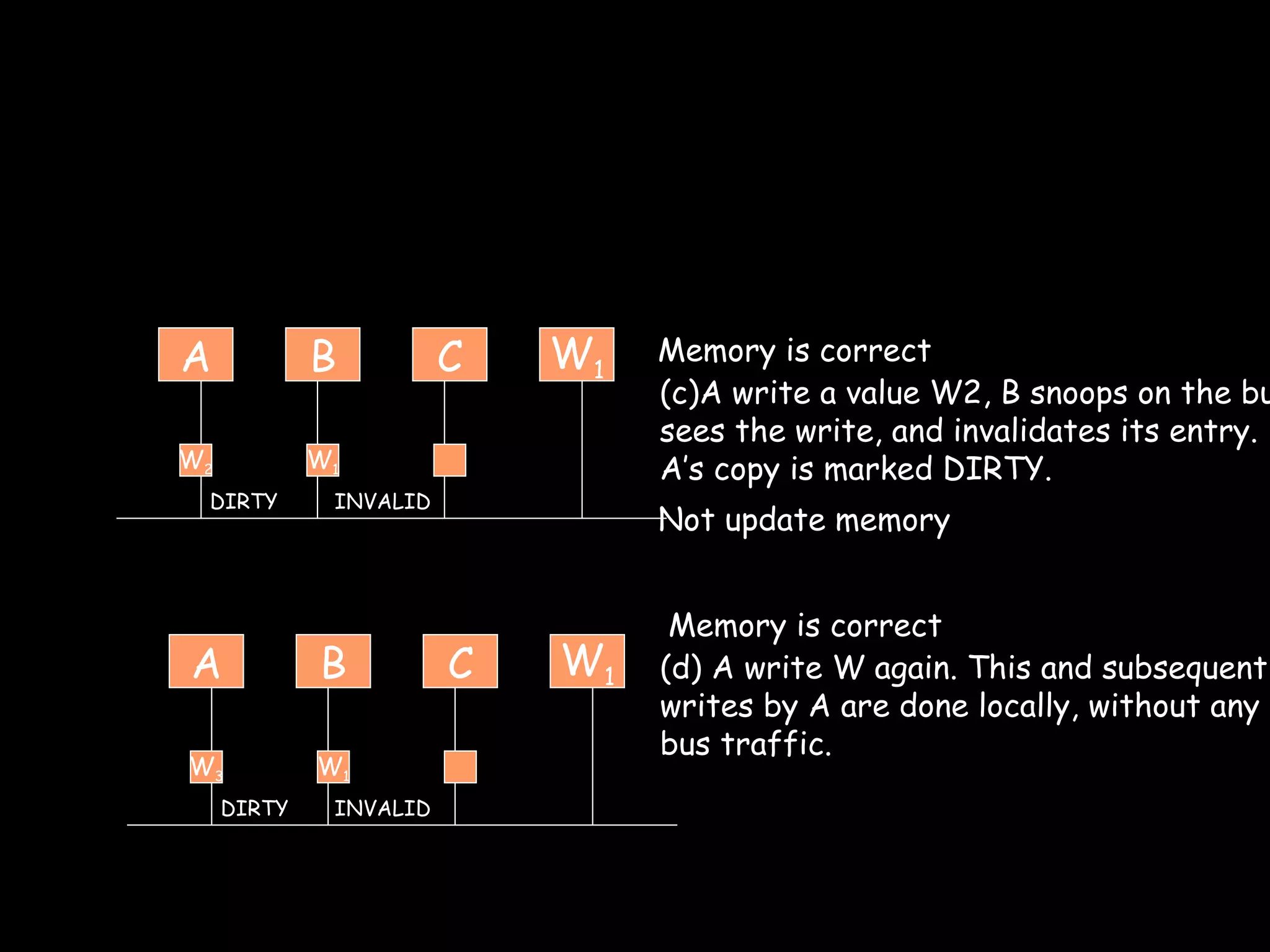
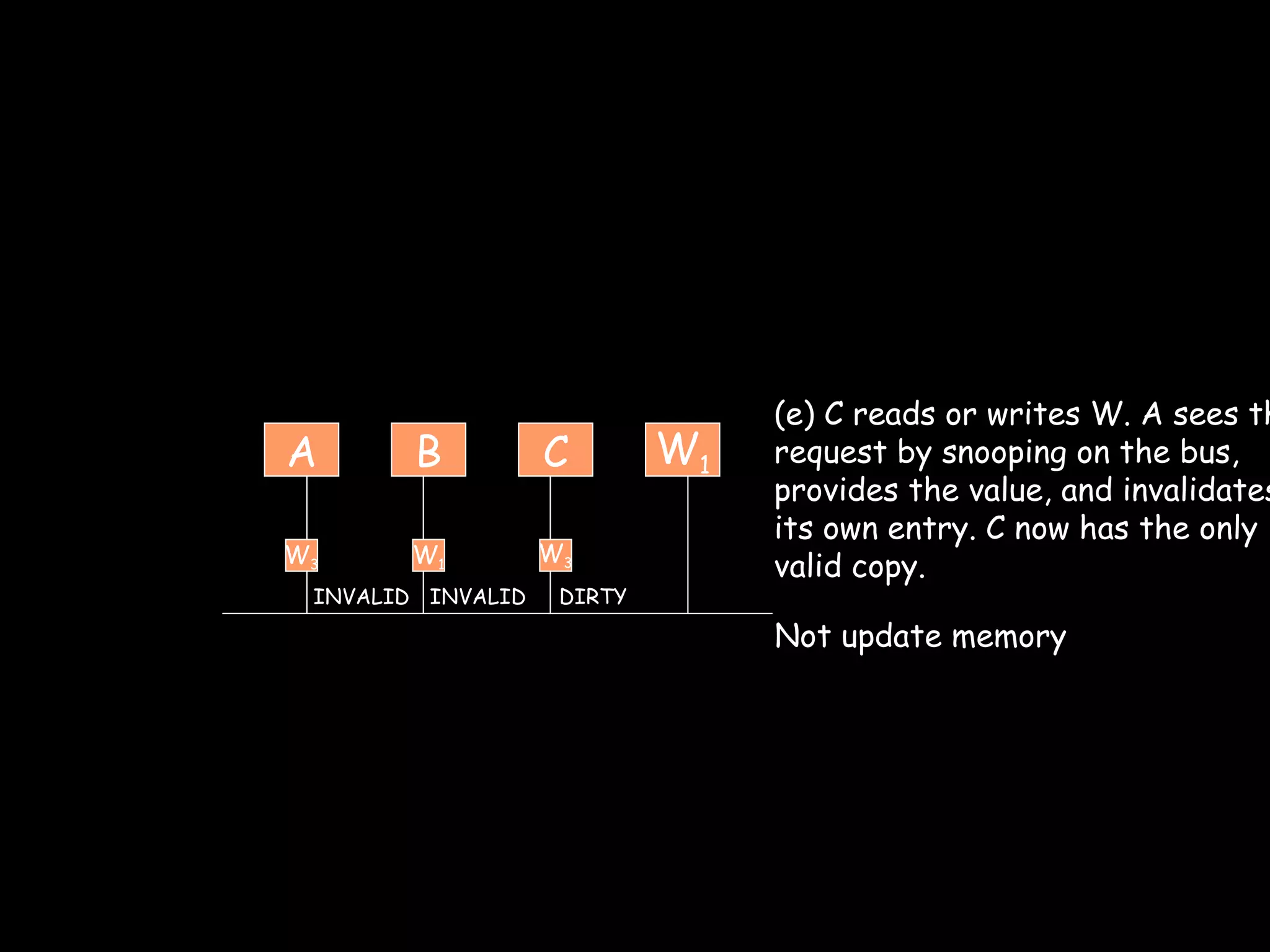
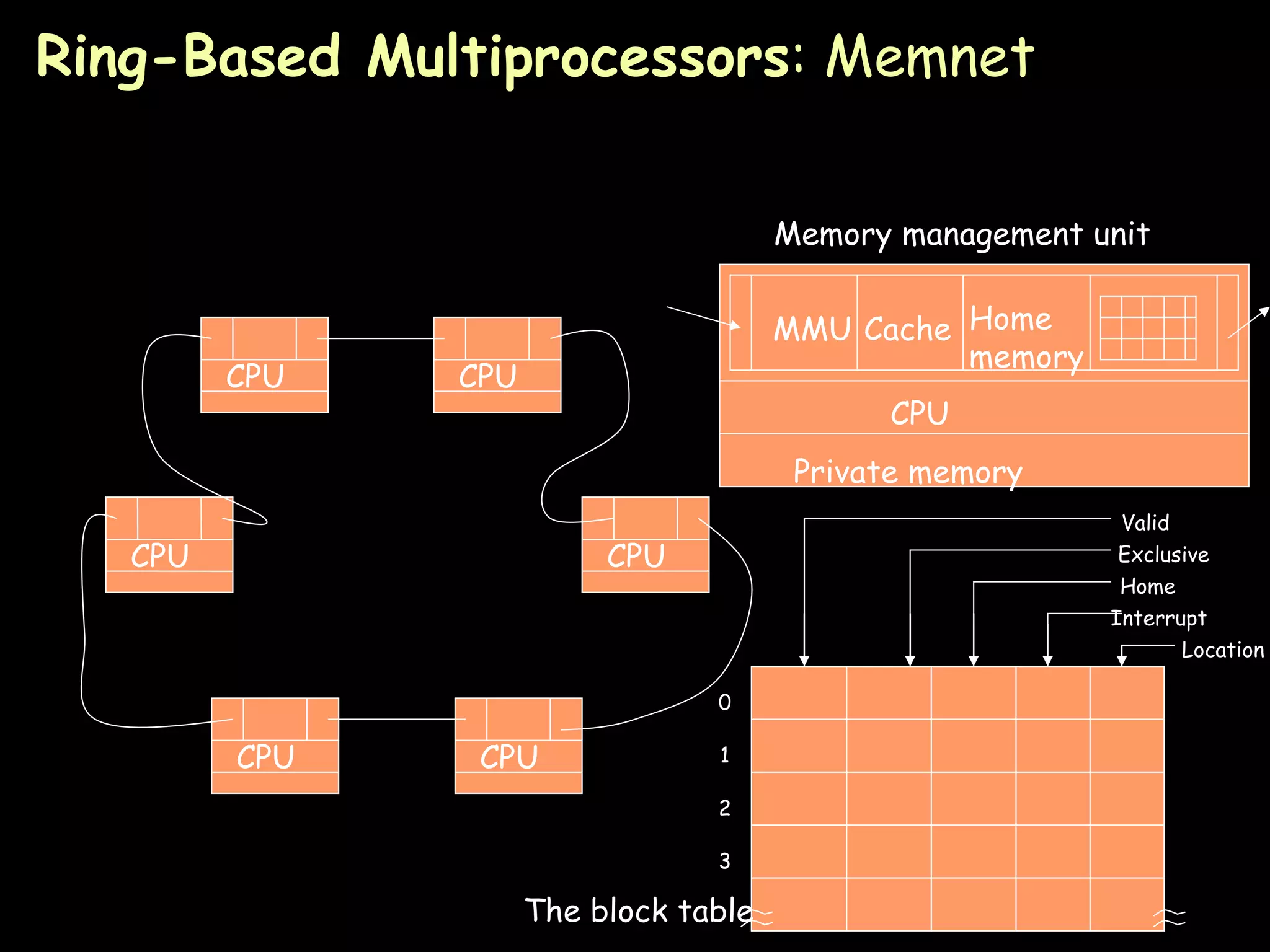
The document provides an overview of shared memory architectures, including distributed shared memory (DSM) systems, shared memory, and different architectures like on-chip memory, bus-based multiprocessors, and ring-based multiprocessors. It discusses topics like cache coherence protocols, read and write operations, and similarities and differences between bus-based and ring-based multiprocessors.