





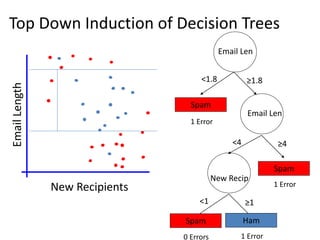
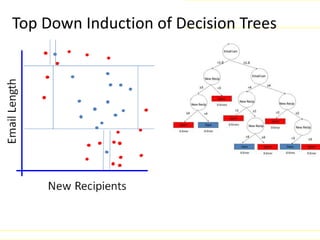

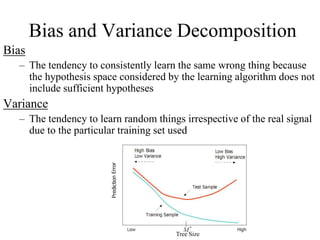

![Random decision forests [74]-1995-
-1996-
-1997-
-1998-
-1999-
-2000-
-2001-
-2002-
-2003-
-2004-
-2005-
-2006-
AdaBoost [33]
Bagging [72]
Random Subspace [99]
Random Forest [73]
Extremely Randomized Trees [2]
Rotation Forest [99]
Gradient Boosted Trees [84]
Iterative Methods Non-Iterative Methods](https://image.slidesharecdn.com/dmbitalk-150712172913-lva1-app6892/85/Decision-Forest-Twenty-Years-of-Research-16-320.jpg)


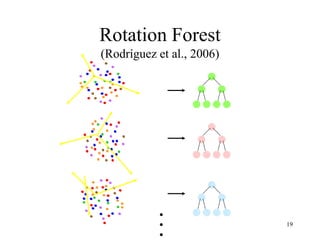
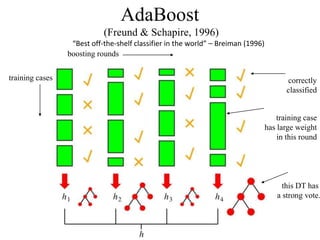



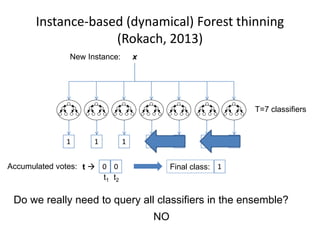
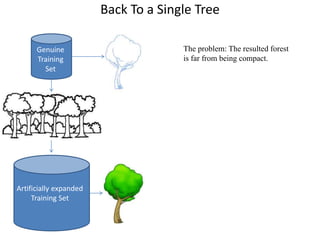




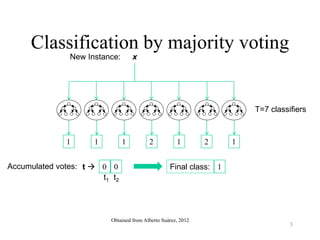
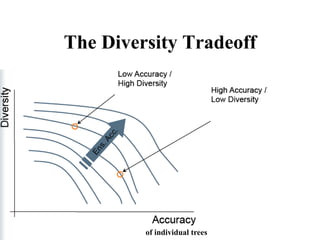
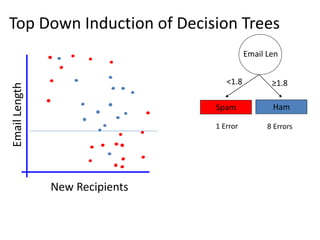
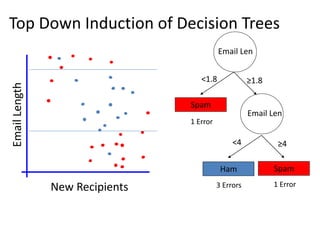
The document discusses the effectiveness of decision forests, highlighting that random forests can achieve high classification accuracy through majority voting among multiple classifiers. It emphasizes the importance of diversity, independence, decentralization, and aggregation in crowds to improve decision-making quality. Additionally, it addresses the challenges of model complexity and performance optimization through methods like forest thinning and the application of decision forests beyond traditional classification tasks.

































































